Indian cassava mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000846665.1 |
| Release date |
2015/2/12 |
| Submitter |
Hong,Y.G., Robinson,D.J., Harrison,B.D., Hong,Y. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
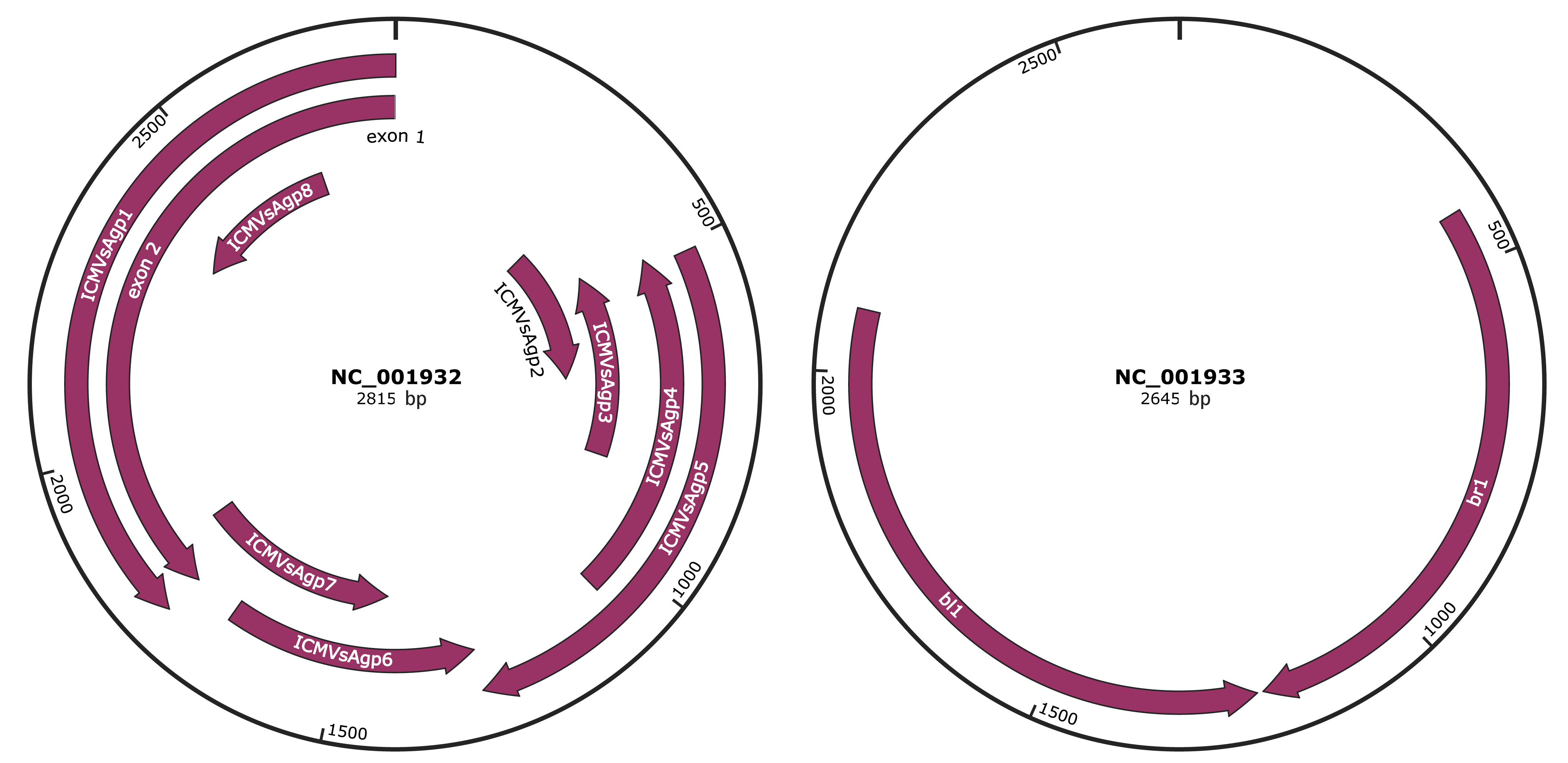
JBrowse
Genome
TTCTCTCTCCTCAATCGGTACTCAGATAGTTTAGCCCCCATATTAGGTACTCAATATATACATGAGTACCAAATGGCATAGATGTAAATAATGGAAATATAATTTGAATTCAAAAGCGGCCATCCGTATAATATTACCGGATGGCCGCGCCCCCCTCTTTATGGTGGTCCCCCCCACGTGGATGGCCGCGCCCCCCTCTTTATGGTGGTCCCCCCCACGTGGATGGCCGCGCCCCCCGCTTTATGGTGGCCCCCCCCACGTGGAGATGTCCCCCACTCAGAACGCTCGCTCAAAGCTTGTATATGTGTGGTCCCCCTTTAAGTACTTGGGCAACAAGTCGTTGCCTGTACAATGTGGGACCCTTTACTAAACGAGTTCCCTGAGTCTGTCCACGGTTTCCGGTGTATGCTCGCCGTGAAATACCTTCAGCTGGTTGAATGTACTTATTCTCCTGATACACTCGGTTACGATTTAATTAGAGATTTGTTCTCTGTTATTAGGGCGAAGAATTATGTCGAAGCGACCAGCAGATATCATAATTTCTACTCCAGGCTCGAAGGTTCGTCGCCGTCTGAACTTCGACAGCCCATACAGCAGCCGTGCGGCTGTCCCTACTGTCCGCGTCACAAAAAGACAATCCTGGACAAACAGACCCATCAATCGGAAGCCCAGGTGGTATCGGATGTATAGAAGCCCAGATGTTCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCGTTCGAGTCGAGACACGATGTGGTCCATATAGGTAAGGTCATGTGCATCTCTGATGTCACTCGTGGAATTGGGCTTACACATCGGGTGGGTAAGAGGTTTTGCGTTAAGTCCATTTACATCCTGGGCAAGATATGGATGGATGAAAACATTAAGACCAAGAATCACACGAATAGCGTAATGTTCTTCCTTGTAAGGGATCGTAGGCCTGTTGATAAGCCTCAGGATTTTGGTGAAGTATTTAATATGTTTGATAATGAGCCCAGTACAGCTACCGTGAAGAACATGCATCGTGATCGCTATCAAGTTCTCAGGAAGTGGCATGCCACGGTCACTGGTGGTCAGTATGCGAGCAAGGAGCAGGCTTTAGTTAGGCGTTTTTTTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGGAAATATGAGAACCATACTGAGAATGCATTAATGTTGTACATGGCGTGTACTCATGCCTCTAATCCTGTATACGCTACGTTGAAGATTAGAATTTATTTCTATGATTCAGTGAGCAATTAATAAATATTTAATTTTATTAAATTAGACTGCTCAACACGGTCAGTCCCATGGATTACATTGTACAATACATGCTCTACGGCTTTTACAATAGTATTAATACTTATAACTCCTAAGCTATCTAAGTATTTCAATACTTGGGTCTTAAATACCCTCAAGAAACGCCAGGTCTGAGGCTGTAAGGTCGTCCAGACCTTGAAATCCATCCAGCATTGATGTAGTCCCAACGCTTTCCTCAGGTTGTGGTTGAACCGTATCTGGACGGTTATTATGTCCTGGTTCATTACGAACGGTCTGTTGTCGTGTTGAATGATCTTGAAATAGAGGGGATTTGGTACCTCCCAGATAAAGACGCCATTCATCGCCTGAGCTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGGTTGTGGCAGTTAATGTGGACGTAGTACGAGCACCCGCAGTTGAGATCTACCCTTTTACGCCGGATGCGTTTACGCTTAGCAGCTCTGTGTTGGACCTTGATTGGTACCTGAGTATAGTGGTCCTTCGAGGGAGATGAAGGTCGCATTTTTCAGAGCCCAGGCTTTTAATGCGCTATTCTTTTCCTCGTCCAGGAATTCTTTATAGCTGGAATTGGGGCCTGGATTGCAGAGGAAGATAGTGGGAATACCTCCTTTAATTTGAACTGGCTTACCGTACTTGGTGTTTGATTGCCAGTCCTCTGGGCCCCCATGAATTCTTTTGAAGTGCTTTAGGTAGTGGGGATCGACGTCATCAATGACGTTGTACCATGCATCATTGTTGTAGACCTTAGGACTTAAATCCAGGTGTCCACATAGGTAATTATGTGGACCCAATGCACGGGACCACATGGTCTTGCCCGTCCGACTATCGCCTTCGATTACGATTGATTTTGGTCTCAAAGGCCGCGCACGACCCATCACGTTTTCGTGGAACCACTCGTCGAGTTCTTCTGGAACTCGGTCAAACGAAGAGAGAGGGAAAGGGTTCTCATATGGAGGTGGTGGTTTTGTAAAAATCCGATCCAGGTTTGAACTGATGTGATGGAAGTCCCTAAGATAATCCCTAGGTGCTAATTCTCTAAGGATCTTAAGAGCCTCTGATTTACTGCCGCTGTTAAGTGCCGCGGCGTAAGCGTCGTTTGCAGATTGTTGACCCCCTCTGGCTGATCGTCCATCGATCTGAAATGTTCCCCATCTCCAAGTATCACCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTGGTTGGTGATACCAGGTCGAAGAATCGCTGATTCTGGCATTTGTATTTGCCTTCGAACTGGATGAGCACGTGCAGATGAGGCTCCCCATTCTCATGTAGCTCCCTGCATATTTTGATGAATTTAGGGTTTGTAGGTGTTTGAAAGTTCCTAATTTGAGAGAGAGCCTCTTCTTTAGTTAAGGAGCATCGAGGGTAAGTGAGGAAATAGTTTTTAGCGTTTATTTGAAAGCGCTTAGGTGGTGACA
TTCTCTCTCCGCAATCGGTACTCAGATAGTTTAGCCCCCATATTAGGTACTCAATATATACATGAGTACCAAATGGCATAGATGTAAATAATGGGAATATAATTTGAATTGAAAAGCGGCCATCCGTATAATATTACCGGATGGCCGCGCCCCCCTCTTTATGGTGGTCCCCCCCACGTGGATGGCCGCGCCCCCCTCTTTATGGTGGTCCCCCCCACGTGGATGGCCGCGCCCCCCGCTTTATGGTGGCCCCCCCCACGTGGAGATGTCCCCCACTCAGAACGCTCGCTCAAAGCTTGTATATGTGTGGTCCCCCTTTAAGTACTTGGGCAACAAGTCGTCGCCTGTACAATGTGGGACCCTTTACTAAACGAGTTTCCTGAGTCTGTCCACGGTTTCCGGAGATCTTGCACATGGTGATTTCAGGATGAGAAGAGGTGCCTATACCCCCCGTTCTACTCCATTCCCTCGTGACCGGAGATCGTATAATGCCGGTAAGGGTAGATCATTTCGTTCGTACCGTCGTCGTGGACCTGTTCGTCCATTAGCTCGTCGGAATCTGTTTGGTGATGACCATGCACGTGCATTCACGTATAAGACCTTATCGGAGGATCAATTTGGACCGGACTTTACCATACATAATAATAATTATAAGTCATCGTATATATCTATGCCTGTTAAAACACGTGCCCTTAGCGATAACAGGGTAGGTGATTATATCAAACTTGTAAATATATCATTTACAGGTACAGTGTGTATAAAAAACAGCCAGATGGAGTCTGACGGAAGCCCAATGTTGGGCCTGCATGGGCTGTTTACTTGTGTATTGGTCCGGGATAAGACCCCCCGTATATATTCTGCCACTGAGCCTTTGATACCTTTCCCACAGTTGTTTGGGTCCATAAACGCGAGCTATGCGGATTTGTCTATACAAGACCCATATAAGGATCGGTTCACAGTTATCCGTCAGGTGTCATACCCAGTTAATACGGAGAAGGGTGATCATATGTGTCGTTTCAAAGGCACTCGTCGTTTTGGTGGTAGATACCCTATCTGGACTAGTTTTAAAGATGATGGTGGCAGTGGAGATTCATCGGGATTATATAGTAATACGTATAAAAATGCCATACTTGTATATTATGTATGGCTCAGCGACGTATCGTCACAATTGGAAATGTATTGTAAATATGTAACTCGATATATTGGTTAATAAAAATGTTATACATTTTTTGATACATGGCTCTGCATACTCGTATTTAAACATATATTTACTGTCTTGCTGATGATGTCGTTTAAGTCCTCTCGTGTGAATTGGTCCGATCCTACTTGTGATACTGACTTTCCTGGGTCCAATGCGTCTGGGTTGAGCCGGTTTAGTTGGTTGTAAGGCCTTTCAATGGATGCCCAGCCTCGCTCTTTAACGGCCCATGGCTCGTGAAGCCCAAGCTCGCTTCTAACGGCCCAGGATTCATTTGGGCCTATTGAACATGGAGCATATCTCATGGATCTGGATCCTATTAGACTTGGGCCTTGGACCAGTTTCCTCTGCTGGGCTTTCCGACCCACTGACCAGAAATCAATGTCCCTCTCAGTGAAGGCCTTGCTCAGTATCTCGATTTTGGGAGATCGGAACTGTATGTCATTAGGACTGCGTTTGCAGTTGACCAGCTTGAGTTTTCCTTGTATACGGCAGAAGTGGACCCCGTTGATGACGTTTGTGTCTACGACCCTGTACATAACCCTCCATGGGTTTATGTCCTTCATGGTAGAGAACGATGAAGAATAGTAGTGAAGGTTGCAGTTGCATTGGACGGGAATAGTAAATTCAGCCTGTTTTGAGTCTCCGTCATGCAGTCTTTGGTCGTGAATTTCAATGATGACATGTCCAGTGGCGTTAATGGGTACCTGGTTTCTATATTCTAGGACGATGTGGTCTATTTTGCAGCAGTGACCCTTGAGGAGCGATATTTTGTTATCCAGAAGAGATGGAAAGCTCAACTTGACGTCTGTTGAGTCATTGGTTAACTCATATTCAACTCTTTCGGAACGAAGATACGCTGCATTGCTACTATTATTCTCCATTGGCCCCGCAAATGCTTAAAAATTAAGCCCAGTGCAGAAGAAATAATTTAATGTGCATAAAGCAAAGCCCAAAGCGTAATAAATAGCTAAAGGCATATATATTATATTATTGATGAAAGGGTATAAGAGCATCCACGTGGCAGTGGATTAAATACATGAAAGCTATACAATATATTTAAAAATAGTTGCTGACGACGTCATCCTTCAACGAATGGAACCGGAAACCCTAATCCATCTCTGAGGACTCTGGTTAAGCCCTCTAGTAGTATGTCACATGTTTCCGGTGTCATGTGGTAGTAATTTTTGAGTTTGTAACCCCAATCTTCTATTTTGAAGGCCATATGTATGGCTCTATCTATTTCTGGTAACAGATCCATATCTTGTTCTTCGAATTGGAGGTAATAGGAATTTGAACCAGTCGCGATGTAAGATTGATGTCTGCTGATCGAATTCTTCATAATGCGACTGGATAGTCACGCACATTTCTTGCTTTGTTGCAAGAAGGAATAGTTAGTTTGGGAAGACATAGGAAGAATGAGAATGATGTTGGGTTTAAGTGGGAT
