Euphorbia yellow leaf curl virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_003029205.1 |
| Isolate |
Pakistan |
| Release date |
2018/8/26 |
| Submitter |
Riaz,H., Ashfaq,M. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
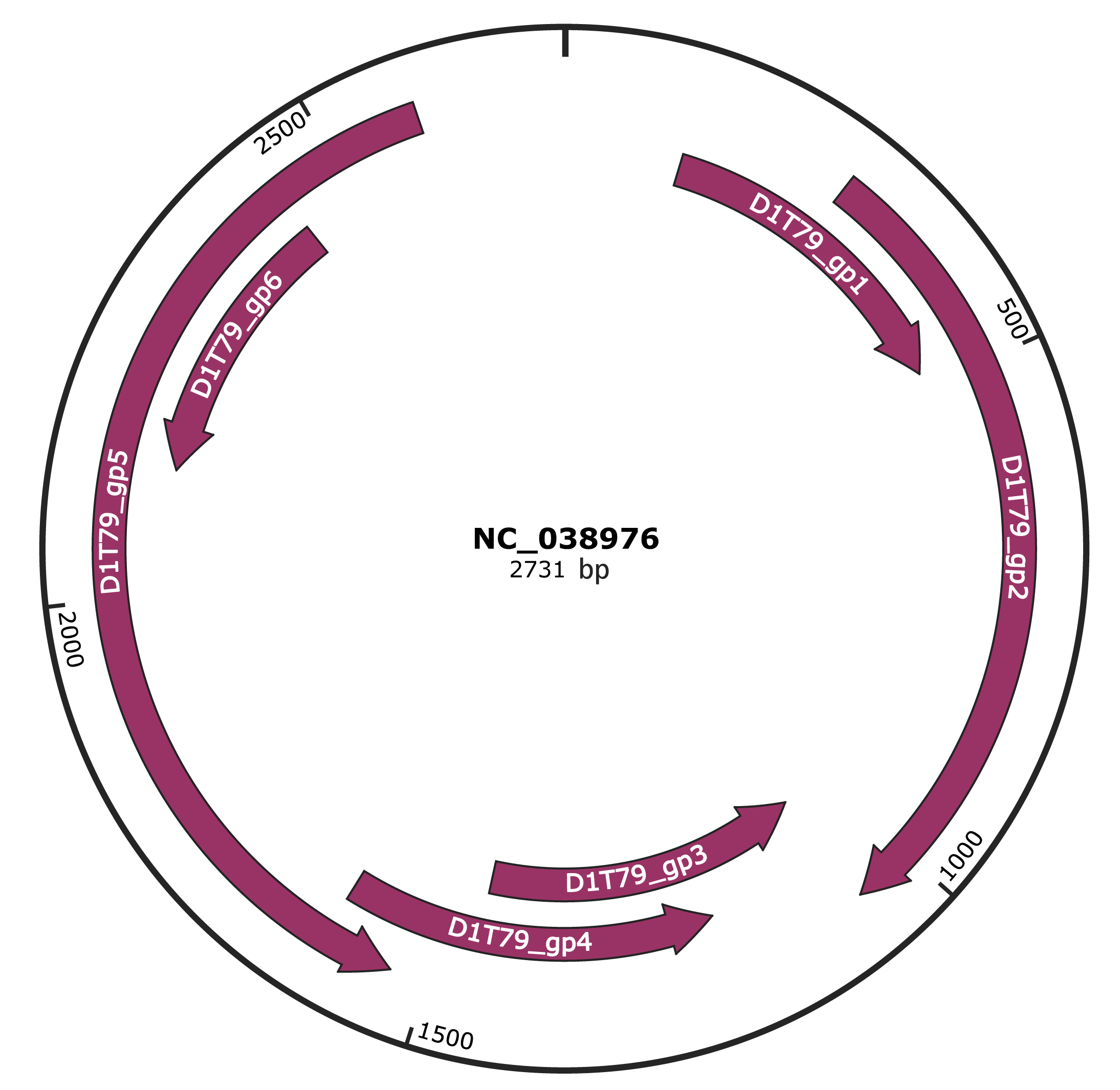
JBrowse
Genome
ACCGGATGGCCGCGTTTTTTTTTGTGGCCCCCAGAAAGCACTAACTGACAATGACATGTGGACCAATGAGAATCCTTTCTCATAGCCTGATTATTTCATGGTCCCCCCTATAACTTAGTGCGCAAGTATGTGGGATCCATTAGTAAACGAGTTTCCCGAAACCGTTCACGGTTTTCGATGTATGTTGGCAGTGAAATATCTCCAACTAGTTGCGGATACGTATTCCCCAGATACGGTGGGATACGATTTAATACGTGATTTAATTTGTATTCTACGTTCCAGGAATTATGTCGAAGCGCAAAGCAGATATAATCATTTCCACCCCAGGCTCGAAGGTTCGACGGAGGCTGAACTTCGACAGTCCAGGATCGAGCCGTGCTTATGTCCCTACTGTCCGCGTCACCAAATCAAGTCTATGGGCCAACAGACCCATGAACAGAAAGCCCAGGATGTACAGGATGTACAGAAGTCCAGATGTCCCTAGAGGATGTGAAGGCCCATGTAAGGTCCAGTCGTTTGAGTCCAGACATGATATTCAGCATATAGGTAAAGTTATGTGTGTCAGTGATGTTACGCGTGGAACTGGGCTGACCCATCGAGTGGGTAAAAGGTTTTGTGTTAAATCTGTTTATGTATTGGGCAAGATCTGGATGGACGAGAATATTAAGACCAAAAATCACACGAATAGTGTGATGTTTTTTTTAGTTAGGGATCGTAGACCCGTTGACAAGCCTCAAGATTTTGGTGAGGTTTTTAACATGTTTGATAATGAGCCCAGCACCGCGACTGTGAAGAATGTTCATCGTGATAGATACCAGGTATTAAGGAAGTGGCATGCAACTGTGACTGGTGGACAATATGCATCGAAGGAGCAGGCTCTCGTGAAGAAGTTTATTAGGGTTAATAATTATGTTGTGTACAACCAGCAAGAGGCTGGCAAGTATGAGAATCATTCTGAGAATGCGTTGATGTTGTATATGGCGTGTACGCACGCTTCTAATCCTGTGTATGCTACATTAAAGATACGGATCTACTTCTACGATTCAGTATCGAATTAATAAAGATTGAATTTTATTGAAGATGATTGTTCTACATATACAACATGATGTAATACATCCCATAATACATGATCAACTGCTCTAATGACATTGTTAATACTGATAACTCCTAAATTATCTAAATACTTAATAACTTGGGTCTTAAAGACCCTTAAGAAATGACCAGTCGGAGGCTGTGAGGTCGTCCAGATTCGGAAGGCTAGGAAACATTTGTGAATCCCCAGTGCTTTCCTCAGGTTGTGATTGAACTGTATCTGGACGGTGATGATGTCTTGGTTCATGAGAAATGGCCGGTTGTGGTGCTCTAAGATCTTGAAATAGAGGGGATTTTGAATCTTCCAGATATACACGCCATTCACTGCTTGAGCTGCAGTGATGGGTTCCCCGGTGCGTGAATCCATGGTTGTGGCAGTTGATGTGTACGTAGTATGAGCACCCACAGTTTAGATCAACCCTCTTACGCCGGATGGCTCTACGCTTAGCAGCTCTGTGTTGGACCTTGATTGGTACCTGAGTAGAGTGGGCTCTCGAGGGTGATGAATGTCGCATTCTTTAAAGCCCAATTTTTCAGTGCAGAATTCTTCTCTTCGTCCAAGAACTCTTTATAGCTTGAGTTGGGTCCTGGATTGCAGAGGAAGATAGTGGGAATGCCGCCTTTAATTTGAACTGGCTTTCCGTATTTCGTGTTGCTTTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTAAAGTGCTTTAGGTAGTGGGGATCTACGTCATCAATCACGTTGTACCAGGCCTCGTTGCTGTAAACCTTAGGACTAAGGTCTAGATGACCACACAGGTAATTATGTGGACCCAAAGACCTAGCCCACATGGTCTTCCCCGTACGACTATCACCCTCTATGACAATACTTTTGGGTCTCAAAGGCCGCGCAGCGGCACCCATCACATTTTCAGACGCCCATTCCTCTATGGGCTGTGGAACTTGATCGAAGGAAGAAGAAGTAAAAGGAGAAACATAAACCTCCAGAGGAGGTGTGAAAATCCTATCTAAATTGGCATTTAAATTATGAAATTGTAATACATAATCCTTTGGAGCTAACTCCTTAATGACTCTGAGAGCCTCTGACTTACTGCCTGTGTTAAGCGCTGCGGCGTAAGCGTCGTTGGCCGTCTGTTGACCTCCTCTAGCAGATCGTCCGTCGATCTGAAACTCTCCCCATTCGAGGGTATCTCCGTCCTTCTCCAGATAGGACTTGACGTCCGAGCTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGATACCAGGTCGAAGAATCTGTTATTCGTGCACTGGTACTTCCCTTCGAACTGGATGAGCACGTGAAGATGAGGTTCCCCATTTTCGTGGAGCTCTCTGCAGATCTTTATGTATTTTTTGTTTACTGGGGTTTGTAGGTTTTCTAATTGTGAGAGTGCTTCTTCTTTAGTGAGAGAGCATTTGGGATAAGTGAGGAAATAGTTTTTTGCATTTAACCTAAAAGCACGTGGCATTTTGGCAATCGGTGTACAAGCTAATTCTCTGCCAATCGGTGTATTGGGGTACAATATATAGGTGTACACCAAATGGCATTATTGTAATTTGGGAAAGAAATTCAAAAGATACACGCTCCAAAGCGGCCATCCGTCTAATATT
Gene Information
|
NCBI Accession
|
YP_009508357.1
|
|
Location
|
128-484 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGTGGGATCCATTAGTAAACGAGTTTCCCGAAACCGTTCACGGTTTTCGATGTATGTTGGCAGTGAAATATCTCCAACTAGTTGCGGATACGTATTCCCCAGATACGGTGGGATACGATTTAATACGTGATTTAATTTGTATTCTACGTTCCAGGAATTATGTCGAAGCGCAAAGCAGATATAATCATTTCCACCCCAGGCTCGAAGGTTCGACGGAGGCTGAACTTCGACAGTCCAGGATCGAGCCGTGCTTATGTCCCTACTGTCCGCGTCACCAAATCAAGTCTATGGGCCAACAGACCCATGAACAGAAAGCCCAGGATGTACAGGATGTACAGAAGTCCAGATGTCCCTAG |
|
Protein Sequence
|
MWDPLVNEFPETVHGFRCMLAVKYLQLVADTYSPDTVGYDLIRDLICILRSRNYVEAQSRYNHFHPRLEGSTEAELRQSRIEPCLCPYCPRHQIKSMGQQTHEQKAQDVQDVQKSRCP |
|
NCBI Accession
|
YP_009508358.1
|
|
Location
|
288-1058 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGCAAAGCAGATATAATCATTTCCACCCCAGGCTCGAAGGTTCGACGGAGGCTGAACTTCGACAGTCCAGGATCGAGCCGTGCTTATGTCCCTACTGTCCGCGTCACCAAATCAAGTCTATGGGCCAACAGACCCATGAACAGAAAGCCCAGGATGTACAGGATGTACAGAAGTCCAGATGTCCCTAGAGGATGTGAAGGCCCATGTAAGGTCCAGTCGTTTGAGTCCAGACATGATATTCAGCATATAGGTAAAGTTATGTGTGTCAGTGATGTTACGCGTGGAACTGGGCTGACCCATCGAGTGGGTAAAAGGTTTTGTGTTAAATCTGTTTATGTATTGGGCAAGATCTGGATGGACGAGAATATTAAGACCAAAAATCACACGAATAGTGTGATGTTTTTTTTAGTTAGGGATCGTAGACCCGTTGACAAGCCTCAAGATTTTGGTGAGGTTTTTAACATGTTTGATAATGAGCCCAGCACCGCGACTGTGAAGAATGTTCATCGTGATAGATACCAGGTATTAAGGAAGTGGCATGCAACTGTGACTGGTGGACAATATGCATCGAAGGAGCAGGCTCTCGTGAAGAAGTTTATTAGGGTTAATAATTATGTTGTGTACAACCAGCAAGAGGCTGGCAAGTATGAGAATCATTCTGAGAATGCGTTGATGTTGTATATGGCGTGTACGCACGCTTCTAATCCTGTGTATGCTACATTAAAGATACGGATCTACTTCTACGATTCAGTATCGAATTAA |
|
Protein Sequence
|
MSKRKADIIISTPGSKVRRRLNFDSPGSSRAYVPTVRVTKSSLWANRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDIQHIGKVMCVSDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWHATVTGGQYASKEQALVKKFIRVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_009508359.1
|
|
Location
|
1055-1459 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAACCCATCACTGCAGCTCAAGCAGTGAATGGCGTGTATATCTGGAAGATTCAAAATCCCCTCTATTTCAAGATCTTAGAGCACCACAACCGGCCATTTCTCATGAACCAAGACATCATCACCGTCCAGATACAGTTCAATCACAACCTGAGGAAAGCACTGGGGATTCACAAATGTTTCCTAGCCTTCCGAATCTGGACGACCTCACAGCCTCCGACTGGTCATTTCTTAAGGGTCTTTAAGACCCAAGTTATTAAGTATTTAGATAATTTAGGAGTTATCAGTATTAACAATGTCATTAGAGCAGTTGATCATGTATTATGGGATGTATTACATCATGTTGTATATGTAGAACAATCATCTTCAATAAAATTCAATCTTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAAQAVNGVYIWKIQNPLYFKILEHHNRPFLMNQDIITVQIQFNHNLRKALGIHKCFLAFRIWTTSQPPTGHFLRVFKTQVIKYLDNLGVISINNVIRAVDHVLWDVLHHVVYVEQSSSIKFNLY |
|
NCBI Accession
|
YP_009508360.1
|
|
Location
|
1200-1607 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCGACATTCATCACCCTCGAGAGCCCACTCTACTCAGGTACCAATCAAGGTCCAACACAGAGCTGCTAAGCGTAGAGCCATCCGGCGTAAGAGGGTTGATCTAAACTGTGGGTGCTCATACTACGTACACATCAACTGCCACAACCATGGATTCACGCACCGGGGAACCCATCACTGCAGCTCAAGCAGTGAATGGCGTGTATATCTGGAAGATTCAAAATCCCCTCTATTTCAAGATCTTAGAGCACCACAACCGGCCATTTCTCATGAACCAAGACATCATCACCGTCCAGATACAGTTCAATCACAACCTGAGGAAAGCACTGGGGATTCACAAATGTTTCCTAGCCTTCCGAATCTGGACGACCTCACAGCCTCCGACTGGTCATTTCTTAAGGGTCTTTAA |
|
Protein Sequence
|
MRHSSPSRAHSTQVPIKVQHRAAKRRAIRRKRVDLNCGCSYYVHINCHNHGFTHRGTHHCSSSSEWRVYLEDSKSPLFQDLRAPQPAISHEPRHHHRPDTVQSQPEESTGDSQMFPSLPNLDDLTASDWSFLKGL |
|
NCBI Accession
|
