Jacquemontia yellow vein virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_004788095.1 |
| Isolate |
Venezuela: Zulia |
| Release date |
2019/6/28 |
| Submitter |
Fiallo-Olive,E., Chirinos,D.T., Geraud-Pouey,F., Navas-Castillo,J. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
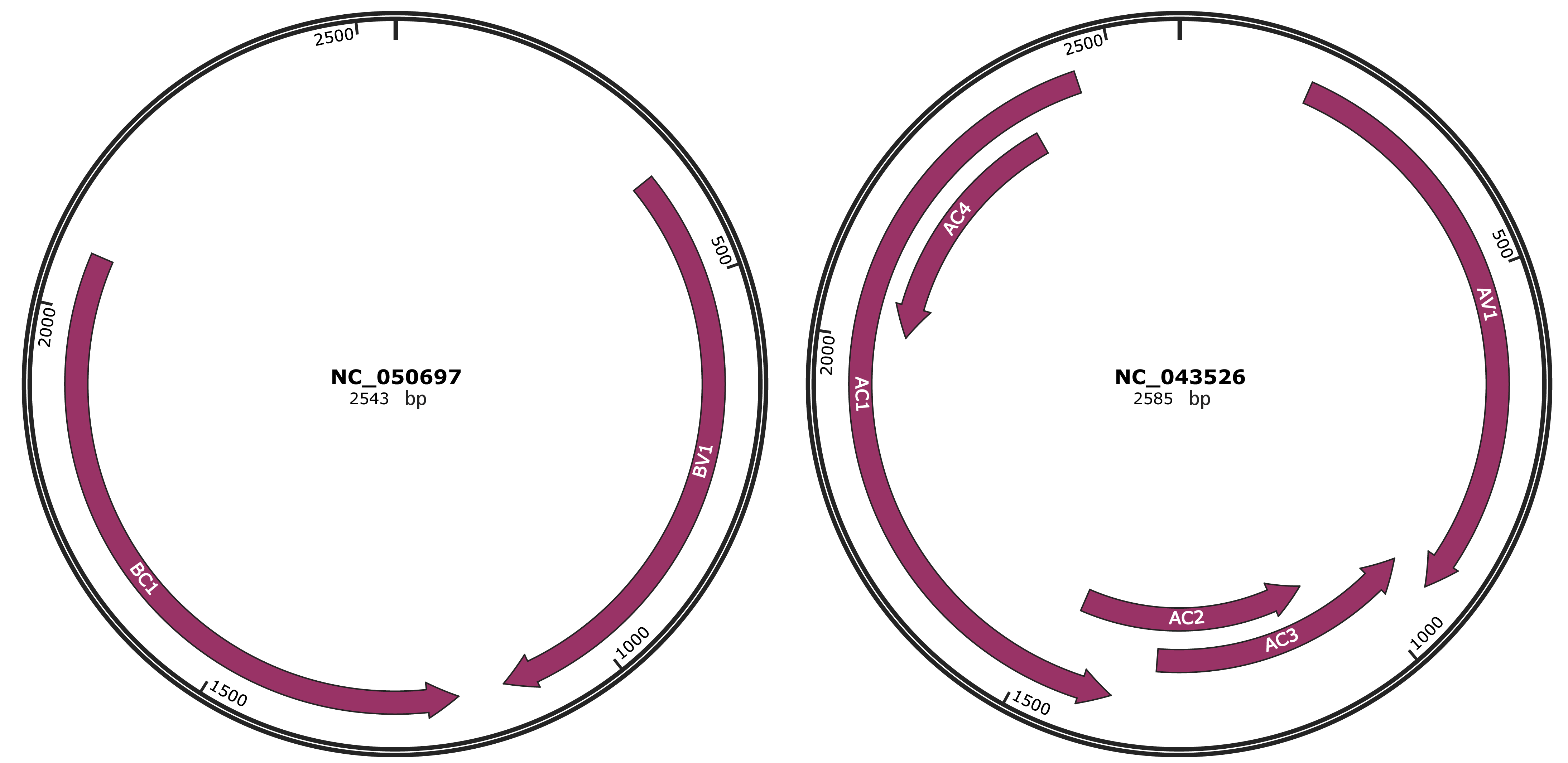
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTTTCCCCTGGCCCACGCTCTGACAGTTGTGGAGCACTAATGATTTACTTTGTTGTATTGGAAGACGTGGCTCTCTCTCCGCTCCCTCTCAACGTTAGTGGTGCGTTTTCCTAGGCGGAGTTACTGTATTTTGAATTTCGAATTGCAACCCGCTTGATCTACAGTGTGTATGTACGGCGTGTAATACGTGGCTGATTCTGGTCCATGCTGGTTATTCATTATATATTTTGTCTTCAACTTCTGGCTTCTATATATTGCCAATGGTTTTAATGTGTTTTGCAACCACGTTTGATTTGCTATATATGTTATATTTACTTTGCTAAATCTTGTTGTTTTATGATGTATCCTTCTACTCGTAAACGTGGTTACTCATATGTTCAGCGCTCCTATTATTCTCGTAATTATCCTGTTAAGCGTCAAATGATTAGCAAACGGCTAGATGGCAAACGGAGGCCTAATAATTCCAATAAGGCCCATGATGAGCCTAAAATGATGGCCCAACGCATACAGGAGAATCAATATGGGCCTGAATATGCCTTGGCCCATAATGCGGCTGTTTCAACATATATCAGCTATCCTTGTATGGGTGGTGTCCTCCCCAACCGTTTGCGCTCTTATATAAAATTGAAACGCCTACGTTTTAAAGGGACAGTGAAGATTGAGCGTGTACTGCCTGACATGAACATTGACTCTTCTATGTCCAAGGTGGAAGGGGTATTCTCTCTTGTAATTGTTGTGGATCGTAAACCTCACATGAATGCATCTGGTTGCCTGCACACATTTGATGAACTATTTGGTGCAAGGATCCATAGTCTGGGTAATTTAGCAGTTACTCCCTCTTTGAAGGACCGCTTCTACATTCGCTACGTATTGAAACGCGTTTTGTCCGTGGAGAAGGAAACTGCTATGGTGGACATTGAAGGAAGTACCGCTCTCTCTAATAGGCGTTATAGTATGTGGTCTAGTTTTAAGGACTATGACCGTGAATCATGTAAGGGCGGATATGATAATATGAACAAGAACGCCCTATTAGTTTATTATTGCTGGATGTCTGATGTAATGTCTAAGGCAACCACCTTTGTAACGTTTGATCTTGACTATATTGGCTGAATAAGAATAAAGTGTTTTCAACCATGTGTATTGAATAGCATAATATTGAACAAACACGTTTACTGTAATGATTTTGCCTGAGATGGTGTACAATTTGTCTTGATACATTCATGTACCGTGTTCCTAACTATCTCGTTTAATTGGGCCATGGACATTGTTATATTGGATTCTGATCTTTGGGCTCCCACCACTGAAGCTGACTCTCCTGGGTCCAATACACTACTCCCTAGTCTGTGGAGGTGTCTGTATGGATGCAGGTTGTTCAGTACTTCCGAAGTGGTATCTGATGTGTTGCCTCCTAATGCACTCCTTGAAGCCCAGGACTCACCAGGTCTAATCTCCATTTGTTGTGTGACTCCAATCCTGGACATGGAGGTGCATCTGATGAGTTTCCTCTCAGTCCTTCCGTAATTGACATGGTAGAAGTCCACATCCTTGTCTGTGAATTGGTTGGATAAGATCTTGATTGTAGGTGCTCTGAATGGGATATCAACAGAATGTTTTGCAGTGGATAGCTTCAATTTTCCCTTAAATTTGGCAAAATGAGTCCTCTGATGAACATTACTGTCACACACCCTGTAATACAGTCTCCATGGCACTGGATCTTTGAGTGAGAAGAATGAGGATGAGAAAAAGTGGAGATCGATGTTGCATCTGATCGGAAATGTCCATGATGCTTGTAGTGATTCGTTGTTTGTCATCCTCTGATCATGGATCTCCACTAACACGGTACCCGCTGCGTTAATTGGGACCTGTTGTCTGTATTCTACTATGACGTGGTCTATTTTCATACAGCTGCCCCTTAGTCTAGCGCCTAATTGTGAAGCTGTTGATGGAAATTGCAATATTATCTCAGTTAGGTCATGAGATAACTGGTATTCTTCACGATGAGATTCTATATAATTGAACGTGGAAGGATGATTAGCTACTTGGGAATCCATATGGTGGAGCTCTGGCCGCGCAGCGGAATTGCTTCAAGAAGATTTGTGCTTGTGAGACGATGAGTCAGATACTTTTGAAGAAGATATGTGCCTTTGCTCTCAGATGCAGATCCTAGAGAAGAATTCCTGAAAATTCACCCAAATATCCAGGCAGCCAAGGACACCAACGCCGTCAAGAATTATGATGAATAAGAGGTAATTTTCTTCAATGTTAATGGTTCTTAAAGAAAGAGTAAAGTGTTTTTGAAGAAGAATGGAATGGTTTTGAGCTAGATCTGCTTGTGTATTTATAACTGGAAATGTTTAGCTGAAGCTGCATAATTTCATCTGGATGGCATTTTTGTAATAATGATAGGGGACTCCAGAGGAGCTCTCGTCTAAAACCTATTGTTGTTGGAGTCCTGGAGTCCCATTTATACTAAAACCCTTTGGGGGACTCCAGGGGCAAAAGCGGCCATCCGAAATAATATT
ACCGGATGGCCGCGCGATTTTTTCCCCCGGGCCCACGTACTGACTAAAGATATGACCGTCCAATGATAGTGCGCCTGGCGAGCGTAATTATTGATCCTTGGGCCCCAAGAATGGGCACGTTTTTCTATAAATGTGAGTTGGACGGTGTTTAGTGGCTCACTTTAATTTGAAATGCCCAAGCGGGATGCCCCATGGCGCTCCCACCCTGGGACCTCCAAGGTGAGCCGCAATTTGAGGTACTCCTCGCCCCGTGGTGGTCTGGGCCCAAATTATGATAAGGCCCAAGCCTGGGTGAACAGGCCCATGTACAGAAAGCCCAGGATCTACCGTTTGATGAGAGGCCCAGACGTCCCCAAGGGCTGTGAAGGCCCATGTAAGGTGCAATCCTTTGAGCAGCGTCACGATGTCTCCCATGTTGGCAAGGTGATCTGCATATCTGATGTTACCCGTGGCAACGGTATCACCCACCGTGTTGGTAAGCGCTTCTGTGTCAAGTCTGTCTATATTATGGGCAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACCAACAGCGTCATGTTCTGGCTTGTGAGGGATAGGAGACCCTATGGTACTCCCATGGACTTCGGCCAGGTGTTCAACATGTACGACAACGAGCCCAGTACTGCCACCGTGAAGAACGATCTTCGTGATCGGTATCAGGTTATGCACAGGTTCTACGCTAAGGTCACTGGTGGGCAGTATGCCAGCAATGAGCAGGCTCTGGTTAGACGGTTCTGGAGAGTGAACAACCACGTGGTGTACAACCACCAGGAAGCCGGGAAGTACGAGAACCACACAGAGAACGCCCTATTATTGTATATGGCATGTACCCATGCCTCTAACCCCGTGTATGCTACATTGAAGATTCGGATCTATTTTTATGATTCGATAATGAATTAATAAATTTTGAATTTTATTGAATGGCGTTCTATTACATGATTTACATACGGTTTGTCTGTTGCGAATCGAACAGCTCTAATGACATTGTTAATTGAAATAACCCCTAATCTGTCTAAGTACAACATTACTAAATGCCTAAACCTAGCTAAATATGTCGTCCCAGAAGCTGTCACTGATGTCGTCCAGATTTGGAAGGTCAGGAACGCCTTGTGTAGATCCAGCGCCCTCCTCAGGTTGTGGTTGAACCTGATCTGGACTGTGTATATCCTTGTCGCTATGTATGGCAGGTCCTCTAGGTTGTATATCTTGAAATAGAGGGGATTTGGTACCCTCCAGATATACTCTCCACTCCTTGCCTGAAGAGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGGTTCCTGCAGTTTATGGAGATGTATATTGAACAACCGCAGTCCAAGTCTATTCTCCTACGCCTGACTGCCCTCTTCTTGGCAATCCTGTGTTTGGGTTCGATAGAGGGGGGCGTCGAGGAAGACGAATTTTGCATTGTGTAGTGTCCACCTCTTGAGTGAAGAGTTTTCTTCCTTCTCTAGGAACTCTTTATAGGACGTCCCCTCTCCAGGATTGCATAGTACGATTGACGGGATACCACCTTTAATTTGAACTGGCTTGCCGTATTTACAGTTGGATTGCCAGTCCTTCTGGGCCCCTATCAATTCTTTCCAGTGCTTTAGCTTTAGGTATTGCGGACTGATGTCATCAATGACGTTATACTCAGCACTGTTTGAGTAAACCCTAGAATTGAAGTCCAGATGACCACTCAGATAGTTATGGCATCCTAGTGCACGAGCCCACATTGTTTTGCCCGTACGTGAATCGCCTTCTATGATGATACTGATAGGTCTTTCTGGCCGCGCAGCGCGATCAGTTCCAAAATAATGATCAGCCCACTCTTGCATACCTTCTGGGACGTTATTAAAGGATGACATTGGAAATGGTGGAGACCATGGTTGAGGGGGTTTTTGGAAGAGGCGCTCGATGTTAGCCTTTACGTTATGGTAGCTAACGATGAATGTCCTTGGATCTCCGGCTTTTATAATGTCGAGAGCCTCTCCCGCACTAGATGCATTGACAGCGTTGTGGTAGACGTCGTCTTTGTTTGACTTTGTTCCCCCAGACACCTTGTACAGTCCGGATTCACAATAATCACCTTCTTTGGTGATGTAATTCTTGACGGCGTTGGTGTCTTTGGCTGCCTGGATATTTGGGTGAAAATTGGCAGACCTTCTTGGGTGAGTGAGGTCGAAAAATCTAGCATCCTTGATGTTGGACTTCCCCGATAGTTGGATGAGGCAGTGTAAGTGAGGGAACCCATCGGCATGTTCCTCTCTGGCGACTCTGATGTATGTGGGTTTGACAATTGACCATGGTAGGGATTGAAGCATCTGAATAGCTTCATCTTTTTGTATATCACACTGAGGATATGTTAAGAATATATTTCTGGCTTGGAGACGAAATGAATTTGGGTTTCGGGGCATATTTGCAAATATTTTATGGGACTCCAGAGGATGCTCTCAACTTCTGTGCTATTTGGTGGAGTCCTGGAGTCCCATTTATACTAAAAGCCTCTGGGGGACTCCAGGGGCAAAAGCGGCCATCCGCAATAATATT