Gene Information
|
NCBI Accession
|
NP_047233.1
|
|
Location
|
1761-2815,1 |
|
Protein Name
|
AL1 |
|
Coding Region
|
ATGTCACCACCTAAGCGCTTTCAAATAAACGCTAAAAACTATTTCCTCACTTACCCTCGATGCTCCTTAACTAAAGAAGAGGCTCTCTCTCAAATTAGGAACTTTCAAACACCTACAAACCCTAAATTCATCAAAATATGCAGGGAGCTACATGAGAATGGGGAGCCTCATCTGCACGTGCTCATCCAGTTCGAAGGCAAATACAAATGCCAGAATCAGCGATTCTTCGACCTGGTATCACCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGTGATACTTGGAGATGGGGAACATTTCAGATCGATGGACGATCAGCCAGAGGGGGTCAACAATCTGCAAACGACGCTTACGCCGCGGCACTTAACAGCGGCAGTAAATCAGAGGCTCTTAAGATCCTTAGAGAATTAGCACCTAGGGATTATCTTAGGGACTTCCATCACATCAGTTCAAACCTGGATCGGATTTTTACAAAACCACCACCTCCATATGAGAACCCTTTCCCTCTCTCTTCGTTTGACCGAGTTCCAGAAGAACTCGACGAGTGGTTCCACGAAAACGTGATGGGTCGTGCGCGGCCTTTGAGACCAAAATCAATCGTAATCGAAGGCGATAGTCGGACGGGCAAGACCATGTGGTCCCGTGCATTGGGTCCACATAATTACCTATGTGGACACCTGGATTTAAGTCCTAAGGTCTACAACAATGATGCATGGTACAACGTCATTGATGACGTCGATCCCCACTACCTAAAGCACTTCAAAAGAATTCATGGGGGCCCAGAGGACTGGCAATCAAACACCAAGTACGGTAAGCCAGTTCAAATTAAAGGAGGTATTCCCACTATCTTCCTCTGCAATCCAGGCCCCAATTCCAGCTATAAAGAATTCCTGGACGAGGAAAAGAATAGCGCATTAAAAGCCTGGGCTCTGAAAAATGCGACCTTCATCTCCCTCGAAGGACCACTATACTCAGGTACCAATCAAGGTCCAACACAGAGCTGCTAA |
|
Protein Sequence
|
MSPPKRFQINAKNYFLTYPRCSLTKEEALSQIRNFQTPTNPKFIKICRELHENGEPHLHVLIQFEGKYKCQNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTWRWGTFQIDGRSARGGQQSANDAYAAALNSGSKSEALKILRELAPRDYLRDFHHISSNLDRIFTKPPPPYENPFPLSSFDRVPEELDEWFHENVMGRARPLRPKSIVIEGDSRTGKTMWSRALGPHNYLCGHLDLSPKVYNNDAWYNVIDDVDPHYLKHFKRIHGGPEDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNSALKAWALKNATFISLEGPLYSGTNQGPTQSC |
|
NCBI Accession
|
NP_047227.1
|
|
Location
|
352-690 |
|
Protein Name
|
AR0 |
|
Coding Region
|
