Hollyhock leaf curl virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002986605.1 |
| Isolate |
Pakistan:Faisalabad |
| Release date |
2018/8/26 |
| Submitter |
Zia Ur Rehman,M., Haider,M.S., Zia ur Rehman,M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
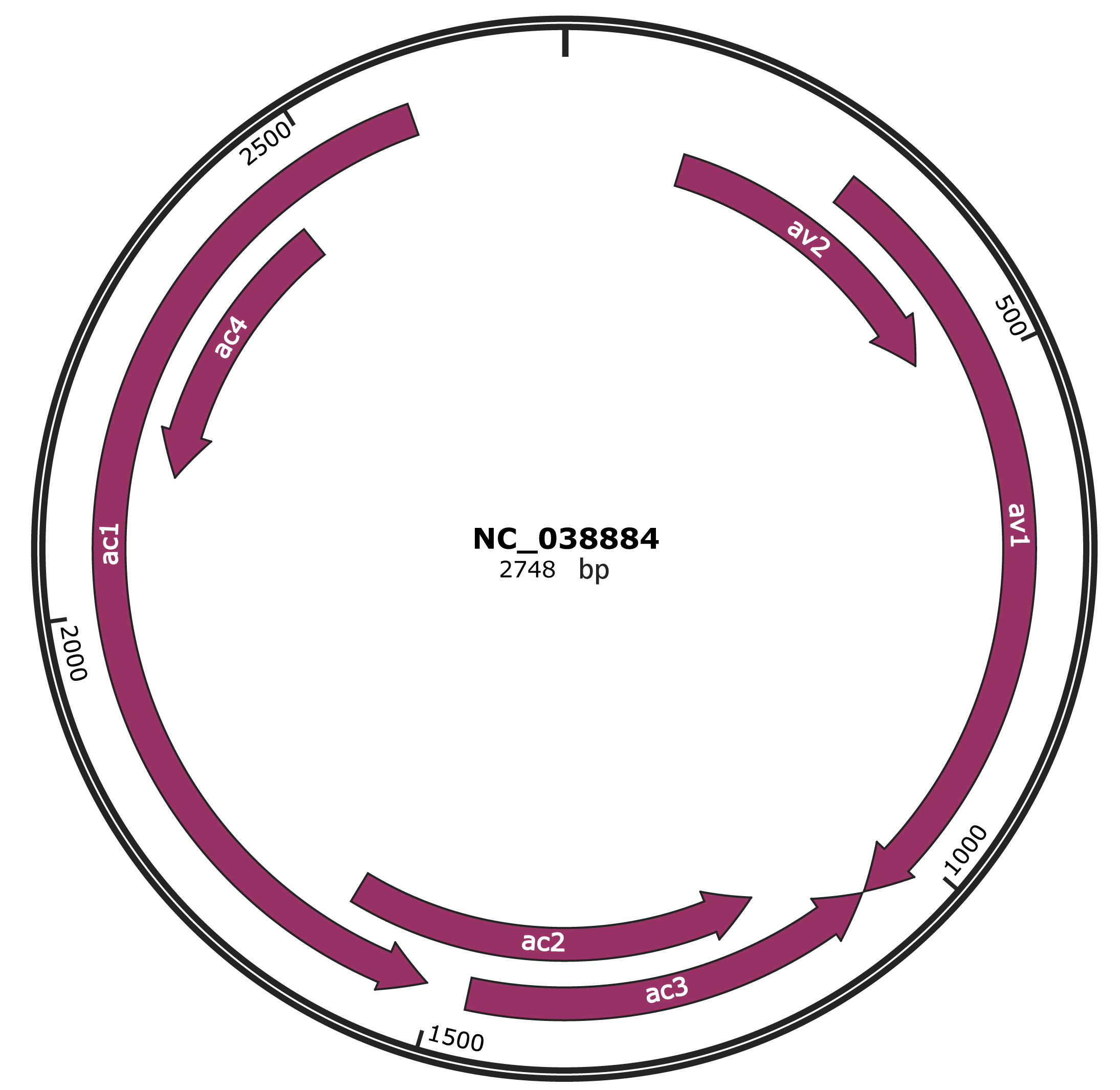
JBrowse
Genome
ACCGGATGGCCGCGCAATTTTTTTGGGTCCCACCACTAACTCTTGTCTGCCAATCATATACGGCGCTCAAAGCTTAAATAAATATCCCGCTTATTATAAATACTTCCTTGCTAAGTTTCAGTTTGAAAAATGTGGGATCCACTTTTAAACGAGTTCCCCGAGACGGTTCACGGGTTTCGTTGCATGCTTGCGATAAAATACCTGCAACTGCTGTCTGAGGAATACTCTCCGGATACGGTAGGTTACGATTTAATTCGCGATTTAATTTCTATTTTACGATCTAGGAATTATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGGCGTCTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGTCCCCACTGTCCGCGTCACAAAATCACGCATGTGGGCGAACAGGCCCATGAACCGGAAGCCCAGAATGTACAGAATGTACAGAAGCCCTGATGTTCCAAGAGGCTGTGAGGGTCCATGTAAGGTCCAATCCTTTGAGTCCAGACACGATGTAGTCCATATAGGTAAGGTCATGTGTATTAGTGATGTTACTCGCGGTACTGGGCTGACCCATAGAGTTGGGAAACGTTTCTGTGTTAAATCAGTCTATGTATTGGGTAAGATCTGGATGGATGAAAACATAAAGTCCAAAAACCACACTAACAATGTGATGTTCTTCTTGGTCCGTGATCGACGGCCTGTGGATAAGCCTCAGGATTTTGGAGAGGTCTTCAACATGTTCGACAACGAGCCCAGCACCGCTACTGTCAAGAATGTTCATCGAGATCGCTACCAGGTGTTGAGGAAATGGTATGCAACAGTTACGGGTGGTCAATATGGAGCAAAGGAACAGGCCTTGGTCAAGAAGTTTGTCCGAGTTAACAATTATGTTGTTTACAATCAGCAAGAGGCAGGGAAATATGAGAATCATTCTGAGAATGCCCTGATGTTGTATATGGCATGTACCCATGCCTCTAATCCAGTTTACGCTACTCTTAAGATTAGGATTTACTTCTACGATTCTGTAACCAACTGATATTAATAAATATCGAATTTTATTTCTGAATTCATGTCTACGTACACAGTTTGTTCTATTTTTTCCCATAATACATGGTTTACAGCTCTGATAATTGAATTAATTGAGATTACACCCAGATTGTTGAGATACTTGAGGATTTGTGTCTTGAATACCCTTAAGAAAAGACCAGTCGGAGGGCGTAAGGTCGTCCAGATTCGGTAGGTCAGAAAACCACTTGTGACTCCCAGAGCTCTCCGAAGGTTGTAGTTGAATTGGATTCTGATCTTTATTATGTCCGTTGTCATTGTGAATGGCCGGTTGTCGTGGCTGAGGATCTTGAAATAGAGGGGATTTGGAACCTCCCAGGTATAGGCGCCACTCCATGCTTGAGCTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGGTTGAAGCAGTTTATAGATAGAAAATAAGAACACCCGCATTCAAGATCGACTCTCCTCCTCCTGTGTACCCTCTTGGCTTCCCTGTGCTGTACTTTGATTGGAACCGGAGTACAGTGGTCCTTCGAGGGTGACGAAAATCGCATTTTTGAGAGCCCAATTCTTTAATGCTGTGTTCTTGTCCTCGTCGAGGAATTCTTTATAGCTGCTGTTAGGACCAGGATTGCATAAGAAGATTGTCGGTATGCCGCCTTTAATTTGAACTGGCTTCCCGTACTTAGTGTTGGACTGCCAGTCCCTTTGGGCCCCCATAAACTCCTTAAAGTGCTTGAGGAAGTGCGGGTCGACGTCATCAATGACGTTGTACCACGCGTCGTTACTATAGACTTTTGGGCTTAGATCCAAATGCCCACATAAATAGTTATGTGGGCCTAGAGACCTAGCCCACATTGTTTTCCCAGTACGACTATCTCCCTCAATTACTATACTTTGAGGTCTCAGGGGCCGCGCAGCGGCGTCGACAACATTCTCAGACACCCACTCTTCAAGTTCTTCTGGAACTTGATCGAAAGAAGAATAGGAAAAAGGAGAAACATAAGGAGCTGGAGGCTCCTGAAAGATCCTGTCTAGATTTGCATTTAAATTATGAAATTGTAGTACAAAATCTTTAGGAGCTAGTTCCTTAATGACTCTAAGAGCCTCTGACTTACTTCCCGCGTTAAGTGCTGCGGCGTAAGCGTCGTTGGCTGTTTGTTGCCCTCCTCTTGCTGATCTTCCGTCGATCTGAAATTCGCCCCAGTCGAGAATGTCCCCGTCCTTAGCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTGGTTGGGGATACGAGGTCGAAGAATCTGTTATTTTTGCATTTGTATTTGCCCTCGAACTGGATGAGCACGTGAAGATGAGGTTCCCCATTTTCATGAAACTCTCTGCAGATTCTAATGTATTTTTTGTTTACTGGTGTCTGTAGGTTTTGTAATTGGGAAAGTGCTTCCTCTTTAGTAAGAGAGCAAGTGGGATAAGTGAGGAAATAATTTTTGGCATATATCTGAAATTGTTTGGGAGGAGCCATTGACTTGGTCAATCGGTACCCAGATATAGTCTTATGTCAATTGGTGAACGGTACCCTATATATATTGGGTACTGAATGGCAATATTTGTAATTATGAAAATAAATTCAAAATCCTCACGCTCCAAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009508128.1
|
|
Location
|
130-477 |
|
Gene Name
|
av2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCACTTTTAAACGAGTTCCCCGAGACGGTTCACGGGTTTCGTTGCATGCTTGCGATAAAATACCTGCAACTGCTGTCTGAGGAATACTCTCCGGATACGGTAGGTTACGATTTAATTCGCGATTTAATTTCTATTTTACGATCTAGGAATTATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGGCGTCTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGTCCCCACTGTCCGCGTCACAAAATCACGCATGTGGGCGAACAGGCCCATGAACCGGAAGCCCAGAATGTACAGAATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPETVHGFRCMLAIKYLQLLSEEYSPDTVGYDLIRDLISILRSRNYVEASCRYRHFYPRVEGASASELRQPLCNPCSCPHCPRHKITHVGEQAHEPEAQNVQNVQKP |
|
NCBI Accession
|
YP_009508129.1
|
|
Location
|
290-1060 |
|
Gene Name
|
av1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGGCGTCTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGTCCCCACTGTCCGCGTCACAAAATCACGCATGTGGGCGAACAGGCCCATGAACCGGAAGCCCAGAATGTACAGAATGTACAGAAGCCCTGATGTTCCAAGAGGCTGTGAGGGTCCATGTAAGGTCCAATCCTTTGAGTCCAGACACGATGTAGTCCATATAGGTAAGGTCATGTGTATTAGTGATGTTACTCGCGGTACTGGGCTGACCCATAGAGTTGGGAAACGTTTCTGTGTTAAATCAGTCTATGTATTGGGTAAGATCTGGATGGATGAAAACATAAAGTCCAAAAACCACACTAACAATGTGATGTTCTTCTTGGTCCGTGATCGACGGCCTGTGGATAAGCCTCAGGATTTTGGAGAGGTCTTCAACATGTTCGACAACGAGCCCAGCACCGCTACTGTCAAGAATGTTCATCGAGATCGCTACCAGGTGTTGAGGAAATGGTATGCAACAGTTACGGGTGGTCAATATGGAGCAAAGGAACAGGCCTTGGTCAAGAAGTTTGTCCGAGTTAACAATTATGTTGTTTACAATCAGCAAGAGGCAGGGAAATATGAGAATCATTCTGAGAATGCCCTGATGTTGTATATGGCATGTACCCATGCCTCTAATCCAGTTTACGCTACTCTTAAGATTAGGATTTACTTCTACGATTCTGTAACCAACTGA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPYATRAVVPTVRVTKSRMWANRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKSKNHTNNVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWYATVTGGQYGAKEQALVKKFVRVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
|
NCBI Accession
|
YP_009508130.1
|
|
Location
|
1063-1467 |
|
Gene Name
|
ac3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCATGGAGTGGCGCCTATACCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCCTCAGCCACGACAACCGGCCATTCACAATGACAACGGACATAATAAAGATCAGAATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTCACAAGTGGTTTTCTGACCTACCGAATCTGGACGACCTTACGCCCTCCGACTGGTCTTTTCTTAAGGGTATTCAAGACACAAATCCTCAAGTATCTCAACAATCTGGGTGTAATCTCAATTAATTCAATTATCAGAGCTGTAAACCATGTATTATGGGAAAAAATAGAACAAACTGTGTACGTAGACATGAATTCAGAAATAAAATTCGATATTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAAQAWSGAYTWEVPNPLYFKILSHDNRPFTMTTDIIKIRIQFNYNLRRALGVTSGFLTYRIWTTLRPPTGLFLRVFKTQILKYLNNLGVISINSIIRAVNHVLWEKIEQTVYVDMNSEIKFDIY |
|
NCBI Accession
|
YP_009508131.1
|
|
Location
|
1160-1612 |
|
Gene Name
|
ac2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCGATTTTCGTCACCCTCGAAGGACCACTGTACTCCGGTTCCAATCAAAGTACAGCACAGGGAAGCCAAGAGGGTACACAGGAGGAGGAGAGTCGATCTTGAATGCGGGTGTTCTTATTTTCTATCTATAAACTGCTTCAACCATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCATGGAGTGGCGCCTATACCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCCTCAGCCACGACAACCGGCCATTCACAATGACAACGGACATAATAAAGATCAGAATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTCACAAGTGGTTTTCTGACCTACCGAATCTGGACGACCTTACGCCCTCCGACTGGTCTTTTCTTAAGGGTATTCAAGACACAAATCCTCAAGTATCTCAACAATCTGGGTGTAATCTCAATTAA |
|
Protein Sequence
|
MRFSSPSKDHCTPVPIKVQHREAKRVHRRRRVDLECGCSYFLSINCFNHGFTHRGTHHCSSSMEWRLYLGGSKSPLFQDPQPRQPAIHNDNGHNKDQNPIQLQPSESSGSHKWFSDLPNLDDLTPSDWSFLKGIQDTNPQVSQQSGCNLN |
|
NCBI Accession
|
YP_009508132.1
|
|
Location
|
1509-2600 |
|
Gene Name
|
ac1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGGCTCCTCCCAAACAATTTCAGATATATGCCAAAAATTATTTCCTCACTTATCCCACTTGCTCTCTTACTAAAGAGGAAGCACTTTCCCAATTACAAAACCTACAGACACCAGTAAACAAAAAATACATTAGAATCTGCAGAGAGTTTCATGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAGGGCAAATACAAATGCAAAAATAACAGATTCTTCGACCTCGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGCTAAGGACGGGGACATTCTCGACTGGGGCGAATTTCAGATCGACGGAAGATCAGCAAGAGGAGGGCAACAAACAGCCAACGACGCTTACGCCGCAGCACTTAACGCGGGAAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAACTAGCTCCTAAAGATTTTGTACTACAATTTCATAATTTAAATGCAAATCTAGACAGGATCTTTCAGGAGCCTCCAGCTCCTTATGTTTCTCCTTTTTCCTATTCTTCTTTCGATCAAGTTCCAGAAGAACTTGAAGAGTGGGTGTCTGAGAATGTTGTCGACGCCGCTGCGCGGCCCCTGAGACCTCAAAGTATAGTAATTGAGGGAGATAGTCGTACTGGGAAAACAATGTGGGCTAGGTCTCTAGGCCCACATAACTATTTATGTGGGCATTTGGATCTAAGCCCAAAAGTCTATAGTAACGACGCGTGGTACAACGTCATTGATGACGTCGACCCGCACTTCCTCAAGCACTTTAAGGAGTTTATGGGGGCCCAAAGGGACTGGCAGTCCAACACTAAGTACGGGAAGCCAGTTCAAATTAAAGGCGGCATACCGACAATCTTCTTATGCAATCCTGGTCCTAACAGCAGCTATAAAGAATTCCTCGACGAGGACAAGAACACAGCATTAAAGAATTGGGCTCTCAAAAATGCGATTTTCGTCACCCTCGAAGGACCACTGTACTCCGGTTCCAATCAAAGTACAGCACAGGGAAGCCAAGAGGGTACACAGGAGGAGGAGAGTCGATCTTGA |
|
Protein Sequence
|
MAPPKQFQIYAKNYFLTYPTCSLTKEEALSQLQNLQTPVNKKYIRICREFHENGEPHLHVLIQFEGKYKCKNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIAKDGDILDWGEFQIDGRSARGGQQTANDAYAAALNAGSKSEALRVIKELAPKDFVLQFHNLNANLDRIFQEPPAPYVSPFSYSSFDQVPEELEEWVSENVVDAAARPLRPQSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEDKNTALKNWALKNAIFVTLEGPLYSGSNQSTAQGSQEGTQEEESRS |
|
NCBI Accession
|
YP_009508133.1
|
|
Location
|
2141-2449 |
|
Gene Name
|
ac4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAGGGCAAATACAAATGCAAAAATAACAGATTCTTCGACCTCGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGCTAAGGACGGGGACATTCTCGACTGGGGCGAATTTCAGATCGACGGAAGATCAGCAAGAGGAGGGCAACAAACAGCCAACGACGCTTACGCCGCAGCACTTAACGCGGGAAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAACTAG |
|
Protein Sequence
|
MKMGNLIFTCSSSSRANTNAKITDSSTSYPQPGQHISIQTFRELNPAPTSSPTSLRTGTFSTGANFRSTEDQQEEGNKQPTTLTPQHLTREVSQRLLESLRN |