Jacquemontia yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_003029025.2 |
| Isolate |
Venezuela |
| Release date |
2018/12/27 |
| Submitter |
Fiallo-Olive,E., Chirinos,D.T., Geraud-Pouey,F., Moriones,E., Navas-Castillo,J. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
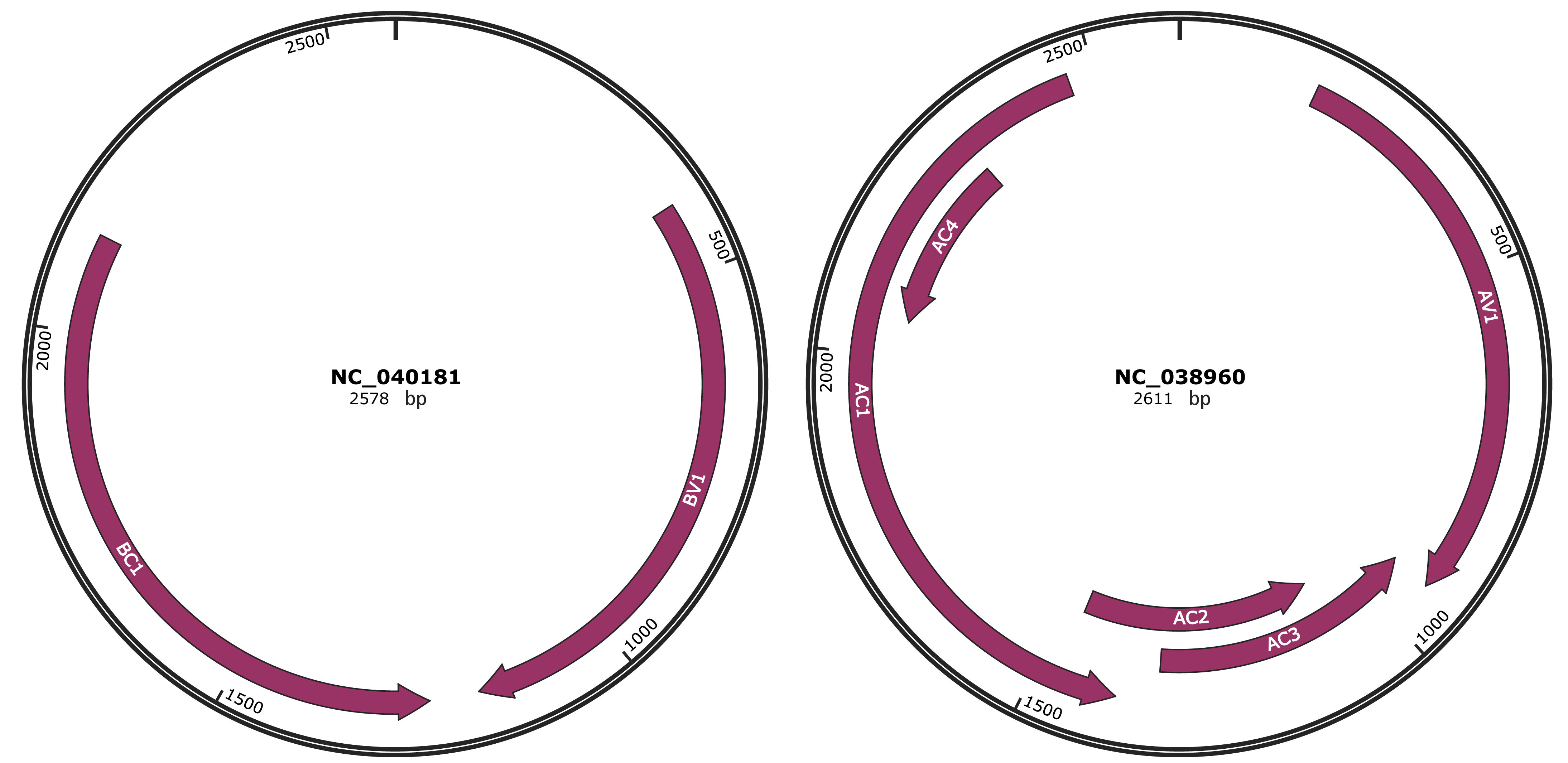
JBrowse
Genome
ACCGGATGGCCGCCCGCCCGCCCCCCTCCGTACATCCCGCTTGAGTAACGGGCCAATGAGGAGCCGCCAGGTGTTGCGCACTAAATGCCCCTTTCTTGGAGTTTGTACCCCGGACACGTGGCGCTCTCTACGCTCTCGCTCATCGCTACTTTAACTGGTGCGTATTTTACTGTGGCGCTAATGGATTTGAAATTTGAATTGGCGTACTGAGAACGCTTTACCAAAATGATAAACGTGGCGTATTTATAACCATAGCGCCCAGTTAATTTAATGTTTATGTTTAGCTGACCTCTTGTATATATTGTTGTTGAATTGTTTATCATTACACATAGGCTTAGCTTACCCCCACGTTTATGCTATTGTATAACAGTGTTTTTGTTAACTGTAATTGATCTATTCACTACTGATAATGTATCCAGTGAGGCATAAACGTGGTTATTCTACTGCTCAGCCACGGTGTTATGCTCGTAATTACAATTATAAGCGATCAGGTCCTGTTAAACGCACTGATGGTAAACGAAAGCCCATTCACTCCAGTAAGGCCCATGATGAGCCCAAGTTGGTGGCCCAGCGCATTCATGAAAATCAATATGGGCCCAATTTTGTCCTGGCCCATAACAACGCTATCTCAACCTACATCAGCCTACCCAGCATTGGAAAGAGCCTACCCAACCGAAGCCGCTCGTATATCAAGTTGAAGCGGTTGCGTTTCAAAGGCACCGTCAAGATTGAACGTGTGCACGGTGATATGCATATTGACAGTGCTTCGCCCAAAGTGGACGGGGTCTTCTCCCTTGTTATCGTTGTGGATCGGAAGCCTCATGTGAATGCATCAGGTGCTCTCCACACATTTGATGAGCTATTCGGTGCTAGGATCCACAGTCATGGCAACTTAGCAGTTGCTCCCTCTTTGAAGGACCGTTTTTACATACGCTATGTGTATAAGCGTGTAATATCTGTGGAGAAGGATAGCACAATGCTGGATGTGGAAGGATCAATGGCCCTCTCTAATAGGCGTTATACAACTTGGTCTAGTTTTAGGGACCATGAACAGGATACATGTACAGGCGTGTATGACAATATTGATAAGAACGCCCTATTAGTATATTATTGCTGGATGTCTGATACTGTTTCAAAGGCATCACCCTATGTATCATTTGATCTTGATTATGTAGGCTGATTACTGAAATCATTGTGTTTATGCATACTTGAACAACTGAATAATGAACGAGAATATATCTTATTTATTGTAATGATTTTGGCTGGGAAGGTTTACAGTTTGTGTTGATACATTCCTGAACGGTACTCCTAACTAACTCGTTTAACTGGGCCATTGACATTGTTATGTTGGACTCACTCCTCTGGGCCGCCGCTACTGATGCGGAGTCTCCTGGATCTAACACGTTGCTACCCAGCCTACTCAGATGTCTGTATGGGTGTAAGTTGTTCAGTACTTCCGAATGCGCATCTGAGCTGCTAGCCCCTATTGTACTGCGTGTAGCCCATGTCTCCCCTGGCCCAATCTGTATTGGCCCTCGCAGCCCTATTCCTGACATGGATGTGCATCTGATAAGCTTTCTCTCCCACCTGCCGTAATCTACGTGGGAGAAATCCACATCCTTCTCTGTGAACTGCTTGGACAGTATCTTGACCGTCGGAGCCTTGAACGGGATATCCACTGAGTGTTTAGCAGTGGACATCTTCAGCTTCCCTTTGAACTTGGCGAAGTGAGTCCTCTGGTGTACATTTGTATCGCATACTCTGTAAAACAGCTTCCACGGAACTTGGTCTTTGAGGGAGAAGAAGGATGACGAGAAAAAATGGAGATCTATGTTGCACCTAATGGGGAATGTCCAGGATGCCTGTAATGATTCGTTGTCTTGCATCCTCATGTCATGGATCTCCACAATTACAGTCCCTGCAGCGTTGATGGGGACCTGCTGCCTGTACTCGATAACACAGTGGTCTATCTTCATACAGCTACGACTCAGCCTAGCTGTTAATTGAGACGCTGCAGAAGGAAATTGAAGAATAATCTCAGTTTGGTCATGAGACAACTGGTATTCCTCACGATGAGATTCAATATAGTTAAAGACGTTAGGTGGATTAGCCAACTGAGATTCCATATAGTGAAATTCTGGCCGCGCTAGCGGCACCTCACGAAGAAGATGAATTGGGACGGAAGTTGAACGGTTTAAAATTGATTAGGGATAGAACAGAATAACGATATTTATGATTAGCAGCAGTTGTGTGAGAGAAATTGCTAAACAAGAACAGATCTCTTGAAGAACTAGGGTTTTGATGAGAGAGGAAGGTGTTGATGTACAATGTTTAGATTTCAATGCTAAGTGCTATTCAGATGAGTGGCTATATATAATGAAGAACTGTCTGTTGTTTAAGGAAGATATGATTTGCAAATCGCCTTGAATGGCATTCTTGTAAATAAGCATGTTCCTCCGTTTGCTCTGCAACGTCAGCATTCTCCATAATCCTATCAATCGGAGGAACTGGGAGAACATTTATACTAGAACCCTCAGTTAAGGATCTCGCTACACGTGGCGGCCATCCGCATAATATT
ACCGGATGGCCGCCCGCCCGCCCCCTTTTCCGCAAATTGCGCTTGGACACATGATTGTTGATAAAGAGGACTAATGAGGAGGCGCCAGCGAAGCTTAGTTAGTGATGCTTGGGCCCAAAGTTTTGGCTCTGCTATCTATAAATGTAAATGTATGGCCCAATAGTGTTTAACTTTAATTTGAAATGCCCAAGCGGGATGCCCCATGGCGCTCTCACCCTGGTACGGCCAAGGTAAGCCGCAATTTGAATTACTCTCCCCGTGGAGGTTATGGGCCCAAATATGATAAGGCCTCTGCTTGGGTTACCCGGCCCATGTATAGGAAGCCCAGGATCTACCGTTTGTACAGAAGCCCAGATGTCCCTAAGGGATGTGAAGGCCCATGTAAGGTCCAGTCCTATGAGCAGCGTCATGACGTCTCCCATGTTGGCAAGGTGATCTGCATATCGGATGTGACCCGCGGCAATGGTCTCACCCACCGTGTTGGTAAGCGGTTCTGTGTTAAGGCCGTCTACATTATGGGCAAGATCTGGATGGACGAGAATATCAAGCTGAAGAACCACACCAACAGCGTCATGTTCTGGTTGGTGAAGGATAGGAGACCCTACGGTACCCCTATGGACTTCGGCCAGGTGTTCAACATGTATGACAACGAGCCGAGTACGGCCACTGTTAAGCAGGATCTCCGTGATCGGTACCAGGTTATGCACCGTTTCTATGGCAAGGTGACCGGTGGTCAGTATGCGATCAATGAGCAGGCTCTTGTTCGGCGTTTCTGGAAGGTGAACAACCACGTTGTGTACAACCACCAGGAAGCCGGGAAGTACGAGAACCACACTGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCGTCTAACCCTGTGTATGCGACCTTGAAAATTCGGATCTATTTTTATGATTCGATAATGAATTAATAAATTTTGAATTTTATTGAATGACGTTCTATTACATGATTGACATACGGTTTGTCTGTGGCGAATCTAACAGCCCTGATTACATTGTTTAACGAAATAATGCCTAACCTATCTAAGTACAACATAACTAAATGCTTAAACCACTCCAAATATGTCGTCCCAGAAGCTGTCAGGGATGTCGTCCAGACTTGGAAGTTCAGGAAGGCCTTGTGTAGATGCAGCGCCCTCCTCAGGTTGTGGTTGAACCTGATCTCGATCGTGTATATCCTGGTCGTTATGTATGGCAGATCCTCTACGTTGTATATCCTGAAATAGAGGGGATTTGGTACCTCCCAGATATACACGCCATTCCTGGCTTGAGGAGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGGTTCCTGCAGTTGAGGTGGACGTATATTGAACAGCCGCAGTCCAAGTCAATTCTCCTACGCCGGACTGCCCTCTTCTTGGCTACCCTGTGTTGAGGTTTGATAGAGGGGGGAGTCGAGGAAGACGAATTCTGCATTGTAAAGGGTCCACCTCTTGAGCGATGCGTTTTCTTCCTTCTCCAGGAAGTCTTTATAAGAGGATCCCTCCCCTGGATTGCATAGTACGATTGAGGGGACCCCGCCTTTAATCATGATTGGCTTTCCGTATTTGCAGTTTGTCTGCCACTGAGTTTGGGCGCCAATGAGATCCTTCCAGTGTTTAAGTTTTAAATAACTAGGGCTTACGTCATCAATGACGTTGTAATCAACATCATCTGAATAGCACTTAGCATTGAAATCTAAATGACCAGCTAAGTAATTGTGTTTACCTAAAGCCCTAGCCCACATTGTTTTACCACACCTTGAATCACCTTCTATGATGATACTCTTGGATCTCAATGGCCGCGCAGCGGGATCCCTTCCAAAATAATTGTCAGCCCACTCTTGAAGAACTTCCGGAACGTTATTGAATGATGACAGAGGAAAAGGAGGAATCCATTGCTCAGGAGGTTTTCTGAATATCCTGGTGGCGTTAGCCACCAGATTATGATATTGGAGGTAATAGTGTGCCGGCTGCTGCTCTTTGATTATCTGGAGGGATTCCTCCATTGTTGACGCATTTAACGCCTTGGCATATGTGTCGTTAGCCGTCTGTTGACCTCCTCTAGCAGATCTCCCGTCAATCTGGAATTCTCCCCATTCAATAACGTCTCCGTCCTTGTCCAGGTAGGACTTGACATCGGAGCTGGATTTAGCTCCCTGTATGTTTGGATGGAAATGTGTTGACCTGTTTGGGGATACAAGGTCGAAGAATCTGTTATTCGTGCAGTTGTATTTACCCTCGAATTGGATAAGCACGTGGAGATGAGGTTCCCCATTCTCGTGAAGCTCTCTGCAGACCTTGATGTATTTCTTGTTTGTTGGGGTTTGGAGATTTTGGATTTGGGAAAGAACGTCCTCCTTTGTAAGAGAACACTGAGGATATGTTAGGAAATAGTTTTTAGCATTTACTGAAAAAGAACCCCTGCGTGGCATTTTTGTAAATAGGAGTGTTCCTCCGAATGCTTATGCCACGTTGGATAGCTCCATAATCCTATCTATCGGAGGAACTGGGAGAACATTTATACTAGAACCTCCGTTTACGGATCTCGACACACGTGGCGGCCATCCGCATAATATT