ATGTGGGACCCTTTACTAAACGAGTTCCCTGAGTCTGTCCACGGTTTCCGGTGTATGCTCGCCGTGAAATACCTTCAGCTGGTTGAATGTACTTATTCTCCTGATACACTCGGTTACGATTTAATTAGAGATTTGTTCTCTGTTATTAGGGCGAAGAATTATGTCGAAGCGACCAGCAGATATCATAATTTCTACTCCAGGCTCGAAGGTTCGTCGCCGTCTGAACTTCGACAGCCCATACAGCAGCCGTGCGGCTGTCCCTACTGTCCGCGTCACAAAAAGACAATCCTGGACAAACAGACCCATCAATCGGAAGCCCAGGTGGTATCGGATGTATAG |
|
Protein Sequence
|
MWDPLLNEFPESVHGFRCMLAVKYLQLVECTYSPDTLGYDLIRDLFSVIRAKNYVEATSRYHNFYSRLEGSSPSELRQPIQQPCGCPYCPRHKKTILDKQTHQSEAQVVSDV |
|
NCBI Accession
|
NP_047228.1
|
|
Location
|
472-852 |
|
Protein Name
|
AL5 |
|
Coding Region
|
ATGGACTTAACGCAAAACCTCTTACCCACCCGATGTGTAAGCCCAATTCCACGAGTGACATCAGAGATGCACATGACCTTACCTATATGGACCACATCGTGTCTCGACTCGAACGACTGGACCTTACATGGGCCTTCACAGCCCTTAGGAACATCTGGGCTTCTATACATCCGATACCACCTGGGCTTCCGATTGATGGGTCTGTTTGTCCAGGATTGTCTTTTTGTGACGCGGACAGTAGGGACAGCCGCACGGCTGCTGTATGGGCTGTCGAAGTTCAGACGGCGACGAACCTTCGAGCCTGGAGTAGAAATTATGATATCTGCTGGTCGCTTCGACATAATTCTTCGCCCTAATAACAGAGAACAAATCTCTAATTAA |
|
Protein Sequence
|
MDLTQNLLPTRCVSPIPRVTSEMHMTLPIWTTSCLDSNDWTLHGPSQPLGTSGLLYIRYHLGFRLMGLFVQDCLFVTRTVGTAARLLYGLSKFRRRRTFEPGVEIMISAGRFDIILRPNNREQISN |
|
NCBI Accession
|
NP_047229.1
|
|
Location
|
497-1060 |
|
Protein Name
|
AL4 |
|
Coding Region
|
ATGCCACTTCCTGAGAACTTGATAGCGATCACGATGCATGTTCTTCACGGTAGCTGTACTGGGCTCATTATCAAACATATTAAATACTTCACCAAAATCCTGAGGCTTATCAACAGGCCTACGATCCCTTACAAGGAAGAACATTACGCTATTCGTGTGATTCTTGGTCTTAATGTTTTCATCCATCCATATCTTGCCCAGGATGTAAATGGACTTAACGCAAAACCTCTTACCCACCCGATGTGTAAGCCCAATTCCACGAGTGACATCAGAGATGCACATGACCTTACCTATATGGACCACATCGTGTCTCGACTCGAACGACTGGACCTTACATGGGCCTTCACAGCCCTTAGGAACATCTGGGCTTCTATACATCCGATACCACCTGGGCTTCCGATTGATGGGTCTGTTTGTCCAGGATTGTCTTTTTGTGACGCGGACAGTAGGGACAGCCGCACGGCTGCTGTATGGGCTGTCGAAGTTCAGACGGCGACGAACCTTCGAGCCTGGAGTAGAAATTATGATATCTGCTGGTCGCTTCGACATAATTCTTCGCCCTAA |
|
Protein Sequence
|
MPLPENLIAITMHVLHGSCTGLIIKHIKYFTKILRLINRPTIPYKEEHYAIRVILGLNVFIHPYLAQDVNGLNAKPLTHPMCKPNSTSDIRDAHDLTYMDHIVSRLERLDLTWAFTALRNIWASIHPIPPGLPIDGSVCPGLSFCDADSRDSRTAAVWAVEVQTATNLRAWSRNYDICWSLRHNSSP |
