Hibiscus golden mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_013088435.1 |
| Isolate |
Brazil |
| Release date |
2021/6/1 |
| Submitter |
Quadros,A.F., Silva,J.P., Xavier,C.A., Zerbini,F.M., Boari,A.J., Quadros,A.F.F., Xavier,C.A.D., Zerbini,F.M. Jr. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
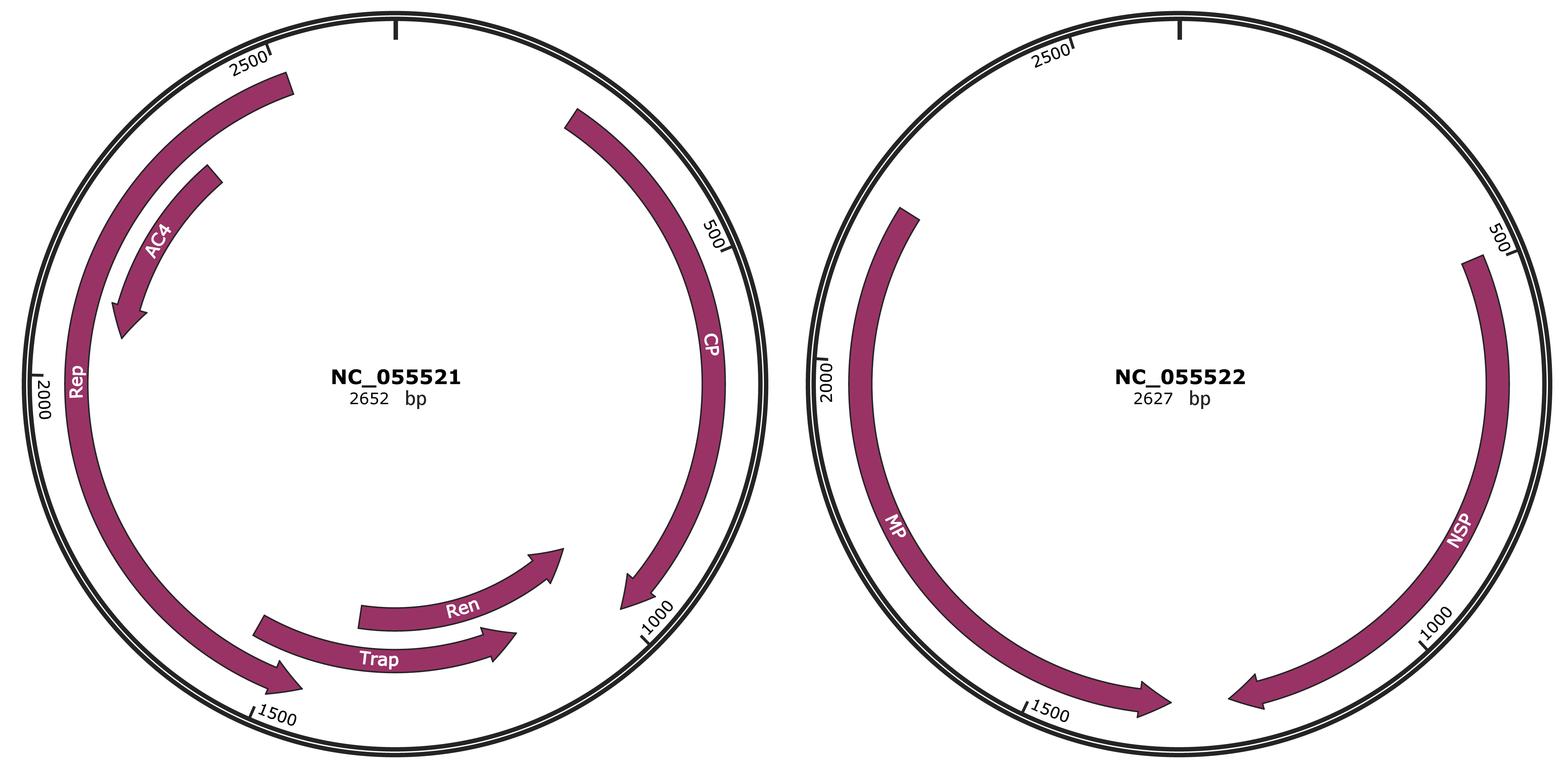
JBrowse
Genome
ACACCGGATGGCCGCGCGATTTTTTGTACGGACTCAAGGAAGGTAACGTGGCGCGCGCAGGACCGCGCGATGAATTTAAGTTAAAGCCGCGTACTCGCGATAACCGTTGGATTAAAGGGGGTCGGTGGATATTGGGCCAATCATATTGGGCCCTCAGAGCTTAAATTCATTTGAAATGCTTAGGCGCGAAGTACTTGGTCGACCGTTATAAAATGAAGGCTCATACTTGAACAGGCTTTAATTCAAAATGCCTAAGCGCGATGCCCCGTGGCGTTTAATGGCGGGAACTTCGAAAGTTAGCCGCTCTTCTAATTCTCCTCGTGTTGGGCCCAAGGTGAATAAGGCCACGGAATGGGTTCACAGACCCATGTACAGGAAACCTAGAATTTATCGGGCCTATAGAACCCCCGATGTACCTCGAGGATGTGAAGGACCATGCAAGGTTCAGTCCTATGAACAACGCCATGATATCTCTCACACTGGGAAGGTCATGTGTATATCCGATGTGACTCGAGGTAACGGTATTACGCATCGTGTGGGTAAGCGTTTTTGTGTCAAGTCTGTGTATATTCTGGGTAAGATATGGATGGATGAGAACATCAAACTGAAGAACCACACGAACAGCGTCATGTTCTGGTTAGTTAGGGATAGGAGACCCTATGGCACACCTATGGACTTTGGGCAAGTGTTCAACATGTTTGACAATGAACCCAGTACCGCGACTGTGAAGAACGATCTTAGAGATCGTTTCCAAGTTATGCACAAGTTCTATGGTAAGGTGACCGGTGGTCAATATGCTAGCAACGAACAGGCTATAGTGAAGCGGTTCTGGAAGGTCAATAATCATGTGGTGTACAATCACCAGGAAGCTGGAAAATACGAGAATCACACTGAGAATGCGTTATTATTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTCAAGATTCGGATCTATTTCTATGATTCGATAACTAATTAATAAAATTTGAATTTTATTGAATGACTGTCCAGTACATGATGAACATATGACCTATCTGTTGCGAAACGAACAGCTCTAATTACATTGTTAAGACAGATAACCCCTAACTTATCAAGATAAAACTGAACAAGATATTTAAATCTATTTAAATATGTCGTCCCAGAAGCTGTCACTGATGTCGTCCAAATTTGGAAGTTCAGGTAAGCCTTGTGGAGATGCAACGCTTTCCTCAGGTTGTGGTTGAAGCGTATTTGGATGTGGTACACCCGGGTTTTTGTGTATCTCAGGTCCTCTACTCGGTACATCTTGAAATACAGGGGATTTGGAACCTCCCATGTATAGACGCCACTCTCCGCCTGATGAGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGATCAACACAGTTGATATGTCTGTATATGGAGCACCCGCACGCTAGATCAATGCGTCTTCTCCTAACTGCCCTCTTCTTGCGCCGTTTGATAGAGGGGAGAGTCGAGGAAGATGAATTTTGCATTATGGAGTGTCCACGACTTAAGAGACGCATTGTCTGGTTTCTCGAGGAAATCTTTATAGCTGGCCCCCTCACCAGGATTGCAAAGCACGATTGATGGGATACCTCCTTTAATTTGAACTGGCTTGCCGTATTTACAATTTGACTGCCAGTCTCTTTGGGCCCCGATCAACTCTTTCCAGTGCTTTAGCTTTAGATAGTGCGGTGCGACGTCATCTATGACGTTATACTCAACGTCATTCGAGAAAACCCTAGAATTGAAATCCAGGTGTCCACTCAGATAGTTATGCACGCCTAACGCACGTGCCCACATCGTCTTCCCCGTTCGCGAACTACCCTCGATGATGATACTGAGTGGCCTCTCCGGCCGCGCAGCGGCACCTCTCCCAAAATAAGAATCGACCCACTCTTGCATCTCGACAGGCACTTCTGTGAATGAGGAGAGGTGGAACCGAGGGACCCATGGCTCTGGAACTTTAGCAAAGATCCTCTCTGCATTAGCCAAGAGATTATGAAAATTAGAAAAATAATCCCTCGGTTGTTCCTCTTTTAGTACTCGAAGTGCTTCTGTAACTGATCCTGAGTTGAGTGCCTTTGCATACGACTCGTTAACCGTCTGCTGACCTCCTCGAGCACTTCGACTGTCGATCTGGAACTCTCCCCATTCGAGAACATCACCGTCTTTGTCGACGTAGGACTTGACGTCGGAGCTAGACTTTGCTCCCTGATAGTTCCCATGGAACTGGGCTGAACTTGATGGGGAGACCAGATCGAAGAATCTCTTATTTGTCGTCTGTAATTTCCCTTCGAACTGAAGCAGCACATGGATATGAGGCTCTCCATTTTCGTGTAATTCTCTGCAAATCTTGATGAATTTTTTGTTGACAGCTGTTTCTAACCCTAATAATTGGGAAAGGACCTGTTCTTTGGTTAAAGAACATTTGGGATAAGTGAGGAAAAAATTCTTGGCATATAAATTGAAAGAACCCTTGCGTGGCATTTTTGTAAATAGGGTATGTTCCACCGATTGCTCCTCTCAAAACTATACGAATGTATCGGTGGAACGGTGGTACATTTATATGTTCCACCAGAACCCTCATAAAGGCTCTTAGGGACACGTGGCGGCCATCCGCTATAATATT
ACCGGATGGCCGCGCGAAATTTTCCCCCGCTGACGTGGCGCGCTGCTCACCGCTCGATTTTGGAAAGGAGGCTACGTGGCTCTCGCAGAGTCGCGCGATAAATTTAACTAAGCGTGTTTTTGAAGTCCGCCAATTTAGTTGAGCGCTATTTTGAAGTCCGCGCGAACAGTTTCACCCATTGGAGTCTATTATCGCGCTGAGAATGTGGGTCCCTCCAACCCTTTTTATTTTAGACCGTTAGCTATGAATAAATAAATCTCCCAGATTTATTAAGTGATTTGAATTAAAGTGGCGGGTCCTGCCATTCTGACACATTTGTACAGGCGGTCTAAAATAACTCGTTGAATAGGAAGCTTTACCATATCCAATTAAATAACGCTGTGAAAATAATTGACATTATTTTTCTCCATGGAATTTTATATATATAAATTCATCCGTGATATACTTGCTAAGCAATAATTTGTAATTATTGACGTATAGGATTTGGATATGTATTGGAGGAGATATAAACGTGGCTCGTCGTCTACGTATCGTCGTAATCCTTCATACAAGCGTTCGTATGTGTCGAGACGCACTGATGGGAGACGTCGACCTAGCAATTCGAACAAACCCCATGATGATCCTAAGATGGCAGTCCAACGGATACATGAGAACCAGTTCGGACCTGAATTTGTTATGGCTAACAATTCAGCCATATCGACCTACATAACCTATCCGTCCATTCGCAAGACCGAACCTAACCGGTGTAGATCATATATCAAGTTGAAACGACTCCGTTTCAAAGGTACAGTGAAGATAGAACGAACCCATGCTGATGTGAACATGGACGGTCTTGCTCCAAAGATTGAAGGCGTGTTCTCTCTAATAATTGTGGTTGATTGTAAACCACACCTAGGTGCATCTGGGACTCTCCATACATTTGACGAGTTATTTGGTGCCAGAATCAACAGCCATGGTAACCTGGCCATTGTACCTGATTTGAGGGATCGTTTCTACATACGACATGTGCTGAAACGTGTATTGTCTGTGGAGAAGGACTCTCTTATGGTGGATTTGGAAGGAACGTCTTATTTCACTAACAGGCGTTTTAATTGCTGGGCTAATTTTAGGGATAACGATCATGACTCATGTAACGGTGTATATGCCAACATAAACAAGAACGCCCTGTTAGTTTATTACTGCTGGATGTCGGATGTTATGTCCAAGGCATCGACATTTGTATCGTTTGATCTCGATTATGTTGGTTAATACTATGAGAATTATGGAAATAATTCATTTTGAACAAGAAATTAATGGATATTAATTCATACTAACCAAATACAACTTATTGCAAAGATTTAGGCTCCGCAGGAGCACCGTTGGTTTTAATACACTCATGGACCGTCGCTCTCACGATTTCGCTTAATTGGGCCACCGATAACGTTAAATTCGATTGCGCCCGCTGGGCCCCAACAATCGAAGCAGACTCTCCTGGGTCTAAGATGGTGGTTCCCAATCTGTTTAGTTCTCTATAAGGATGGGCCTCCTCTCTCAGATCAGAGTCTATACAAGAGTTGTTTGGGCCAACTGTACTCCTGACAGCCCAAGACTCTCCTGGGTTTAGTTCAATTGGGCTGGGAAGCCCTAATCTTGCTGAGGACACTGATCTGATTAGTTTTCTTTCCCATCTCCCGTAACCCACATGCGAGAAATCTATATCCCTATCTGTGAACTGTTTGGACAAGATCTTAACTGTTGGAGCCCGGAAGGGGATATCTACCGAATGTTTAGCTGTGGACAGCTTTAACTTCCCTTTGAACTTAGCGAAGTGGGTCCTTTGATGAACATTCGTGTCGCAAACCCTATAATACAGCTTCCATGGAATTGGGTCTTTGAGGGAGAAGAATGATGAGGAGAAATAGTGGAGATCTATGTTGCATCTGATCGGGAAAGTCCATGACGCCTGCAATGATTCGTTATCAGTCATTCTTCTATCATGAATCTCCACTATGACTGACCCAGTAGCGTTGATGGGAACCTGTTGCCTGTACTCGATAACACAATGATCAATCTTCATACAGCTACGACTAAGTCTGGCGCTTATCTGAGACGCCGCTGAAGGGAACTGCAAGATGATCTCTGTTAGATCATGCGACAACTGATACTCATCTCTATGTGATTCTATGTAGTTGAAGGCGTCTGGAGGATTAATTAACTGAGAACCCATTCTAACGCTAAGGAATTATTTGATAATTGAACGTGGGAGAAGAACTGGTAGTGAAGGTTCAACTGAAAGAAGAACTGAGAAAAACCCTAATTTTTGAAGAAGAGAAAGGAAGAGGTTAAATCAAATTTAACCTGGTTAACTATTAAATTGCCTAAGTTTTTCGAAGTGTTGAACTGATTAAGAGAATGGGTTAATATTTACAACTATGTTGGAAGGAGTCTGTGACGAGTTTATGGATATTAACTGGGTTTAAATAGGAAATGCTATGCGGAGTGGCATAGTTGTAAATAGGCTATGTTCCACCGATTGCTCCTCTCAAAACTATACGAATGTATCGGTGGAACGGTGGTACATTTATATGTTCCACCAGAACCCTCATAAAGGCTCTTAGGGACACGTGGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_010087231.1
|
|
Location
|
248-994 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATGCCCCGTGGCGTTTAATGGCGGGAACTTCGAAAGTTAGCCGCTCTTCTAATTCTCCTCGTGTTGGGCCCAAGGTGAATAAGGCCACGGAATGGGTTCACAGACCCATGTACAGGAAACCTAGAATTTATCGGGCCTATAGAACCCCCGATGTACCTCGAGGATGTGAAGGACCATGCAAGGTTCAGTCCTATGAACAACGCCATGATATCTCTCACACTGGGAAGGTCATGTGTATATCCGATGTGACTCGAGGTAACGGTATTACGCATCGTGTGGGTAAGCGTTTTTGTGTCAAGTCTGTGTATATTCTGGGTAAGATATGGATGGATGAGAACATCAAACTGAAGAACCACACGAACAGCGTCATGTTCTGGTTAGTTAGGGATAGGAGACCCTATGGCACACCTATGGACTTTGGGCAAGTGTTCAACATGTTTGACAATGAACCCAGTACCGCGACTGTGAAGAACGATCTTAGAGATCGTTTCCAAGTTATGCACAAGTTCTATGGTAAGGTGACCGGTGGTCAATATGCTAGCAACGAACAGGCTATAGTGAAGCGGTTCTGGAAGGTCAATAATCATGTGGTGTACAATCACCAGGAAGCTGGAAAATACGAGAATCACACTGAGAATGCGTTATTATTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTCAAGATTCGGATCTATTTCTATGATTCGATAACTAATTAA |
|
Protein Sequence
|
MPKRDAPWRLMAGTSKVSRSSNSPRVGPKVNKATEWVHRPMYRKPRIYRAYRTPDVPRGCEGPCKVQSYEQRHDISHTGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_010087232.1
|
|
Location
|
991-1389 |
|
Gene Name
|
Ren |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCTCATCAGGCGGAGAGTGGCGTCTATACATGGGAGGTTCCAAATCCCCTGTATTTCAAGATGTACCGAGTAGAGGACCTGAGATACACAAAAACCCGGGTGTACCACATCCAAATACGCTTCAACCACAACCTGAGGAAAGCGTTGCATCTCCACAAGGCTTACCTGAACTTCCAAATTTGGACGACATCAGTGACAGCTTCTGGGACGACATATTTAAATAGATTTAAATATCTTGTTCAGTTTTATCTTGATAAGTTAGGGGTTATCTGTCTTAACAATGTAATTAGAGCTGTTCGTTTCGCAACAGATAGGTCATATGTTCATCATGTACTGGACAGTCATTCAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAHQAESGVYTWEVPNPLYFKMYRVEDLRYTKTRVYHIQIRFNHNLRKALHLHKAYLNFQIWTTSVTASGTTYLNRFKYLVQFYLDKLGVICLNNVIRAVRFATDRSYVHHVLDSHSIKFKFY |
