Eupatorium yellow vein mosaic virus
Basic Information
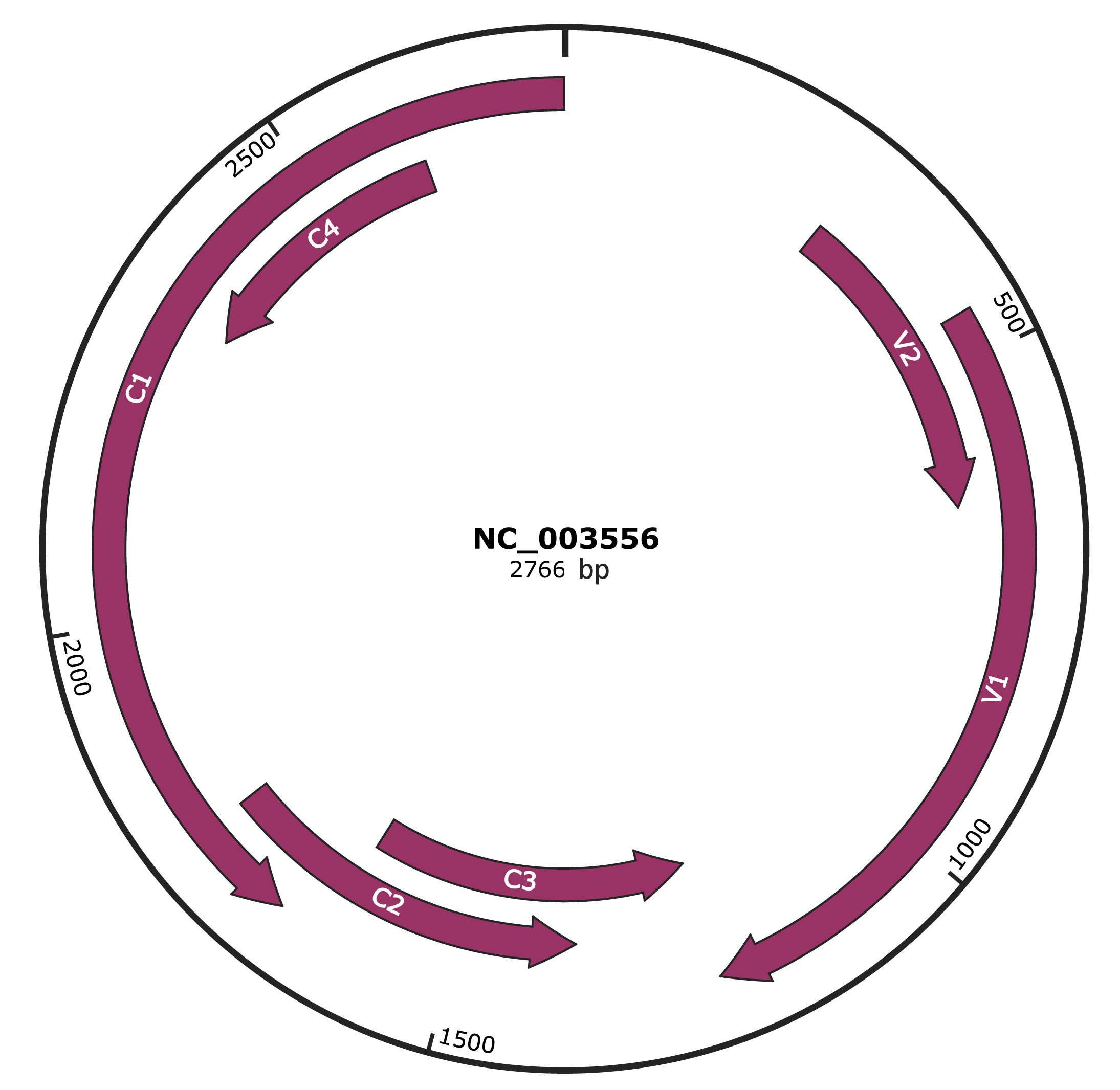
Genomic Organization
JBrowse
Genome
GTTGACTGGTCAATCGGTGTCTCTCAAAGTTCTATGCAATCGGTGTCTCTGGAGTCTTATTTATAGTAGAGACTCCAAATGGCATAAATGGTAATTATTGGGGGTAGGAGCGTGTCTTTTTGAATTTCAAATCGCCAAAGCGGCCATCCGTATAATATTACCGGATGGCCGCCGATTTTTTTTGTGGCCCCTCCCTGTCGGCTGATCCTGACCGTTCCTCAACGCTTAATTAAATACTGGTCCCCGTACGTCTTTAAGTATTTAATACTTGCGCCCTAAGCTTTATACGTGTATAATGTGGGATCCATTAGTTAACGAGTTCCCTGAAACCGTACACGGTTTTAGGTGTATGCTTGCAATTAAATACCTACAGCTTGTAGAATCTACGTATTCTCCAGATACGGTAGGTCGCGATCTTATTCGTGACCTAATACTTGTTATTCGTGCTAAGAATTATGTCGAAGCGTCCTGCAGATATAGTGATTTCCACACCCGCCTCCAAGGTACGTCGCCGTCTGAACTTCGACAGCCCGTATGTCAGCCGTGCGAATGCCCCCACTGTCCTCGTCACAAACAGAAGGAGATCATGGGCTCAACGGCCCATGTATCGGAAGCCCAGGATGTTCCGAATGTACAGAAGCCCTGATATCCCTAAGGGCTGTGAAGGCCCGTGTAAGGTCCAGTCGTTTGAGAAGAAAAATGATGTTGGTCATTCTGGTACTTTGTTATGTGTTTCTGATGTTACTCGTGGTAACGGTCTTACTCATCGTTCTGGCAAGAGATTTTGTATAAAATCTTGTTATATTATTGGTAAAATCTGGATGGATGAAAACATCAAGACTAAGAATCACACTAACACTGTCATGTTCTGGTTAGTTAGGGATAGACGTCCCCTTACAACCCCGTATGGATTTCAAGAGGCATTCAACATGTTTGATAACGAACCCAGTACAGCTACTATCAAGCAGGACCTAAGAGATCGTCTGCAGGTGTTACACAAGTTCCAGGCTACTGTCACTGGTGGACAGTATGCGTCCAAGGAACAGGCTGTGATCAAGAAGTTCTGGAAGATCAATCATCATGTTACTTACAATCATCAGGAGCAGGCTAAATATGAGAATCATACTGAGAACGCATTAATATTGTATATGGCTAGTACTCATGCCAGTAATCCCGTGTATGCAACTTTGAAAATCAGGTTCTATTTTTATGATTCTGTTCAGAATTAATAAATTTTATATTTTATATCATGAAATGTCCGTACATACAATGTTCCTTGTAATCTATTATACAATACATGATCAACTGCTCTAATTACATTATTAATTGAAATCACACCCAGACTATCTAAGTAGTTCATCACTTGTGTCCTAAAGACCCTCAAGAAATGCCATGTCTGAGGATGTAAGCGGCTCCAGATCTTGAAAATGAGGAAACACTTGTGCAAACCCAGCTGGGATCTGAGGTTGTGGTTGAACTGTATCTGTATTGTTATTACGTCTTGGTCCCTGTTGAATGATCGTTGATTGTGCCTCGTAATCTTGAAATAGAGGGGATTTGGAACCCTCCAGATATACTCTCCATTCTGTGCCTGAGCTGCAGTGATGAGTATCCCTGTGCGTGAATCCATAGTTTGCACAGTCAAGTCCCACGAAGATAGAACACCCGCAGTTTAGATCAATCCTCCTCCTGCGGTTCTTCTTCTTCGATTTGGCTATCCTGTGCTGGACTTTGATGGGAACCTGAATAGAGTGGGCTGTAGAGGGTGACGAAGGTTGCATTTTTAACTGCCCAGGCTTTTAATGCGGAATTCTTTTCTTCGTCCAGAAATTCCGTATATGAAGACGTTGGACCTGGATTGCAGAGGAAGATTGTTGGGATTCCACCTTTAATTTGAATTGGCTTCCCGTACTTCGTGTTGCTTTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTAAAATGCTTTAGATAGTGGGGGTCTACATCATCAACGACGTTGTACCATGCGTCGTTGCTGTAGATCTTCGGACTCAGATCCAGATGACCGCATAGGTAGTTATGTGGACCTAACGACCTAGCCCACATCGTTTTTCCTGTCCTACTGTCACCCTCTATGACAATACTAATCGGTCTCCATGGCCGCGCAGAAGACTTCACGTTTTCTGCAGCCCATTCCTCAAGTTCTTCAGGAACTTGATCAAATGAAGAACTAGAAAAAGGACAAACAAAAACCTCCAATGGAGGAGCAAAAATCCTATCTAAATTTGAATTTAAATTATGAAATTGTAAAACAAAATCTTTGGGAGCTTTCTCCCTTAATATATTGAGTGCCGATGACTTTGATCCTGAGTTGATTGCCTCGGCATATGCGTCGTTGGCAGATTGGCAACCTCCCCTAGCTGATCTTCCATCGACTTGGAAAACTCCAAAATCAAGGATGTCTCCGTCTTTCTCCATGTAGGACTTGACATCTGACGAGCTTTTAGCCGCCTGAATGTTCGGATGGAAATGTGCTGACCTACTTGGGGATACGAGGTCGAAGAATCGTTGATTTTTGCATTGGTATTTTCCTTCGAATTGGATGAGGATGTGGAGATGAGGGCTCCCATCTTCATGTAATTCACGGCAGATTCTTATGAATTTTTTTGATATCGGTGTTTGGAGTTGCTTGATTTGTGAGAGTGCTTCTCCTTTAGTAAGAGAGCAGTGTGGGTATGTGAGGAAATAATTCTTTGCATTTATTTTAAAACGATTTGGGGCAGGCAT
Gene Information
|
NCBI Accession
|
NP_619553.1
|
|
Location
|
296-646 |
|
Gene Name
|
V2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCATTAGTTAACGAGTTCCCTGAAACCGTACACGGTTTTAGGTGTATGCTTGCAATTAAATACCTACAGCTTGTAGAATCTACGTATTCTCCAGATACGGTAGGTCGCGATCTTATTCGTGACCTAATACTTGTTATTCGTGCTAAGAATTATGTCGAAGCGTCCTGCAGATATAGTGATTTCCACACCCGCCTCCAAGGTACGTCGCCGTCTGAACTTCGACAGCCCGTATGTCAGCCGTGCGAATGCCCCCACTGTCCTCGTCACAAACAGAAGGAGATCATGGGCTCAACGGCCCATGTATCGGAAGCCCAGGATGTTCCGAATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLVNEFPETVHGFRCMLAIKYLQLVESTYSPDTVGRDLIRDLILVIRAKNYVEASCRYSDFHTRLQGTSPSELRQPVCQPCECPHCPRHKQKEIMGSTAHVSEAQDVPNVQKP |
