Ageratum leaf curl Sichuan virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_013088045.1 |
| Isolate |
China: Sichuan |
| Release date |
2021/6/1 |
| Submitter |
Li,P., Qing,L. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
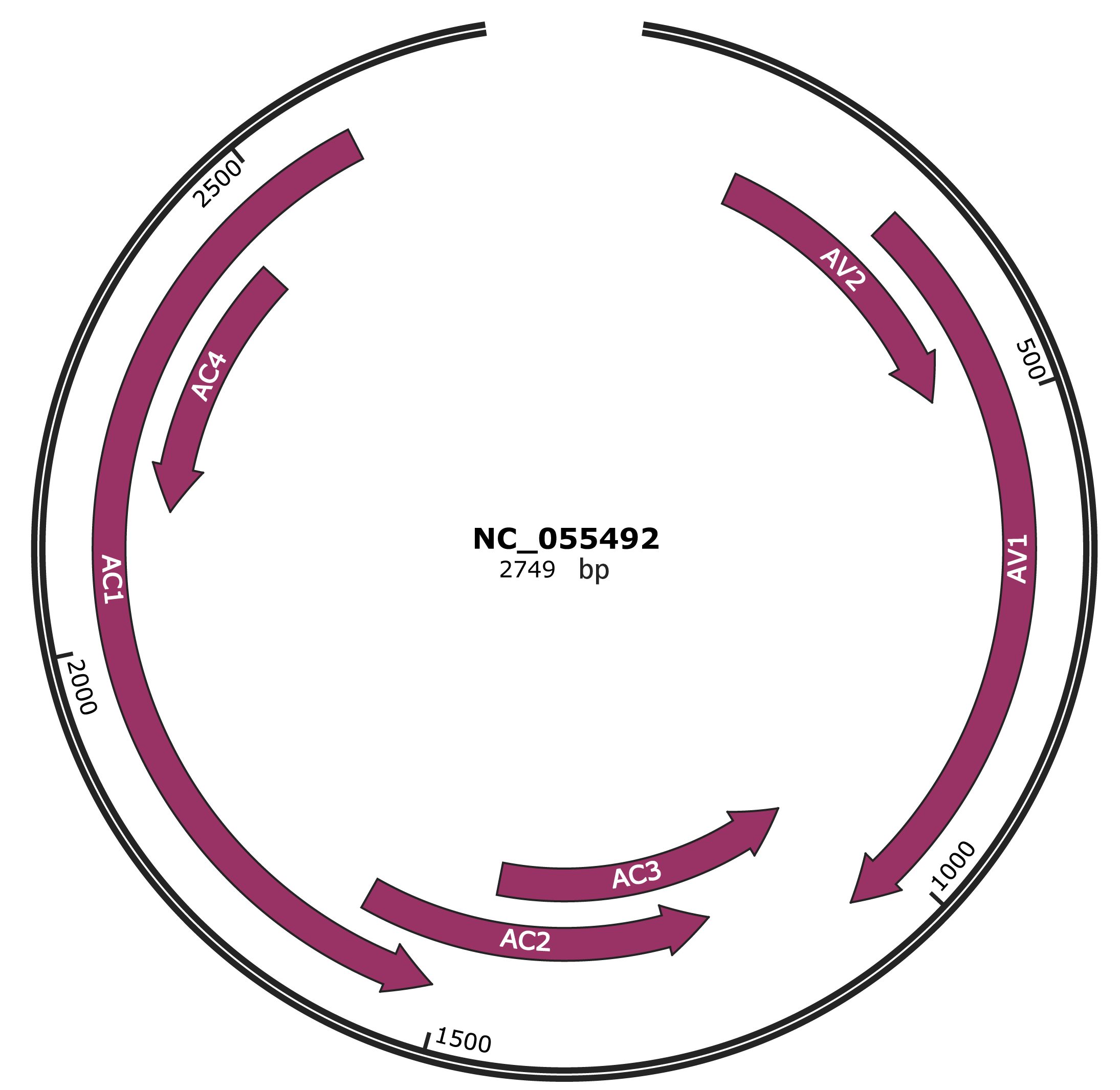
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTAAGGTGGTCCCCCCCACTAACTCCTGTCCAATCATGACCGCGCCTCAAAGCTTAATTATTAAGTGGTCCTGTATATAACTTCGACCCGAAGGAGTCATTTTAAACATGTGGGATCCATTGTTAAACGAATTCCCAGAAACCGTACATGGTTTCAGGTGTATGCTAGCCATTAAGTATTTGCAGCTAGTAGAAAATACATACTCTCCGGATACGTTAGGGTACGATTTAATTCGTGATTTAATTCTTGTTGTCCGTGCTAGAGATTATGTCGAAGCGTCCCGCAGATATAGTCATTTCCACTCCCGCATCCAAGGTGCGTCGCCGGTTGAACTTCGACAACCCTTATTCCAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAAAGGAAGTCATGGGTCAATCGGCCCATGTATCGAAAGCCCAGGATGTACAGGATGTTCAAAAGCCCTGATGTCCCTCGAGGCTGTGAGGGTCCTTGTAAGGTCCAATCTTTTGATGCGAAAAATGATATCGGTCACATGGGTAAGGTTATTTGTTTGTCCGATGTTACTAGGGGTATGGGGCTGACCCATCGAGTTGGTAAACGTTTCTGTGTGAAGTCATTATATTTTGTCGGCAAGATTTGGATGGATGAAAATATCAAGGTCAAGAACCACACTAACACCGTTCTGTTTTGGATAGTTAGGGATAGACGCCCTTCTGGAACTCCTAATGATTTTCAGCAGGTGTTTAATGTTTACGATAACGAACCTTCAACGGCCACCGTCAAGAACGACCAGCGTGATCGTTTCCAGGTATTGAGGAGGTTTCAGGCAACTGTAACTGGGGGTCAATATGCAGCTAAGGAGCAGGCGATAATTAGAAAGTTCTATCGTGTTAATAACCATGTTGTTTATAATCATCAGGAGGCTGGGAAATACGAGAATCACACGGAGAATGCACTTTTGTTGTATATGGCATGTACCCATGCCTCTAATCCCGTGTATGCTACTTTGAAAGTCAGGAGTTATTTCTATGACTCAGTGACGAATTAATAAATATTAAATTTTATTATGTTTGTGTTTTCTACATATGTTGTTCGTGTTAACACATCCCATAATACATGATTTGCTGCTCTTATTACATTGTTAATACTAATTACACCCAATCTATCAAGATATTTCATAATTTGAGTCCTAAATACCCTTAAGAAAAGACCAGTCTGAAGGTGTGAGGTCGTCCAGATTCGGAAGTTCAGAAAACATTGGTGAAGCCCCAGTGCTTTCCTCAGGTTGTGATTGAACTGTACCTTTACCGTTACTATATCGTTCTCCGTCAGAAAGGGCTGGTTCTGTAATTCTGTTATCTTGAAATATAGGGGATTTGGTATGTTCCAGATAAAAACGCCATTCTCTGCCTGAGTTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGATTGGCGCAGTTAATTGACGAGAAGTATGAACAACCGCAGGGAAGATCAACCCTCCTCCTCCTGATGGACTTCTTCTTCGCCTGCTTGTGTTGGACTTTGATGGGAACCGGAGTAGAGTGGCTCTTCGAGGGTGACGAAGTACGCATTTTTTAAAGCCCAATTTTTAAGTGAGGAGTTCTTTTCCTCATCCAGGTACTCTTTATAGCTGGAATTTGGACCTGGATTGCATAGGAAGATTGTGGGTATCCCGCCTTTAATTTGAACTGGTTTACCGTACTTGGTATTTGATTGCCAGTCTCTTTGGGCCCCCATGAATTCCTTAAAATGCTTGAGGAAGTGCGGGTCTACGTCATCAATGACATTATACCAGGCTTCGTTGCTGTAGACTTTTGGGCTTAGATCCAGATGTCCACACAAATAATTGTGTGGGCCTATTGACCGAGCCCACATCGTTTTCCCGGTACGACTGTCTCCTTCAATCACTATACTCATTGGTCTTAGGGGCCGCGCAGCGGCGTCGACGACGTTCTCCGACGCCCATTCTTCGAGTTCTTCTGGAACTCGATCGAAAGAAGATAAAGAAAAAGGAGAGACATAAACCTCTAAAGGAGGTGTAAAAATCCTATCTAAATTAGCATTTAAATTATGAAATTGTAATACATAATCCTTAGGGGCTAGTTCCCTAAGTACTCTAAGAGCCTCTGGCTTACTGCCTGTGTTAAGTGCTGCTGCGTAAGCGTCGTTGGCTGTTTGTTGTCCCCCCCTTGCAGATCGTCCGTCGATCTGAAACTCTCCCCATTCGAGGGTGTCTCCGTCCTTGTTGATGTAGGACTTGACGTCCGAGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTACCGACCTTGTTGGGGAGACCAGGTCGAAGAATCTGTTATTCTGGCACTTGTATTTCCCCTCGAACTGCACGAGCACATGGAGATGAGGCCTCCCATTTTTGTGGAGCTCTCTGCAGATCTTTATGTATTTTTGGTTAACTGGAGTGTTTAGGTTTTGTATTTGGGAAAGTGCCTCTTCTTTAGTAAGAGAACAATCGGGGTAAGTAAGGAAATAATTTTTGCAATAAATGTTAAAGCGTTTAGAGGGAGCCATAATGGTCAATGATCACCGATTGACTCGCTCTTGCAACTCTCTCTGGTATTTCGGTGATCAATATATAGTGATCACCAAATGGCATTTTGGTAAAATGAGTAAGAAATTCAAAATCCTTACGCTCCAAAAAGCGGCCATCCGTCTAATATT
Gene Information
|
NCBI Accession
|
YP_010086841.1
|
|
Location
|