Gene Information
|
NCBI Accession
|
YP_009927291.1
|
|
Location
|
361-1131 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATCCTTCTACTCGTAAACGTGGTTACTCATATGTTCAGCGCTCCTATTATTCTCGTAATTATCCTGTTAAGCGTCAAATGATTAGCAAACGGCTAGATGGCAAACGGAGGCCTAATAATTCCAATAAGGCCCATGATGAGCCTAAAATGATGGCCCAACGCATACAGGAGAATCAATATGGGCCTGAATATGCCTTGGCCCATAATGCGGCTGTTTCAACATATATCAGCTATCCTTGTATGGGTGGTGTCCTCCCCAACCGTTTGCGCTCTTATATAAAATTGAAACGCCTACGTTTTAAAGGGACAGTGAAGATTGAGCGTGTACTGCCTGACATGAACATTGACTCTTCTATGTCCAAGGTGGAAGGGGTATTCTCTCTTGTAATTGTTGTGGATCGTAAACCTCACATGAATGCATCTGGTTGCCTGCACACATTTGATGAACTATTTGGTGCAAGGATCCATAGTCTGGGTAATTTAGCAGTTACTCCCTCTTTGAAGGACCGCTTCTACATTCGCTACGTATTGAAACGCGTTTTGTCCGTGGAGAAGGAAACTGCTATGGTGGACATTGAAGGAAGTACCGCTCTCTCTAATAGGCGTTATAGTATGTGGTCTAGTTTTAAGGACTATGACCGTGAATCATGTAAGGGCGGATATGATAATATGAACAAGAACGCCCTATTAGTTTATTATTGCTGGATGTCTGATGTAATGTCTAAGGCAACCACCTTTGTAACGTTTGATCTTGACTATATTGGCTGA |
|
Protein Sequence
|
MYPSTRKRGYSYVQRSYYSRNYPVKRQMISKRLDGKRRPNNSNKAHDEPKMMAQRIQENQYGPEYALAHNAAVSTYISYPCMGGVLPNRLRSYIKLKRLRFKGTVKIERVLPDMNIDSSMSKVEGVFSLVIVVDRKPHMNASGCLHTFDELFGARIHSLGNLAVTPSLKDRFYIRYVLKRVLSVEKETAMVDIEGSTALSNRRYSMWSSFKDYDRESCKGGYDNMNKNALLVYYCWMSDVMSKATTFVTFDLDYIG |
|
NCBI Accession
|
YP_009927292.1
|
|
Location
|
1191-2072 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCCCAAGTAGCTAATCATCCTTCCACGTTCAATTATATAGAATCTCATCGTGAAGAATACCAGTTATCTCATGACCTAACTGAGATAATATTGCAATTTCCATCAACAGCTTCACAATTAGGCGCTAGACTAAGGGGCAGCTGTATGAAAATAGACCACGTCATAGTAGAATACAGACAACAGGTCCCAATTAACGCAGCGGGTACCGTGTTAGTGGAGATCCATGATCAGAGGATGACAAACAACGAATCACTACAAGCATCATGGACATTTCCGATCAGATGCAACATCGATCTCCACTTTTTCTCATCCTCATTCTTCTCACTCAAAGATCCAGTGCCATGGAGACTGTATTACAGGGTGTGTGACAGTAATGTTCATCAGAGGACTCATTTTGCCAAATTTAAGGGAAAATTGAAGCTATCCACTGCAAAACATTCTGTTGATATCCCATTCAGAGCACCTACAATCAAGATCTTATCCAACCAATTCACAGACAAGGATGTGGACTTCTACCATGTCAATTACGGAAGGACTGAGAGGAAACTCATCAGATGCACCTCCATGTCCAGGATTGGAGTCACACAACAAATGGAGATTAGACCTGGTGAGTCCTGGGCTTCAAGGAGTGCATTAGGAGGCAACACATCAGATACCACTTCGGAAGTACTGAACAACCTGCATCCATACAGACACCTCCACAGACTAGGGAGTAGTGTATTGGACCCAGGAGAGTCAGCTTCAGTGGTGGGAGCCCAAAGATCAGAATCCAATATAACAATGTCCATGGCCCAATTAAACGAGATAGTTAGGAACACGGTACATGAATGTATCAAGACAAATTGTACACCATCTCAGGCAAAATCATTACAGTAA |
|
Protein Sequence
|
MDSQVANHPSTFNYIESHREEYQLSHDLTEIILQFPSTASQLGARLRGSCMKIDHVIVEYRQQVPINAAGTVLVEIHDQRMTNNESLQASWTFPIRCNIDLHFFSSSFFSLKDPVPWRLYYRVCDSNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTIKILSNQFTDKDVDFYHVNYGRTERKLIRCTSMSRIGVTQQMEIRPGESWASRSALGGNTSDTTSEVLNNLHPYRHLHRLGSSVLDPGESASVVGAQRSESNITMSMAQLNEIVRNTVHECIKTNCTPSQAKSLQ |
|
NCBI Accession
|
YP_009666517.1
|
|
Location
|
172-930 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCCAAGCGGGATGCCCCATGGCGCTCCCACCCTGGGACCTCCAAGGTGAGCCGCAATTTGAGGTACTCCTCGCCCCGTGGTGGTCTGGGCCCAAATTATGATAAGGCCCAAGCCTGGGTGAACAGGCCCATGTACAGAAAGCCCAGGATCTACCGTTTGATGAGAGGCCCAGACGTCCCCAAGGGCTGTGAAGGCCCATGTAAGGTGCAATCCTTTGAGCAGCGTCACGATGTCTCCCATGTTGGCAAGGTGATCTGCATATCTGATGTTACCCGTGGCAACGGTATCACCCACCGTGTTGGTAAGCGCTTCTGTGTCAAGTCTGTCTATATTATGGGCAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACCAACAGCGTCATGTTCTGGCTTGTGAGGGATAGGAGACCCTATGGTACTCCCATGGACTTCGGCCAGGTGTTCAACATGTACGACAACGAGCCCAGTACTGCCACCGTGAAGAACGATCTTCGTGATCGGTATCAGGTTATGCACAGGTTCTACGCTAAGGTCACTGGTGGGCAGTATGCCAGCAATGAGCAGGCTCTGGTTAGACGGTTCTGGAGAGTGAACAACCACGTGGTGTACAACCACCAGGAAGCCGGGAAGTACGAGAACCACACAGAGAACGCCCTATTATTGTATATGGCATGTACCCATGCCTCTAACCCCGTGTATGCTACATTGAAGATTCGGATCTATTTTTATGATTCGATAATGAATTAA |
|
Protein Sequence
|