|
NCBI Accession
|
YP_010087233.1
|
|
Location
|
1136-1543 |
|
Gene Name
|
Trap |
|
Protein Name
|
trans-activating protein |
|
Coding Region
|
ATGCGTCTCTTAAGTCGTGGACACTCCATAATGCAAAATTCATCTTCCTCGACTCTCCCCTCTATCAAACGGCGCAAGAAGAGGGCAGTTAGGAGAAGACGCATTGATCTAGCGTGCGGGTGCTCCATATACAGACATATCAACTGTGTTGATCATGGATTCACGCACAGGGGAACTCATCACTGCTCATCAGGCGGAGAGTGGCGTCTATACATGGGAGGTTCCAAATCCCCTGTATTTCAAGATGTACCGAGTAGAGGACCTGAGATACACAAAAACCCGGGTGTACCACATCCAAATACGCTTCAACCACAACCTGAGGAAAGCGTTGCATCTCCACAAGGCTTACCTGAACTTCCAAATTTGGACGACATCAGTGACAGCTTCTGGGACGACATATTTAAATAG |
|
Protein Sequence
|
MRLLSRGHSIMQNSSSSTLPSIKRRKKRAVRRRRIDLACGCSIYRHINCVDHGFTHRGTHHCSSGGEWRLYMGGSKSPVFQDVPSRGPEIHKNPGVPHPNTLQPQPEESVASPQGLPELPNLDDISDSFWDDIFK |
|
NCBI Accession
|
YP_010087234.1
|
|
Location
|
1452-2510 |
|
Gene Name
|
Rep |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACGCAAGGGTTCTTTCAATTTATATGCCAAGAATTTTTTCCTCACTTATCCCAAATGTTCTTTAACCAAAGAACAGGTCCTTTCCCAATTATTAGGGTTAGAAACAGCTGTCAACAAAAAATTCATCAAGATTTGCAGAGAATTACACGAAAATGGAGAGCCTCATATCCATGTGCTGCTTCAGTTCGAAGGGAAATTACAGACGACAAATAAGAGATTCTTCGATCTGGTCTCCCCATCAAGTTCAGCCCAGTTCCATGGGAACTATCAGGGAGCAAAGTCTAGCTCCGACGTCAAGTCCTACGTCGACAAAGACGGTGATGTTCTCGAATGGGGAGAGTTCCAGATCGACAGTCGAAGTGCTCGAGGAGGTCAGCAGACGGTTAACGAGTCGTATGCAAAGGCACTCAACTCAGGATCAGTTACAGAAGCACTTCGAGTACTAAAAGAGGAACAACCGAGGGATTATTTTTCTAATTTTCATAATCTCTTGGCTAATGCAGAGAGGATCTTTGCTAAAGTTCCAGAGCCATGGGTCCCTCGGTTCCACCTCTCCTCATTCACAGAAGTGCCTGTCGAGATGCAAGAGTGGGTCGATTCTTATTTTGGGAGAGGTGCCGCTGCGCGGCCGGAGAGGCCACTCAGTATCATCATCGAGGGTAGTTCGCGAACGGGGAAGACGATGTGGGCACGTGCGTTAGGCGTGCATAACTATCTGAGTGGACACCTGGATTTCAATTCTAGGGTTTTCTCGAATGACGTTGAGTATAACGTCATAGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAGTTGATCGGGGCCCAAAGAGACTGGCAGTCAAATTGTAAATACGGCAAGCCAGTTCAAATTAAAGGAGGTATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGGGCCAGCTATAAAGATTTCCTCGAGAAACCAGACAATGCGTCTCTTAAGTCGTGGACACTCCATAATGCAAAATTCATCTTCCTCGACTCTCCCCTCTATCAAACGGCGCAAGAAGAGGGCAGTTAG |
