Hollyhock yellow vein mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000896675.1 |
| Isolate |
Pakistan:Lahore |
| Release date |
2015/2/22 |
| Submitter |
Zia Ur Rehman,M., Haider,M.S., Zia ur Rehman,M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
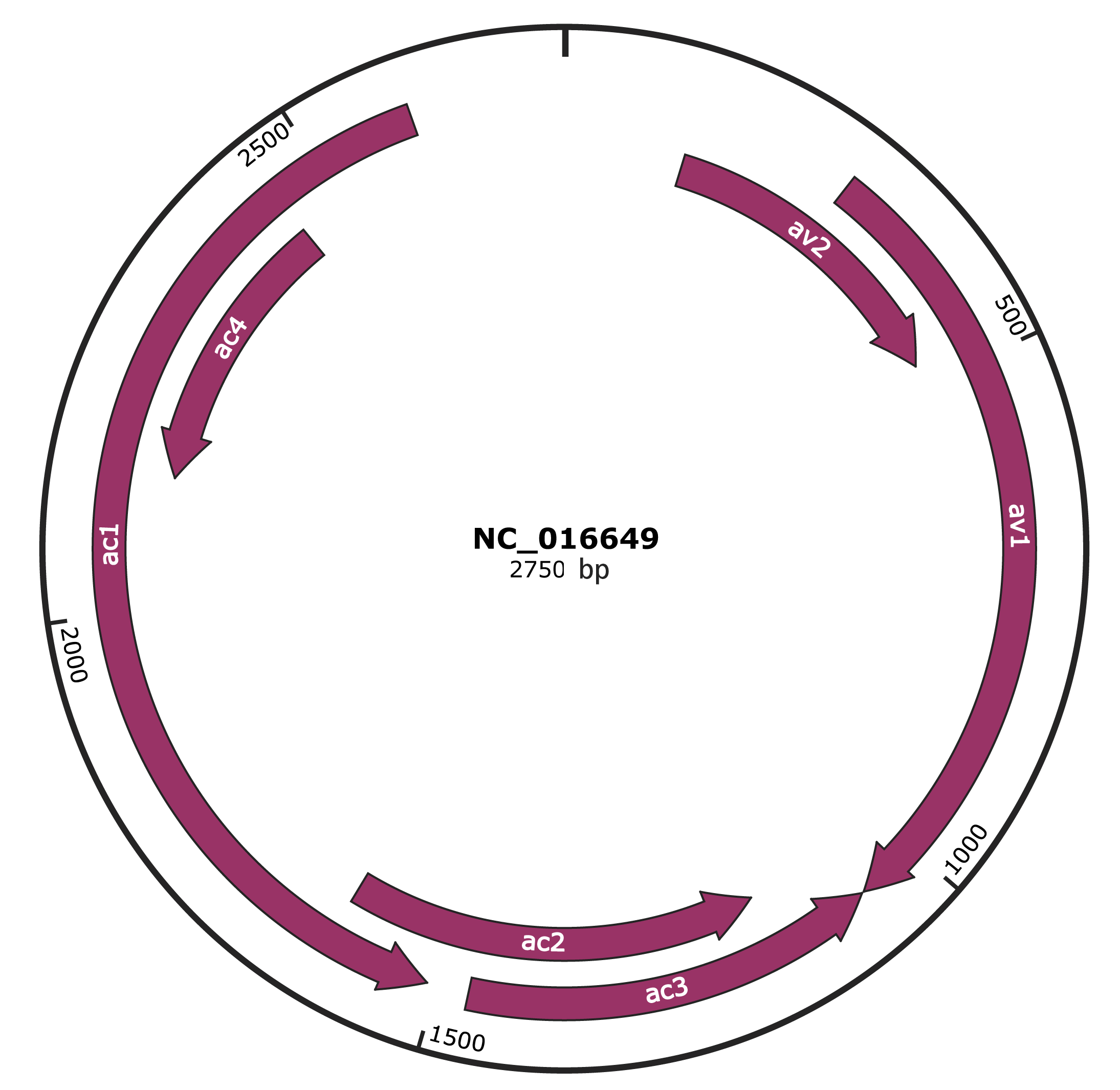
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTTTGTGGGCCCCTCCACTAACTCTTGTCTGCCAATCAAATGACGCGCTCAAAGCTTAAATAATTTCCCGCCTATTATAAGTACTTCTTCGACAAGTTTCATTTTGAAAATGTGGGATCCACTGTTAAACGAGTTCCCTGAGACTGTTCACGGGTTTCGTTGCATGCTTGCGATTAAATATCTTCAACAACTGTCTGAAGAATACTCTCCTGATACGGTAGGTTACGATCTAATTCGCGATTTAATTTCTATTTTACGTTCCAGGAATTATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGTCGACTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGCCCCCACTGTCCGCGTCACAAAGTCTCGCATTTGGGCGAACAGGCCCATGTATCGGAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGATGTTCCTAAGGGTTGTGAAGGCCCATGTAAGGTGCAGTCTTTCGATGCGAAAAATGATATTGGGCATATGGGTAAGGTAATTTGTCTTTCTGATGTTACTAGGGGTATTGGGCTGACCCATCGAGTAGGGAAACGTTTTTGCGTTAAGTCATTGTATTTTGTTGGCAAAATATGGATGGACGAGAACATCAAGACTAAGAACCATACAAACACTGTTTTGTTCTGGATCGTGAGAGACAGGCGTCCTTCAGGAACTCCTAATGATTTCCAGCAAGTTTTCAATGTTTATGATAACGAGCCTTCTACGGCTACTGTGAAGAACGACCAGCGTAATCGTTTTCAGGTGTTGAGGAGGTTCCAGGCAACAGTCACAGGTGGTCAATATGCTGCTAAGGAACAAGCTATAATCAGGAAATTCTATCGTGTTAACAATTATGTTGTCTATAATCACCAGGAAGCTGGGAAGTATGAGAATCACACTGAGAATGCTTTGTTGTTGTACATGGCATGTACCCATGCCTCTAACCCCGTGTATGCTACTTTGAAAGTTAGAAGTTATTTCTATGATTCTGTAACCAATTAATATTAATAAATATCGAATTTTATTTCTGAAACTTGGTCTACATACATAGTTTGTTCTATTTTACTGTACAATACATGATCTACTGCTCTAATAATCGAATTAATTGAGATTACTCCTATATTGTTGAGATACTTTATGACTTGGGTCTTGAATACCCTTAAGAAAAGACCAGTCGGAGGGTGTAAGGTCGTCCAAACCCGGAAGGTCAGAAAACACTTGTGCACTCCCAGAGCTCTCCGAAGGTTGTAGTTGAATTGGATCCTGATTGTTATTATGTCCATCTTGCTCGAGTAAGGACAGACCTCGTGGCTTAGGATCTTGAAATAAAGGGGATTTGGTACTTCCCAGATATAGGCGCCACTCCATGCTTGAGCTGCAGTGATGGGTTCCTCTGTGCGTAAATCCATGGTTGAAACAGTTTATAGACAGATAATAAGAACACCCGCATTCAAGATCTACTCTCCTCCTCCTGTTGCGTTTCTTCGCTTCCCTGTGCTGTACTTTGATTGGAACCTGAGTACAGTGGTCCTTCAAGGGTGACGAAGATCGCATTCTTGTCTGTCCAGTTCTTTAGTGCAGTGTTCTTTTCCTCGTCCAGGAATTCTTTATAACTGCTGTTAGGACCAGGATTGCAGAGGAAGATTGTTGGTATTCCGCCTTTAATTTGAACTGGCTTCCCGTACTTTGTGTTGGATTGCCAGTCCCTTTGGGCCCCCATGAACTCTTTAAAGTGTTTGAGGAAGTGCGGATCAACGTCATCAATGACGTTATACCAAGCGTCATTACTGTACACCTTTGGGCTTAGATCTAAATGCCCACATAAATAGTTATGTGGGCCTAAAGACCTAGCCCACATTGTTTTCCCAGTACGACTGTCGCCCTCAATTACTATACTTTGAGGTCTCAGGGGCCGCGCAGCGGCGTCGACAACATTTACACACGCCCACTCTTCAAGTTCTTCTGGAACTTGATCGAAAGAAGAAGACGAAAAAGGAGAAACATAAGGAGCTGGTGGCTCCTGAAAGATCCTGTCTAGATTTGCATTTAAATTATGAAATTGTAGTACAAAATCTTTAGGAGCTAGTTCCTTAATGACTCTAAGAGCCTCCGACTTACTTCCCGCGTTAAGTGCTGCGGCGTAAGCGTCGTTGGCTGTCTGTTGCCCTCCTCTTGCTGATCTTCCATCGATCTGAAATTCTCCCCAGTCGAGAATGTCCCCGTCCTTGGCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGATACGAGGTCGAAGAATCTGTTATTTTTGCACTTGTATTTGCCTTCGAACTGGATGAGCACGTGAAGATGAGGTTCCCCATTTTCATGAAACTCTCTGCAGATTCTAATGTATTTTTTGTTTACTGGGGTTTGTAGGTTTTGTAATTGGGAAAGTGCCTCCTCTTTAGTAAGAGAGCATGTGGGATAAGTGATGAAATAATTTTTGGCATTTATCTGGAATTGTTTGGGAGGAGCCATTGACTTGGTCAATCGGTACCCAGCACTAGTCTTATGGCAATTGGGGAACGGTACCCTATATATAGTTGGGTACCAAATGGCAATAATTGTAATTACGTAATCAAATTCAAAATCCTCGCGCTCCAAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_005086953.1
|
|
Location
|
131-478 |
|
Gene Name
|
av2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCACTGTTAAACGAGTTCCCTGAGACTGTTCACGGGTTTCGTTGCATGCTTGCGATTAAATATCTTCAACAACTGTCTGAAGAATACTCTCCTGATACGGTAGGTTACGATCTAATTCGCGATTTAATTTCTATTTTACGTTCCAGGAATTATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGTCGACTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGCCCCCACTGTCCGCGTCACAAAGTCTCGCATTTGGGCGAACAGGCCCATGTATCGGAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPETVHGFRCMLAIKYLQQLSEEYSPDTVGYDLIRDLISILRSRNYVEASCRYRHFYPRVEGASSTELRQPLCNPCSCPHCPRHKVSHLGEQAHVSEAQNVQDVQKP |
|
NCBI Accession
|
YP_005086954.1
|
|
Location
|
291-1061 |
|
Gene Name
|
av1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGTCGACTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGCCCCCACTGTCCGCGTCACAAAGTCTCGCATTTGGGCGAACAGGCCCATGTATCGGAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGATGTTCCTAAGGGTTGTGAAGGCCCATGTAAGGTGCAGTCTTTCGATGCGAAAAATGATATTGGGCATATGGGTAAGGTAATTTGTCTTTCTGATGTTACTAGGGGTATTGGGCTGACCCATCGAGTAGGGAAACGTTTTTGCGTTAAGTCATTGTATTTTGTTGGCAAAATATGGATGGACGAGAACATCAAGACTAAGAACCATACAAACACTGTTTTGTTCTGGATCGTGAGAGACAGGCGTCCTTCAGGAACTCCTAATGATTTCCAGCAAGTTTTCAATGTTTATGATAACGAGCCTTCTACGGCTACTGTGAAGAACGACCAGCGTAATCGTTTTCAGGTGTTGAGGAGGTTCCAGGCAACAGTCACAGGTGGTCAATATGCTGCTAAGGAACAAGCTATAATCAGGAAATTCTATCGTGTTAACAATTATGTTGTCTATAATCACCAGGAAGCTGGGAAGTATGAGAATCACACTGAGAATGCTTTGTTGTTGTACATGGCATGTACCCATGCCTCTAACCCCGTGTATGCTACTTTGAAAGTTAGAAGTTATTTCTATGATTCTGTAACCAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPYATRAVAPTVRVTKSRIWANRPMYRKPRMYRMYRSPDVPKGCEGPCKVQSFDAKNDIGHMGKVICLSDVTRGIGLTHRVGKRFCVKSLYFVGKIWMDENIKTKNHTNTVLFWIVRDRRPSGTPNDFQQVFNVYDNEPSTATVKNDQRNRFQVLRRFQATVTGGQYAAKEQAIIRKFYRVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKVRSYFYDSVTN |
|
NCBI Accession
|
YP_005086955.1
|
|
Location
|
1064-1468 |
|
Gene Name
|
ac3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTTACGCACAGAGGAACCCATCACTGCAGCTCAAGCATGGAGTGGCGCCTATATCTGGGAAGTACCAAATCCCCTTTATTTCAAGATCCTAAGCCACGAGGTCTGTCCTTACTCGAGCAAGATGGACATAATAACAATCAGGATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTGCACAAGTGTTTTCTGACCTTCCGGGTTTGGACGACCTTACACCCTCCGACTGGTCTTTTCTTAAGGGTATTCAAGACCCAAGTCATAAAGTATCTCAACAATATAGGAGTAATCTCAATTAATTCGATTATTAGAGCAGTAGATCATGTATTGTACAGTAAAATAGAACAAACTATGTATGTAGACCAAGTTTCAGAAATAAAATTCGATATTTATTAA |
|
Protein Sequence
|
MDLRTEEPITAAQAWSGAYIWEVPNPLYFKILSHEVCPYSSKMDIITIRIQFNYNLRRALGVHKCFLTFRVWTTLHPPTGLFLRVFKTQVIKYLNNIGVISINSIIRAVDHVLYSKIEQTMYVDQVSEIKFDIY |
|
NCBI Accession
|
YP_005086956.1
|
|
Location
|
1161-1613 |
|
Gene Name
|
ac2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCGATCTTCGTCACCCTTGAAGGACCACTGTACTCAGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAAACGCAACAGGAGGAGGAGAGTAGATCTTGAATGCGGGTGTTCTTATTATCTGTCTATAAACTGTTTCAACCATGGATTTACGCACAGAGGAACCCATCACTGCAGCTCAAGCATGGAGTGGCGCCTATATCTGGGAAGTACCAAATCCCCTTTATTTCAAGATCCTAAGCCACGAGGTCTGTCCTTACTCGAGCAAGATGGACATAATAACAATCAGGATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTGCACAAGTGTTTTCTGACCTTCCGGGTTTGGACGACCTTACACCCTCCGACTGGTCTTTTCTTAAGGGTATTCAAGACCCAAGTCATAAAGTATCTCAACAATATAGGAGTAATCTCAATTAA |
|
Protein Sequence
|
MRSSSPLKDHCTQVPIKVQHREAKKRNRRRRVDLECGCSYYLSINCFNHGFTHRGTHHCSSSMEWRLYLGSTKSPLFQDPKPRGLSLLEQDGHNNNQDPIQLQPSESSGSAQVFSDLPGLDDLTPSDWSFLKGIQDPSHKVSQQYRSNLN |