Gene Information
|
NCBI Accession
|
YP_009547924.1
|
|
Location
|
410-1180 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttling protein |
|
Coding Region
|
ATGTATCCAGTGAGGCATAAACGTGGTTATTCTACTGCTCAGCCACGGTGTTATGCTCGTAATTACAATTATAAGCGATCAGGTCCTGTTAAACGCACTGATGGTAAACGAAAGCCCATTCACTCCAGTAAGGCCCATGATGAGCCCAAGTTGGTGGCCCAGCGCATTCATGAAAATCAATATGGGCCCAATTTTGTCCTGGCCCATAACAACGCTATCTCAACCTACATCAGCCTACCCAGCATTGGAAAGAGCCTACCCAACCGAAGCCGCTCGTATATCAAGTTGAAGCGGTTGCGTTTCAAAGGCACCGTCAAGATTGAACGTGTGCACGGTGATATGCATATTGACAGTGCTTCGCCCAAAGTGGACGGGGTCTTCTCCCTTGTTATCGTTGTGGATCGGAAGCCTCATGTGAATGCATCAGGTGCTCTCCACACATTTGATGAGCTATTCGGTGCTAGGATCCACAGTCATGGCAACTTAGCAGTTGCTCCCTCTTTGAAGGACCGTTTTTACATACGCTATGTGTATAAGCGTGTAATATCTGTGGAGAAGGATAGCACAATGCTGGATGTGGAAGGATCAATGGCCCTCTCTAATAGGCGTTATACAACTTGGTCTAGTTTTAGGGACCATGAACAGGATACATGTACAGGCGTGTATGACAATATTGATAAGAACGCCCTATTAGTATATTATTGCTGGATGTCTGATACTGTTTCAAAGGCATCACCCTATGTATCATTTGATCTTGATTATGTAGGCTGA |
|
Protein Sequence
|
MYPVRHKRGYSTAQPRCYARNYNYKRSGPVKRTDGKRKPIHSSKAHDEPKLVAQRIHENQYGPNFVLAHNNAISTYISLPSIGKSLPNRSRSYIKLKRLRFKGTVKIERVHGDMHIDSASPKVDGVFSLVIVVDRKPHVNASGALHTFDELFGARIHSHGNLAVAPSLKDRFYIRYVYKRVISVEKDSTMLDVEGSMALSNRRYTTWSSFRDHEQDTCTGVYDNIDKNALLVYYCWMSDTVSKASPYVSFDLDYVG |
|
NCBI Accession
|
YP_009547925.1
|
|
Location
|
1245-2126 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCTCAGTTGGCTAATCCACCTAACGTCTTTAACTATATTGAATCTCATCGTGAGGAATACCAGTTGTCTCATGACCAAACTGAGATTATTCTTCAATTTCCTTCTGCAGCGTCTCAATTAACAGCTAGGCTGAGTCGTAGCTGTATGAAGATAGACCACTGTGTTATCGAGTACAGGCAGCAGGTCCCCATCAACGCTGCAGGGACTGTAATTGTGGAGATCCATGACATGAGGATGCAAGACAACGAATCATTACAGGCATCCTGGACATTCCCCATTAGGTGCAACATAGATCTCCATTTTTTCTCGTCATCCTTCTTCTCCCTCAAAGACCAAGTTCCGTGGAAGCTGTTTTACAGAGTATGCGATACAAATGTACACCAGAGGACTCACTTCGCCAAGTTCAAAGGGAAGCTGAAGATGTCCACTGCTAAACACTCAGTGGATATCCCGTTCAAGGCTCCGACGGTCAAGATACTGTCCAAGCAGTTCACAGAGAAGGATGTGGATTTCTCCCACGTAGATTACGGCAGGTGGGAGAGAAAGCTTATCAGATGCACATCCATGTCAGGAATAGGGCTGCGAGGGCCAATACAGATTGGGCCAGGGGAGACATGGGCTACACGCAGTACAATAGGGGCTAGCAGCTCAGATGCGCATTCGGAAGTACTGAACAACTTACACCCATACAGACATCTGAGTAGGCTGGGTAGCAACGTGTTAGATCCAGGAGACTCCGCATCAGTAGCGGCGGCCCAGAGGAGTGAGTCCAACATAACAATGTCAATGGCCCAGTTAAACGAGTTAGTTAGGAGTACCGTTCAGGAATGTATCAACACAAACTGTAAACCTTCCCAGCCAAAATCATTACAATAA |
|
Protein Sequence
|
MESQLANPPNVFNYIESHREEYQLSHDQTEIILQFPSAASQLTARLSRSCMKIDHCVIEYRQQVPINAAGTVIVEIHDMRMQDNESLQASWTFPIRCNIDLHFFSSSFFSLKDQVPWKLFYRVCDTNVHQRTHFAKFKGKLKMSTAKHSVDIPFKAPTVKILSKQFTEKDVDFSHVDYGRWERKLIRCTSMSGIGLRGPIQIGPGETWATRSTIGASSSDAHSEVLNNLHPYRHLSRLGSNVLDPGDSASVAAAQRSESNITMSMAQLNELVRSTVQECINTNCKPSQPKSLQ |
|
NCBI Accession
|
YP_009508293.1
|
|
Location
|
183-938 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCCAAGCGGGATGCCCCATGGCGCTCTCACCCTGGTACGGCCAAGGTAAGCCGCAATTTGAATTACTCTCCCCGTGGAGGTTATGGGCCCAAATATGATAAGGCCTCTGCTTGGGTTACCCGGCCCATGTATAGGAAGCCCAGGATCTACCGTTTGTACAGAAGCCCAGATGTCCCTAAGGGATGTGAAGGCCCATGTAAGGTCCAGTCCTATGAGCAGCGTCATGACGTCTCCCATGTTGGCAAGGTGATCTGCATATCGGATGTGACCCGCGGCAATGGTCTCACCCACCGTGTTGGTAAGCGGTTCTGTGTTAAGGCCGTCTACATTATGGGCAAGATCTGGATGGACGAGAATATCAAGCTGAAGAACCACACCAACAGCGTCATGTTCTGGTTGGTGAAGGATAGGAGACCCTACGGTACCCCTATGGACTTCGGCCAGGTGTTCAACATGTATGACAACGAGCCGAGTACGGCCACTGTTAAGCAGGATCTCCGTGATCGGTACCAGGTTATGCACCGTTTCTATGGCAAGGTGACCGGTGGTCAGTATGCGATCAATGAGCAGGCTCTTGTTCGGCGTTTCTGGAAGGTGAACAACCACGTTGTGTACAACCACCAGGAAGCCGGGAAGTACGAGAACCACACTGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCGTCTAACCCTGTGTATGCGACCTTGAAAATTCGGATCTATTTTTATGATTCGATAATGAATTAA |
|