|
Protein Sequence
|
MPRKGSFNLYAKNFFLTYPKCSLTKEQVLSQLLGLETAVNKKFIKICRELHENGEPHIHVLLQFEGKLQTTNKRFFDLVSPSSSAQFHGNYQGAKSSSDVKSYVDKDGDVLEWGEFQIDSRSARGGQQTVNESYAKALNSGSVTEALRVLKEEQPRDYFSNFHNLLANAERIFAKVPEPWVPRFHLSSFTEVPVEMQEWVDSYFGRGAAARPERPLSIIIEGSSRTGKTMWARALGVHNYLSGHLDFNSRVFSNDVEYNVIDDVAPHYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLEKPDNASLKSWTLHNAKFIFLDSPLYQTAQEEGS |
|
NCBI Accession
|
YP_010087235.1
|
|
Location
|
2060-2353 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGAGAGCCTCATATCCATGTGCTGCTTCAGTTCGAAGGGAAATTACAGACGACAAATAAGAGATTCTTCGATCTGGTCTCCCCATCAAGTTCAGCCCAGTTCCATGGGAACTATCAGGGAGCAAAGTCTAGCTCCGACGTCAAGTCCTACGTCGACAAAGACGGTGATGTTCTCGAATGGGGAGAGTTCCAGATCGACAGTCGAAGTGCTCGAGGAGGTCAGCAGACGGTTAACGAGTCGTATGCAAAGGCACTCAACTCAGGATCAGTTACAGAAGCACTTCGAGTACTAA |
|
Protein Sequence
|
MESLISMCCFSSKGNYRRQIRDSSIWSPHQVQPSSMGTIREQSLAPTSSPTSTKTVMFSNGESSRSTVEVLEEVSRRLTSRMQRHSTQDQLQKHFEY |
|
NCBI Accession
|
YP_010087236.1
|
|
Location
|
490-1248 |
|
Gene Name
|
NSP |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATTGGAGGAGATATAAACGTGGCTCGTCGTCTACGTATCGTCGTAATCCTTCATACAAGCGTTCGTATGTGTCGAGACGCACTGATGGGAGACGTCGACCTAGCAATTCGAACAAACCCCATGATGATCCTAAGATGGCAGTCCAACGGATACATGAGAACCAGTTCGGACCTGAATTTGTTATGGCTAACAATTCAGCCATATCGACCTACATAACCTATCCGTCCATTCGCAAGACCGAACCTAACCGGTGTAGATCATATATCAAGTTGAAACGACTCCGTTTCAAAGGTACAGTGAAGATAGAACGAACCCATGCTGATGTGAACATGGACGGTCTTGCTCCAAAGATTGAAGGCGTGTTCTCTCTAATAATTGTGGTTGATTGTAAACCACACCTAGGTGCATCTGGGACTCTCCATACATTTGACGAGTTATTTGGTGCCAGAATCAACAGCCATGGTAACCTGGCCATTGTACCTGATTTGAGGGATCGTTTCTACATACGACATGTGCTGAAACGTGTATTGTCTGTGGAGAAGGACTCTCTTATGGTGGATTTGGAAGGAACGTCTTATTTCACTAACAGGCGTTTTAATTGCTGGGCTAATTTTAGGGATAACGATCATGACTCATGTAACGGTGTATATGCCAACATAAACAAGAACGCCCTGTTAGTTTATTACTGCTGGATGTCGGATGTTATGTCCAAGGCATCGACATTTGTATCGTTTGATCTCGATTATGTTGGTTAA |