|
NCBI Accession
|
YP_005086957.1
|
|
Location
|
1510-2601 |
|
Gene Name
|
ac1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGGCTCCTCCCAAACAATTCCAGATAAATGCCAAAAATTATTTCATCACTTATCCCACATGCTCTCTTACTAAAGAGGAGGCACTTTCCCAATTACAAAACCTACAAACCCCAGTAAACAAAAAATACATTAGAATCTGCAGAGAGTTTCATGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAAGGCAAATACAAGTGCAAAAATAACAGATTCTTCGACCTCGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGCCAAGGACGGGGACATTCTCGACTGGGGAGAATTTCAGATCGATGGAAGATCAGCAAGAGGAGGGCAACAGACAGCCAACGACGCTTACGCCGCAGCACTTAACGCGGGAAGTAAGTCGGAGGCTCTTAGAGTCATTAAGGAACTAGCTCCTAAAGATTTTGTACTACAATTTCATAATTTAAATGCAAATCTAGACAGGATCTTTCAGGAGCCACCAGCTCCTTATGTTTCTCCTTTTTCGTCTTCTTCTTTCGATCAAGTTCCAGAAGAACTTGAAGAGTGGGCGTGTGTAAATGTTGTCGACGCCGCTGCGCGGCCCCTGAGACCTCAAAGTATAGTAATTGAGGGCGACAGTCGTACTGGGAAAACAATGTGGGCTAGGTCTTTAGGCCCACATAACTATTTATGTGGGCATTTAGATCTAAGCCCAAAGGTGTACAGTAATGACGCTTGGTATAACGTCATTGATGACGTTGATCCGCACTTCCTCAAACACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAATCCAACACAAAGTACGGGAAGCCAGTTCAAATTAAAGGCGGAATACCAACAATCTTCCTCTGCAATCCTGGTCCTAACAGCAGTTATAAAGAATTCCTGGACGAGGAAAAGAACACTGCACTAAAGAACTGGACAGACAAGAATGCGATCTTCGTCACCCTTGAAGGACCACTGTACTCAGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAAACGCAACAGGAGGAGGAGAGTAGATCTTGA |
|
Protein Sequence
|
MAPPKQFQINAKNYFITYPTCSLTKEEALSQLQNLQTPVNKKYIRICREFHENGEPHLHVLIQFEGKYKCKNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIAKDGDILDWGEFQIDGRSARGGQQTANDAYAAALNAGSKSEALRVIKELAPKDFVLQFHNLNANLDRIFQEPPAPYVSPFSSSSFDQVPEELEEWACVNVVDAAARPLRPQSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNTALKNWTDKNAIFVTLEGPLYSGSNQSTAQGSEETQQEEESRS |
|
NCBI Accession
|
YP_005086958.1
|
|
Location
|
2142-2450 |
|
Gene Name
|
ac4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAAGGCAAATACAAGTGCAAAAATAACAGATTCTTCGACCTCGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGCCAAGGACGGGGACATTCTCGACTGGGGAGAATTTCAGATCGATGGAAGATCAGCAAGAGGAGGGCAACAGACAGCCAACGACGCTTACGCCGCAGCACTTAACGCGGGAAGTAAGTCGGAGGCTCTTAGAGTCATTAAGGAACTAG |
|
Protein Sequence
|
MKMGNLIFTCSSSSKANTSAKITDSSTSYPQPGQHISIRTFRELNPAPTSSPTSPRTGTFSTGENFRSMEDQQEEGNRQPTTLTPQHLTREVSRRLLESLRN |