MPKRDAPWRSHPGTSKVSRNLRYSSPRGGLGPNYDKAQAWVNRPMYRKPRIYRLMRGPDVPKGCEGPCKVQSFEQRHDVSHVGKVICISDVTRGNGITHRVGKRFCVKSVYIMGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRYQVMHRFYAKVTGGQYASNEQALVRRFWRVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_009666518.1
|
|
Location
|
927-1325 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCTCTTCAGGCAAGGAGTGGAGAGTATATCTGGAGGGTACCAAATCCCCTCTATTTCAAGATATACAACCTAGAGGACCTGCCATACATAGCGACAAGGATATACACAGTCCAGATCAGGTTCAACCACAACCTGAGGAGGGCGCTGGATCTACACAAGGCGTTCCTGACCTTCCAAATCTGGACGACATCAGTGACAGCTTCTGGGACGACATATTTAGCTAGGTTTAGGCATTTAGTAATGTTGTACTTAGACAGATTAGGGGTTATTTCAATTAACAATGTCATTAGAGCTGTTCGATTCGCAACAGACAAACCGTATGTAAATCATGTAATAGAACGCCATTCAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGEPITALQARSGEYIWRVPNPLYFKIYNLEDLPYIATRIYTVQIRFNHNLRRALDLHKAFLTFQIWTTSVTASGTTYLARFRHLVMLYLDRLGVISINNVIRAVRFATDKPYVNHVIERHSIKFKIY |
|
NCBI Accession
|
YP_009666519.1
|
|
Location
|
1072-1461 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator |
|
Coding Region
|
ATGCAAAATTCGTCTTCCTCGACGCCCCCCTCTATCGAACCCAAACACAGGATTGCCAAGAAGAGGGCAGTCAGGCGTAGGAGAATAGACTTGGACTGCGGTTGTTCAATATACATCTCCATAAACTGCAGGAACCATGGATTCACGCACAGGGGAACCCATCACTGCTCTTCAGGCAAGGAGTGGAGAGTATATCTGGAGGGTACCAAATCCCCTCTATTTCAAGATATACAACCTAGAGGACCTGCCATACATAGCGACAAGGATATACACAGTCCAGATCAGGTTCAACCACAACCTGAGGAGGGCGCTGGATCTACACAAGGCGTTCCTGACCTTCCAAATCTGGACGACATCAGTGACAGCTTCTGGGACGACATATTTAGCTAG |
|
Protein Sequence
|
MQNSSSSTPPSIEPKHRIAKKRAVRRRRIDLDCGCSIYISINCRNHGFTHRGTHHCSSGKEWRVYLEGTKSPLFQDIQPRGPAIHSDKDIHSPDQVQPQPEEGAGSTQGVPDLPNLDDISDSFWDDIFS |
|
NCBI Accession
|
YP_009666520.1
|
|
Location
|
1382-2452 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCCCGAAACCCAAATTCATTTCGTCTCCAAGCCAGAAATATATTCTTAACATATCCTCAGTGTGATATACAAAAAGATGAAGCTATTCAGATGCTTCAATCCCTACCATGGTCAATTGTCAAACCCACATACATCAGAGTCGCCAGAGAGGAACATGCCGATGGGTTCCCTCACTTACACTGCCTCATCCAACTATCGGGGAAGTCCAACATCAAGGATGCTAGATTTTTCGACCTCACTCACCCAAGAAGGTCTGCCAATTTTCACCCAAATATCCAGGCAGCCAAAGACACCAACGCCGTCAAGAATTACATCACCAAAGAAGGTGATTATTGTGAATCCGGACTGTACAAGGTGTCTGGGGGAACAAAGTCAAACAAAGACGACGTCTACCACAACGCTGTCAATGCATCTAGTGCGGGAGAGGCTCTCGACATTATAAAAGCCGGAGATCCAAGGACATTCATCGTTAGCTACCATAACGTAAAGGCTAACATCGAGCGCCTCTTCCAAAAACCCCCTCAACCATGGTCTCCACCATTTCCAATGTCATCCTTTAATAACGTCCCAGAAGGTATGCAAGAGTGGGCTGATCATTATTTTGGAACTGATCGCGCTGCGCGGCCAGAAAGACCTATCAGTATCATCATAGAAGGCGATTCACGTACGGGCAAAACAATGTGGGCTCGTGCACTAGGATGCCATAACTATCTGAGTGGTCATCTGGACTTCAATTCTAGGGTTTACTCAAACAGTGCTGAGTATAACGTCATTGATGACATCAGTCCGCAATACCTAAAGCTAAAGCACTGGAAAGAATTGATAGGGGCCCAGAAGGACTGGCAATCCAACTGTAAATACGGCAAGCCAGTTCAAATTAAAGGTGGTATCCCGTCAATCGTACTATGCAATCCTGGAGAGGGGACGTCCTATAAAGAGTTCCTAGAGAAGGAAGAAAACTCTTCACTCAAGAGGTGGACACTACACAATGCAAAATTCGTCTTCCTCGACGCCCCCCTCTATCGAACCCAAACACAGGATTGCCAAGAAGAGGGCAGTCAGGCGTAG |
|
Protein Sequence
|
MPRNPNSFRLQARNIFLTYPQCDIQKDEAIQMLQSLPWSIVKPTYIRVAREEHADGFPHLHCLIQLSGKSNIKDARFFDLTHPRRSANFHPNIQAAKDTNAVKNYITKEGDYCESGLYKVSGGTKSNKDDVYHNAVNASSAGEALDIIKAGDPRTFIVSYHNVKANIERLFQKPPQPWSPPFPMSSFNNVPEGMQEWADHYFGTDRAARPERPISIIIEGDSRTGKTMWARALGCHNYLSGHLDFNSRVYSNSAEYNVIDDISPQYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGTSYKEFLEKEENSSLKRWTLHNAKFVFLDAPLYRTQTQDCQEEGSQA |
|
NCBI Accession
|
YP_009666521.1
|
|
Location
|
2008-2373 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAAGCTATTCAGATGCTTCAATCCCTACCATGGTCAATTGTCAAACCCACATACATCAGAGTCGCCAGAGAGGAACATGCCGATGGGTTCCCTCACTTACACTGCCTCATCCAACTATCGGGGAAGTCCAACATCAAGGATGCTAGATTTTTCGACCTCACTCACCCAAGAAGGTCTGCCAATTTTCACCCAAATATCCAGGCAGCCAAAGACACCAACGCCGTCAAGAATTACATCACCAAAGAAGGTGATTATTGTGAATCCGGACTGTACAAGGTGTCTGGGGGAACAAAGTCAAACAAAGACGACGTCTACCACAACGCTGTCAATGCATCTAGTGCGGGAGAGGCTCTCGACATTATAA |
|
Protein Sequence
|
MKLFRCFNPYHGQLSNPHTSESPERNMPMGSLTYTASSNYRGSPTSRMLDFSTSLTQEGLPIFTQISRQPKTPTPSRITSPKKVIIVNPDCTRCLGEQSQTKTTSTTTLSMHLVRERLSTL |