|
NCBI Accession
|
NP_047230.1
|
|
Location
|
512-1282 |
|
Protein Name
|
AR1 |
|
Coding Region
|
ATGTCGAAGCGACCAGCAGATATCATAATTTCTACTCCAGGCTCGAAGGTTCGTCGCCGTCTGAACTTCGACAGCCCATACAGCAGCCGTGCGGCTGTCCCTACTGTCCGCGTCACAAAAAGACAATCCTGGACAAACAGACCCATCAATCGGAAGCCCAGGTGGTATCGGATGTATAGAAGCCCAGATGTTCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCGTTCGAGTCGAGACACGATGTGGTCCATATAGGTAAGGTCATGTGCATCTCTGATGTCACTCGTGGAATTGGGCTTACACATCGGGTGGGTAAGAGGTTTTGCGTTAAGTCCATTTACATCCTGGGCAAGATATGGATGGATGAAAACATTAAGACCAAGAATCACACGAATAGCGTAATGTTCTTCCTTGTAAGGGATCGTAGGCCTGTTGATAAGCCTCAGGATTTTGGTGAAGTATTTAATATGTTTGATAATGAGCCCAGTACAGCTACCGTGAAGAACATGCATCGTGATCGCTATCAAGTTCTCAGGAAGTGGCATGCCACGGTCACTGGTGGTCAGTATGCGAGCAAGGAGCAGGCTTTAGTTAGGCGTTTTTTTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGGAAATATGAGAACCATACTGAGAATGCATTAATGTTGTACATGGCGTGTACTCATGCCTCTAATCCTGTATACGCTACGTTGAAGATTAGAATTTATTTCTATGATTCAGTGAGCAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPGSKVRRRLNFDSPYSSRAAVPTVRVTKRQSWTNRPINRKPRWYRMYRSPDVPKGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGIGLTHRVGKRFCVKSIYILGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWHATVTGGQYASKEQALVRRFFRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
NP_047231.1
|
|
Location
|
1279-1683 |
|
Protein Name
|
AL3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAGGCGATGAATGGCGTCTTTATCTGGGAGGTACCAAATCCCCTCTATTTCAAGATCATTCAACACGACAACAGACCGTTCGTAATGAACCAGGACATAATAACCGTCCAGATACGGTTCAACCACAACCTGAGGAAAGCGTTGGGACTACATCAATGCTGGATGGATTTCAAGGTCTGGACGACCTTACAGCCTCAGACCTGGCGTTTCTTGAGGGTATTTAAGACCCAAGTATTGAAATACTTAGATAGCTTAGGAGTTATAAGTATTAATACTATTGTAAAAGCCGTAGAGCATGTATTGTACAATGTAATCCATGGGACTGACCGTGTTGAGCAGTCTAATTTAATAAAATTAAATATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAAQAMNGVFIWEVPNPLYFKIIQHDNRPFVMNQDIITVQIRFNHNLRKALGLHQCWMDFKVWTTLQPQTWRFLRVFKTQVLKYLDSLGVISINTIVKAVEHVLYNVIHGTDRVEQSNLIKLNIY |