|
Protein Sequence
|
MYWRRYKRGSSSTYRRNPSYKRSYVSRRTDGRRRPSNSNKPHDDPKMAVQRIHENQFGPEFVMANNSAISTYITYPSIRKTEPNRCRSYIKLKRLRFKGTVKIERTHADVNMDGLAPKIEGVFSLIIVVDCKPHLGASGTLHTFDELFGARINSHGNLAIVPDLRDRFYIRHVLKRVLSVEKDSLMVDLEGTSYFTNRRFNCWANFRDNDHDSCNGVYANINKNALLVYYCWMSDVMSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_010087237.1
|
|
Location
|
1325-2206 |
|
Gene Name
|
MP |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGGTTCTCAGTTAATTAATCCTCCAGACGCCTTCAACTACATAGAATCACATAGAGATGAGTATCAGTTGTCGCATGATCTAACAGAGATCATCTTGCAGTTCCCTTCAGCGGCGTCTCAGATAAGCGCCAGACTTAGTCGTAGCTGTATGAAGATTGATCATTGTGTTATCGAGTACAGGCAACAGGTTCCCATCAACGCTACTGGGTCAGTCATAGTGGAGATTCATGATAGAAGAATGACTGATAACGAATCATTGCAGGCGTCATGGACTTTCCCGATCAGATGCAACATAGATCTCCACTATTTCTCCTCATCATTCTTCTCCCTCAAAGACCCAATTCCATGGAAGCTGTATTATAGGGTTTGCGACACGAATGTTCATCAAAGGACCCACTTCGCTAAGTTCAAAGGGAAGTTAAAGCTGTCCACAGCTAAACATTCGGTAGATATCCCCTTCCGGGCTCCAACAGTTAAGATCTTGTCCAAACAGTTCACAGATAGGGATATAGATTTCTCGCATGTGGGTTACGGGAGATGGGAAAGAAAACTAATCAGATCAGTGTCCTCAGCAAGATTAGGGCTTCCCAGCCCAATTGAACTAAACCCAGGAGAGTCTTGGGCTGTCAGGAGTACAGTTGGCCCAAACAACTCTTGTATAGACTCTGATCTGAGAGAGGAGGCCCATCCTTATAGAGAACTAAACAGATTGGGAACCACCATCTTAGACCCAGGAGAGTCTGCTTCGATTGTTGGGGCCCAGCGGGCGCAATCGAATTTAACGTTATCGGTGGCCCAATTAAGCGAAATCGTGAGAGCGACGGTCCATGAGTGTATTAAAACCAACGGTGCTCCTGCGGAGCCTAAATCTTTGCAATAA |
|
Protein Sequence
|
MGSQLINPPDAFNYIESHRDEYQLSHDLTEIILQFPSAASQISARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDRRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDRDIDFSHVGYGRWERKLIRSVSSARLGLPSPIELNPGESWAVRSTVGPNNSCIDSDLREEAHPYRELNRLGTTILDPGESASIVGAQRAQSNLTLSVAQLSEIVRATVHECIKTNGAPAEPKSLQ |