Protein Sequence
|
MPKRDAPWRSHPGTAKVSRNLNYSPRGGYGPKYDKASAWVTRPMYRKPRIYRLYRSPDVPKGCEGPCKVQSYEQRHDVSHVGKVICISDVTRGNGLTHRVGKRFCVKAVYIMGKIWMDENIKLKNHTNSVMFWLVKDRRPYGTPMDFGQVFNMYDNEPSTATVKQDLRDRYQVMHRFYGKVTGGQYAINEQALVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_009508294.1
|
|
Location
|
935-1333 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCTCCTCAAGCCAGGAATGGCGTGTATATCTGGGAGGTACCAAATCCCCTCTATTTCAGGATATACAACGTAGAGGATCTGCCATACATAACGACCAGGATATACACGATCGAGATCAGGTTCAACCACAACCTGAGGAGGGCGCTGCATCTACACAAGGCCTTCCTGAACTTCCAAGTCTGGACGACATCCCTGACAGCTTCTGGGACGACATATTTGGAGTGGTTTAAGCATTTAGTTATGTTGTACTTAGATAGGTTAGGCATTATTTCGTTAAACAATGTAATCAGGGCTGTTAGATTCGCCACAGACAAACCGTATGTCAATCATGTAATAGAACGTCATTCAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAPQARNGVYIWEVPNPLYFRIYNVEDLPYITTRIYTIEIRFNHNLRRALHLHKAFLNFQVWTTSLTASGTTYLEWFKHLVMLYLDRLGIISLNNVIRAVRFATDKPYVNHVIERHSIKFKIY |
|
NCBI Accession
|
YP_009508295.1
|
|
Location
|
1074-1469 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCAGAATTCGTCTTCCTCGACTCCCCCCTCTATCAAACCTCAACACAGGGTAGCCAAGAAGAGGGCAGTCCGGCGTAGGAGAATTGACTTGGACTGCGGCTGTTCAATATACGTCCACCTCAACTGCAGGAACCATGGATTCACGCACAGGGGAACCCATCACTGCTCCTCAAGCCAGGAATGGCGTGTATATCTGGGAGGTACCAAATCCCCTCTATTTCAGGATATACAACGTAGAGGATCTGCCATACATAACGACCAGGATATACACGATCGAGATCAGGTTCAACCACAACCTGAGGAGGGCGCTGCATCTACACAAGGCCTTCCTGAACTTCCAAGTCTGGACGACATCCCTGACAGCTTCTGGGACGACATATTTGGAGTGGTTTAA |
|
Protein Sequence
|
MQNSSSSTPPSIKPQHRVAKKRAVRRRRIDLDCGCSIYVHLNCRNHGFTHRGTHHCSSSQEWRVYLGGTKSPLFQDIQRRGSAIHNDQDIHDRDQVQPQPEEGAASTQGLPELPSLDDIPDSFWDDIFGVV |
|
NCBI Accession
|
YP_009508296.1
|
|
Location
|