|
NCBI Accession
|
NP_047232.1
|
|
Location
|
1424-1831 |
|
Protein Name
|
AL2 |
|
Coding Region
|
ATGCGACCTTCATCTCCCTCGAAGGACCACTATACTCAGGTACCAATCAAGGTCCAACACAGAGCTGCTAAGCGTAAACGCATCCGGCGTAAAAGGGTAGATCTCAACTGCGGGTGCTCGTACTACGTCCACATTAACTGCCACAACCATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAGGCGATGAATGGCGTCTTTATCTGGGAGGTACCAAATCCCCTCTATTTCAAGATCATTCAACACGACAACAGACCGTTCGTAATGAACCAGGACATAATAACCGTCCAGATACGGTTCAACCACAACCTGAGGAAAGCGTTGGGACTACATCAATGCTGGATGGATTTCAAGGTCTGGACGACCTTACAGCCTCAGACCTGGCGTTTCTTGAGGGTATTTAA |
|
Protein Sequence
|
MRPSSPSKDHYTQVPIKVQHRAAKRKRIRRKRVDLNCGCSYYVHINCHNHGFTHRGTHHCSSGDEWRLYLGGTKSPLFQDHSTRQQTVRNEPGHNNRPDTVQPQPEESVGTTSMLDGFQGLDDLTASDLAFLEGI |
|
NCBI Accession
|
NP_047234.1
|
|
Location
|
2357-2665 |
|
Protein Name
|
AL0 |
|
Coding Region
|
ATGAGAATGGGGAGCCTCATCTGCACGTGCTCATCCAGTTCGAAGGCAAATACAAATGCCAGAATCAGCGATTCTTCGACCTGGTATCACCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGTGATACTTGGAGATGGGGAACATTTCAGATCGATGGACGATCAGCCAGAGGGGGTCAACAATCTGCAAACGACGCTTACGCCGCGGCACTTAACAGCGGCAGTAAATCAGAGGCTCTTAAGATCCTTAGAGAATTAG |
|
Protein Sequence
|
MRMGSLICTCSSSSKANTNARISDSSTWYHQPGQHISIQTFRELNPAPTSSPTSTRTVILGDGEHFRSMDDQPEGVNNLQTTLTPRHLTAAVNQRLLRSLEN |
|
NCBI Accession
|
NP_047235.1
|
|
Location
|
428-1210 |
|
Gene Name
|
br1 |
|
Protein Name
|
BR1 protein |
|
Coding Region
|
ATGAGAAGAGGTGCCTATACCCCCCGTTCTACTCCATTCCCTCGTGACCGGAGATCGTATAATGCCGGTAAGGGTAGATCATTTCGTTCGTACCGTCGTCGTGGACCTGTTCGTCCATTAGCTCGTCGGAATCTGTTTGGTGATGACCATGCACGTGCATTCACGTATAAGACCTTATCGGAGGATCAATTTGGACCGGACTTTACCATACATAATAATAATTATAAGTCATCGTATATATCTATGCCTGTTAAAACACGTGCCCTTAGCGATAACAGGGTAGGTGATTATATCAAACTTGTAAATATATCATTTACAGGTACAGTGTGTATAAAAAACAGCCAGATGGAGTCTGACGGAAGCCCAATGTTGGGCCTGCATGGGCTGTTTACTTGTGTATTGGTCCGGGATAAGACCCCCCGTATATATTCTGCCACTGAGCCTTTGATACCTTTCCCACAGTTGTTTGGGTCCATAAACGCGAGCTATGCGGATTTGTCTATACAAGACCCATATAAGGATCGGTTCACAGTTATCCGTCAGGTGTCATACCCAGTTAATACGGAGAAGGGTGATCATATGTGTCGTTTCAAAGGCACTCGTCGTTTTGGTGGTAGATACCCTATCTGGACTAGTTTTAAAGATGATGGTGGCAGTGGAGATTCATCGGGATTATATAGTAATACGTATAAAAATGCCATACTTGTATATTATGTATGGCTCAGCGACGTATCGTCACAATTGGAAATGTATTGTAAATATGTAACTCGATATATTGGTTAA |
|
Protein Sequence
|
MRRGAYTPRSTPFPRDRRSYNAGKGRSFRSYRRRGPVRPLARRNLFGDDHARAFTYKTLSEDQFGPDFTIHNNNYKSSYISMPVKTRALSDNRVGDYIKLVNISFTGTVCIKNSQMESDGSPMLGLHGLFTCVLVRDKTPRIYSATEPLIPFPQLFGSINASYADLSIQDPYKDRFTVIRQVSYPVNTEKGDHMCRFKGTRRFGGRYPIWTSFKDDGGSGDSSGLYSNTYKNAILVYYVWLSDVSSQLEMYCKYVTRYIG |
|
NCBI Accession
|
NP_047236.1
|
|
Location
|
1219-2082 |
|
Gene Name
|
bl1 |
|
Protein Name
|
BL1 protein |
|
Coding Region
|
ATGGAGAATAATAGTAGCAATGCAGCGTATCTTCGTTCCGAAAGAGTTGAATATGAGTTAACCAATGACTCAACAGACGTCAAGTTGAGCTTTCCATCTCTTCTGGATAACAAAATATCGCTCCTCAAGGGTCACTGCTGCAAAATAGACCACATCGTCCTAGAATATAGAAACCAGGTACCCATTAACGCCACTGGACATGTCATCATTGAAATTCACGACCAAAGACTGCATGACGGAGACTCAAAACAGGCTGAATTTACTATTCCCGTCCAATGCAACTGCAACCTTCACTACTATTCTTCATCGTTCTCTACCATGAAGGACATAAACCCATGGAGGGTTATGTACAGGGTCGTAGACACAAACGTCATCAACGGGGTCCACTTCTGCCGTATACAAGGAAAACTCAAGCTGGTCAACTGCAAACGCAGTCCTAATGACATACAGTTCCGATCTCCCAAAATCGAGATACTGAGCAAGGCCTTCACTGAGAGGGACATTGATTTCTGGTCAGTGGGTCGGAAAGCCCAGCAGAGGAAACTGGTCCAAGGCCCAAGTCTAATAGGATCCAGATCCATGAGATATGCTCCATGTTCAATAGGCCCAAATGAATCCTGGGCCGTTAGAAGCGAGCTTGGGCTTCACGAGCCATGGGCCGTTAAAGAGCGAGGCTGGGCATCCATTGAAAGGCCTTACAACCAACTAAACCGGCTCAACCCAGACGCATTGGACCCAGGAAAGTCAGTATCACAAGTAGGATCGGACCAATTCACACGAGAGGACTTAAACGACATCATCAGCAAGACAGTAAATATATGTTTAAATACGAGTATGCAGAGCCATGTATCAAAAAATGTATAA |
|
Protein Sequence
|
MENNSSNAAYLRSERVEYELTNDSTDVKLSFPSLLDNKISLLKGHCCKIDHIVLEYRNQVPINATGHVIIEIHDQRLHDGDSKQAEFTIPVQCNCNLHYYSSSFSTMKDINPWRVMYRVVDTNVINGVHFCRIQGKLKLVNCKRSPNDIQFRSPKIEILSKAFTERDIDFWSVGRKAQQRKLVQGPSLIGSRSMRYAPCSIGPNESWAVRSELGLHEPWAVKERGWASIERPYNQLNRLNPDALDPGKSVSQVGSDQFTREDLNDIISKTVNICLNTSMQSHVSKNV |