129-479 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCATTGTTAAACGAATTCCCAGAAACCGTACATGGTTTCAGGTGTATGCTAGCCATTAAGTATTTGCAGCTAGTAGAAAATACATACTCTCCGGATACGTTAGGGTACGATTTAATTCGTGATTTAATTCTTGTTGTCCGTGCTAGAGATTATGTCGAAGCGTCCCGCAGATATAGTCATTTCCACTCCCGCATCCAAGGTGCGTCGCCGGTTGAACTTCGACAACCCTTATTCCAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAAAGGAAGTCATGGGTCAATCGGCCCATGTATCGAAAGCCCAGGATGTACAGGATGTTCAAAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPETVHGFRCMLAIKYLQLVENTYSPDTLGYDLIRDLILVVRARDYVEASRRYSHFHSRIQGASPVELRQPLFQPCCCPHCPRHKQKEVMGQSAHVSKAQDVQDVQKP |
|
NCBI Accession
|
YP_010086842.1
|
|
Location
|
289-1062 |
|
Gene Name
|
AV1 |
|
Protein Name
|
AV1 protein |
|
Coding Region
|
ATGTCGAAGCGTCCCGCAGATATAGTCATTTCCACTCCCGCATCCAAGGTGCGTCGCCGGTTGAACTTCGACAACCCTTATTCCAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAAAGGAAGTCATGGGTCAATCGGCCCATGTATCGAAAGCCCAGGATGTACAGGATGTTCAAAAGCCCTGATGTCCCTCGAGGCTGTGAGGGTCCTTGTAAGGTCCAATCTTTTGATGCGAAAAATGATATCGGTCACATGGGTAAGGTTATTTGTTTGTCCGATGTTACTAGGGGTATGGGGCTGACCCATCGAGTTGGTAAACGTTTCTGTGTGAAGTCATTATATTTTGTCGGCAAGATTTGGATGGATGAAAATATCAAGGTCAAGAACCACACTAACACCGTTCTGTTTTGGATAGTTAGGGATAGACGCCCTTCTGGAACTCCTAATGATTTTCAGCAGGTGTTTAATGTTTACGATAACGAACCTTCAACGGCCACCGTCAAGAACGACCAGCGTGATCGTTTCCAGGTATTGAGGAGGTTTCAGGCAACTGTAACTGGGGGTCAATATGCAGCTAAGGAGCAGGCGATAATTAGAAAGTTCTATCGTGTTAATAACCATGTTGTTTATAATCATCAGGAGGCTGGGAAATACGAGAATCACACGGAGAATGCACTTTTGTTGTATATGGCATGTACCCATGCCTCTAATCCCGTGTATGCTACTTTGAAAGTCAGGAGTTATTTCTATGACTCAGTGACGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDNPYSSRAAAPTVLVTNKRKSWVNRPMYRKPRMYRMFKSPDVPRGCEGPCKVQSFDAKNDIGHMGKVICLSDVTRGMGLTHRVGKRFCVKSLYFVGKIWMDENIKVKNHTNTVLFWIVRDRRPSGTPNDFQQVFNVYDNEPSTATVKNDQRDRFQVLRRFQATVTGGQYAAKEQAIIRKFYRVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKVRSYFYDSVTN |
|
NCBI Accession
|
YP_010086843.1
|
|
Location
|
1059-1463 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCAACTCAGGCAGAGAATGGCGTTTTTATCTGGAACATACCAAATCCCCTATATTTCAAGATAACAGAATTACAGAACCAGCCCTTTCTGACGGAGAACGATATAGTAACGGTAAAGGTACAGTTCAATCACAACCTGAGGAAAGCACTGGGGCTTCACCAATGTTTTCTGAACTTCCGAATCTGGACGACCTCACACCTTCAGACTGGTCTTTTCTTAAGGGTATTTAGGACTCAAATTATGAAATATCTTGATAGATTGGGTGTAATTAGTATTAACAATGTAATAAGAGCAGCAAATCATGTATTATGGGATGTGTTAACACGAACAACATATGTAGAAAACACAAACATAATAAAATTTAATATTTATTAA |
|
Protein Sequence
|
MDSRTGEPITATQAENGVFIWNIPNPLYFKITELQNQPFLTENDIVTVKVQFNHNLRKALGLHQCFLNFRIWTTSHLQTGLFLRVFRTQIMKYLDRLGVISINNVIRAANHVLWDVLTRTTYVENTNIIKFNIY |
|
NCBI Accession
|
YP_010086844.1
|
|
Location
|
1204-1611 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCGTACTTCGTCACCCTCGAAGAGCCACTCTACTCCGGTTCCCATCAAAGTCCAACACAAGCAGGCGAAGAAGAAGTCCATCAGGAGGAGGAGGGTTGATCTTCCCTGCGGTTGTTCATACTTCTCGTCAATTAACTGCGCCAATCATGGATTCACGCACAGGGGAACCCATCACTGCAACTCAGGCAGAGAATGGCGTTTTTATCTGGAACATACCAAATCCCCTATATTTCAAGATAACAGAATTACAGAACCAGCCCTTTCTGACGGAGAACGATATAGTAACGGTAAAGGTACAGTTCAATCACAACCTGAGGAAAGCACTGGGGCTTCACCAATGTTTTCTGAACTTCCGAATCTGGACGACCTCACACCTTCAGACTGGTCTTTTCTTAAGGGTATTTAG |
|
Protein Sequence
|
MRTSSPSKSHSTPVPIKVQHKQAKKKSIRRRRVDLPCGCSYFSSINCANHGFTHRGTHHCNSGREWRFYLEHTKSPIFQDNRITEPALSDGERYSNGKGTVQSQPEESTGASPMFSELPNLDDLTPSDWSFLKGI |
|
NCBI Accession
|
YP_010086845.1
|
|
Location
|
1511-2599 |
|
Gene Name
|
AC1 |
|
Protein Name
|
AC1 protein |
|
Coding Region
|
ATGGCTCCCTCTAAACGCTTTAACATTTATTGCAAAAATTATTTCCTTACTTACCCCGATTGTTCTCTTACTAAAGAAGAGGCACTTTCCCAAATACAAAACCTAAACACTCCAGTTAACCAAAAATACATAAAGATCTGCAGAGAGCTCCACAAAAATGGGAGGCCTCATCTCCATGTGCTCGTGCAGTTCGAGGGGAAATACAAGTGCCAGAATAACAGATTCTTCGACCTGGTCTCCCCAACAAGGTCGGTACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCGGACGTCAAGTCCTACATCAACAAGGACGGAGACACCCTCGAATGGGGAGAGTTTCAGATCGACGGACGATCTGCAAGGGGGGGACAACAAACAGCCAACGACGCTTACGCAGCAGCACTTAACACAGGCAGTAAGCCAGAGGCTCTTAGAGTACTTAGGGAACTAGCCCCTAAGGATTATGTATTACAATTTCATAATTTAAATGCTAATTTAGATAGGATTTTTACACCTCCTTTAGAGGTTTATGTCTCTCCTTTTTCTTTATCTTCTTTCGATCGAGTTCCAGAAGAACTCGAAGAATGGGCGTCGGAGAACGTCGTCGACGCCGCTGCGCGGCCCCTAAGACCAATGAGTATAGTGATTGAAGGAGACAGTCGTACCGGGAAAACGATGTGGGCTCGGTCAATAGGCCCACACAATTATTTGTGTGGACATCTGGATCTAAGCCCAAAAGTCTACAGCAACGAAGCCTGGTATAATGTCATTGATGACGTAGACCCGCACTTCCTCAAGCATTTTAAGGAATTCATGGGGGCCCAAAGAGACTGGCAATCAAATACCAAGTACGGTAAACCAGTTCAAATTAAAGGCGGGATACCCACAATCTTCCTATGCAATCCAGGTCCAAATTCCAGCTATAAAGAGTACCTGGATGAGGAAAAGAACTCCTCACTTAAAAATTGGGCTTTAAAAAATGCGTACTTCGTCACCCTCGAAGAGCCACTCTACTCCGGTTCCCATCAAAGTCCAACACAAGCAGGCGAAGAAGAAGTCCATCAGGAGGAGGAGGGTTGA |
|
Protein Sequence
|
MAPSKRFNIYCKNYFLTYPDCSLTKEEALSQIQNLNTPVNQKYIKICRELHKNGRPHLHVLVQFEGKYKCQNNRFFDLVSPTRSVHFHPNIQGAKSSSDVKSYINKDGDTLEWGEFQIDGRSARGGQQTANDAYAAALNTGSKPEALRVLRELAPKDYVLQFHNLNANLDRIFTPPLEVYVSPFSLSSFDRVPEELEEWASENVVDAAARPLRPMSIVIEGDSRTGKTMWARSIGPHNYLCGHLDLSPKVYSNEAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEYLDEEKNSSLKNWALKNAYFVTLEEPLYSGSHQSPTQAGEEEVHQEEEG |
|
NCBI Accession
|
YP_010086846.1
|
|
Location
|
2140-2442 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGAGGCCTCATCTCCATGTGCTCGTGCAGTTCGAGGGGAAATACAAGTGCCAGAATAACAGATTCTTCGACCTGGTCTCCCCAACAAGGTCGGTACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCGGACGTCAAGTCCTACATCAACAAGGACGGAGACACCCTCGAATGGGGAGAGTTTCAGATCGACGGACGATCTGCAAGGGGGGGACAACAAACAGCCAACGACGCTTACGCAGCAGCACTTAACACAGGCAGTAAGCCAGAGGCTCTTAGAGTACTTAGGGAACTAG |
|
Protein Sequence
|
MGGLISMCSCSSRGNTSARITDSSTWSPQQGRYISIRTFRELNPARTSSPTSTRTETPSNGESFRSTDDLQGGDNKQPTTLTQQHLTQAVSQRLLEYLGN |