1390-2466 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACGCAGGGGTTCTTTTTCAGTAAATGCTAAAAACTATTTCCTAACATATCCTCAGTGTTCTCTTACAAAGGAGGACGTTCTTTCCCAAATCCAAAATCTCCAAACCCCAACAAACAAGAAATACATCAAGGTCTGCAGAGAGCTTCACGAGAATGGGGAACCTCATCTCCACGTGCTTATCCAATTCGAGGGTAAATACAACTGCACGAATAACAGATTCTTCGACCTTGTATCCCCAAACAGGTCAACACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACCTGGACAAGGACGGAGACGTTATTGAATGGGGAGAATTCCAGATTGACGGGAGATCTGCTAGAGGAGGTCAACAGACGGCTAACGACACATATGCCAAGGCGTTAAATGCGTCAACAATGGAGGAATCCCTCCAGATAATCAAAGAGCAGCAGCCGGCACACTATTACCTCCAATATCATAATCTGGTGGCTAACGCCACCAGGATATTCAGAAAACCTCCTGAGCAATGGATTCCTCCTTTTCCTCTGTCATCATTCAATAACGTTCCGGAAGTTCTTCAAGAGTGGGCTGACAATTATTTTGGAAGGGATCCCGCTGCGCGGCCATTGAGATCCAAGAGTATCATCATAGAAGGTGATTCAAGGTGTGGTAAAACAATGTGGGCTAGGGCTTTAGGTAAACACAATTACTTAGCTGGTCATTTAGATTTCAATGCTAAGTGCTATTCAGATGATGTTGATTACAACGTCATTGATGACGTAAGCCCTAGTTATTTAAAACTTAAACACTGGAAGGATCTCATTGGCGCCCAAACTCAGTGGCAGACAAACTGCAAATACGGAAAGCCAATCATGATTAAAGGCGGGGTCCCCTCAATCGTACTATGCAATCCAGGGGAGGGATCCTCTTATAAAGACTTCCTGGAGAAGGAAGAAAACGCATCGCTCAAGAGGTGGACCCTTTACAATGCAGAATTCGTCTTCCTCGACTCCCCCCTCTATCAAACCTCAACACAGGGTAGCCAAGAAGAGGGCAGTCCGGCGTAG |
|
Protein Sequence
|
MPRRGSFSVNAKNYFLTYPQCSLTKEDVLSQIQNLQTPTNKKYIKVCRELHENGEPHLHVLIQFEGKYNCTNNRFFDLVSPNRSTHFHPNIQGAKSSSDVKSYLDKDGDVIEWGEFQIDGRSARGGQQTANDTYAKALNASTMEESLQIIKEQQPAHYYLQYHNLVANATRIFRKPPEQWIPPFPLSSFNNVPEVLQEWADNYFGRDPAARPLRSKSIIIEGDSRCGKTMWARALGKHNYLAGHLDFNAKCYSDDVDYNVIDDVSPSYLKLKHWKDLIGAQTQWQTNCKYGKPIMIKGGVPSIVLCNPGEGSSYKDFLEKEENASLKRWTLYNAEFVFLDSPLYQTSTQGSQEEGSPA |
|
NCBI Accession
|
YP_009508297.1
|
|
Location
|
2052-2309 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAACCTCATCTCCACGTGCTTATCCAATTCGAGGGTAAATACAACTGCACGAATAACAGATTCTTCGACCTTGTATCCCCAAACAGGTCAACACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACCTGGACAAGGACGGAGACGTTATTGAATGGGGAGAATTCCAGATTGACGGGAGATCTGCTAGAGGAGGTCAACAGACGGCTAACGACACATATGCCAAGGCGTTAA |
|
Protein Sequence
|
MGNLISTCLSNSRVNTTARITDSSTLYPQTGQHISIQTYRELNPAPMSSPTWTRTETLLNGENSRLTGDLLEEVNRRLTTHMPRR |