YP_009508361.1
|
|
Location
|
1537-2589 |
|
Protein Name
|
replication initiation protein |
|
Coding Region
|
ATGCCACGTGCTTTTAGGTTAAATGCAAAAAACTATTTCCTCACTTATCCCAAATGCTCTCTCACTAAAGAAGAAGCACTCTCACAATTAGAAAACCTACAAACCCCAGTAAACAAAAAATACATAAAGATCTGCAGAGAGCTCCACGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAAGGGAAGTACCAGTGCACGAATAACAGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCGGACGTCAAGTCCTATCTGGAGAAGGACGGAGATACCCTCGAATGGGGAGAGTTTCAGATCGACGGACGATCTGCTAGAGGAGGTCAACAGACGGCCAACGACGCTTACGCCGCAGCGCTTAACACAGGCAGTAAGTCAGAGGCTCTCAGAGTCATTAAGGAGTTAGCTCCAAAGGATTATGTATTACAATTTCATAATTTAAATGCCAATTTAGATAGGATTTTCACACCTCCTCTGGAGGTTTATGTTTCTCCTTTTACTTCTTCTTCCTTCGATCAAGTTCCACAGCCCATAGAGGAATGGGCGTCTGAAAATGTGATGGGTGCCGCTGCGCGGCCTTTGAGACCCAAAAGTATTGTCATAGAGGGTGATAGTCGTACGGGGAAGACCATGTGGGCTAGGTCTTTGGGTCCACATAATTACCTGTGTGGTCATCTAGACCTTAGTCCTAAGGTTTACAGCAACGAGGCCTGGTACAACGTGATTGATGACGTAGATCCCCACTACCTAAAGCACTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACGAAATACGGAAAGCCAGTTCAAATTAAAGGCGGCATTCCCACTATCTTCCTCTGCAATCCAGGACCCAACTCAAGCTATAAAGAGTTCTTGGACGAAGAGAAGAATTCTGCACTGAAAAATTGGGCTTTAAAGAATGCGACATTCATCACCCTCGAGAGCCCACTCTACTCAGGTACCAATCAAGGTCCAACACAGAGCTGCTAA |
|
Protein Sequence
|
MPRAFRLNAKNYFLTYPKCSLTKEEALSQLENLQTPVNKKYIKICRELHENGEPHLHVLIQFEGKYQCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYLEKDGDTLEWGEFQIDGRSARGGQQTANDAYAAALNTGSKSEALRVIKELAPKDYVLQFHNLNANLDRIFTPPLEVYVSPFTSSSFDQVPQPIEEWASENVMGAAARPLRPKSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNEAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNSALKNWALKNATFITLESPLYSGTNQGPTQSC |
|
NCBI Accession
|
YP_009508362.1
|
|
Location
|
2136-2438 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAAGGGAAGTACCAGTGCACGAATAACAGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCGGACGTCAAGTCCTATCTGGAGAAGGACGGAGATACCCTCGAATGGGGAGAGTTTCAGATCGACGGACGATCTGCTAGAGGAGGTCAACAGACGGCCAACGACGCTTACGCCGCAGCGCTTAACACAGGCAGTAAGTCAGAGGCTCTCAGAGTCATTAAGGAGTTAG |
|
Protein Sequence
|
MGNLIFTCSSSSKGSTSARITDSSTWYPQPGQHISIRTFRELNQARTSSPIWRRTEIPSNGESFRSTDDLLEEVNRRPTTLTPQRLTQAVSQRLSESLRS |