|
NCBI Accession
|
NP_619554.1
|
|
Location
|
456-1229 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGTCCTGCAGATATAGTGATTTCCACACCCGCCTCCAAGGTACGTCGCCGTCTGAACTTCGACAGCCCGTATGTCAGCCGTGCGAATGCCCCCACTGTCCTCGTCACAAACAGAAGGAGATCATGGGCTCAACGGCCCATGTATCGGAAGCCCAGGATGTTCCGAATGTACAGAAGCCCTGATATCCCTAAGGGCTGTGAAGGCCCGTGTAAGGTCCAGTCGTTTGAGAAGAAAAATGATGTTGGTCATTCTGGTACTTTGTTATGTGTTTCTGATGTTACTCGTGGTAACGGTCTTACTCATCGTTCTGGCAAGAGATTTTGTATAAAATCTTGTTATATTATTGGTAAAATCTGGATGGATGAAAACATCAAGACTAAGAATCACACTAACACTGTCATGTTCTGGTTAGTTAGGGATAGACGTCCCCTTACAACCCCGTATGGATTTCAAGAGGCATTCAACATGTTTGATAACGAACCCAGTACAGCTACTATCAAGCAGGACCTAAGAGATCGTCTGCAGGTGTTACACAAGTTCCAGGCTACTGTCACTGGTGGACAGTATGCGTCCAAGGAACAGGCTGTGATCAAGAAGTTCTGGAAGATCAATCATCATGTTACTTACAATCATCAGGAGCAGGCTAAATATGAGAATCATACTGAGAACGCATTAATATTGTATATGGCTAGTACTCATGCCAGTAATCCCGTGTATGCAACTTTGAAAATCAGGTTCTATTTTTATGATTCTGTTCAGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPYVSRANAPTVLVTNRRRSWAQRPMYRKPRMFRMYRSPDIPKGCEGPCKVQSFEKKNDVGHSGTLLCVSDVTRGNGLTHRSGKRFCIKSCYIIGKIWMDENIKTKNHTNTVMFWLVRDRRPLTTPYGFQEAFNMFDNEPSTATIKQDLRDRLQVLHKFQATVTGGQYASKEQAVIKKFWKINHHVTYNHQEQAKYENHTENALILYMASTHASNPVYATLKIRFYFYDSVQN |
|
NCBI Accession
|
NP_619555.1
|
|
Location
|
1226-1630 |
|
Gene Name
|
C3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGATACTCATCACTGCAGCTCAGGCACAGAATGGAGAGTATATCTGGAGGGTTCCAAATCCCCTCTATTTCAAGATTACGAGGCACAATCAACGATCATTCAACAGGGACCAAGACGTAATAACAATACAGATACAGTTCAACCACAACCTCAGATCCCAGCTGGGTTTGCACAAGTGTTTCCTCATTTTCAAGATCTGGAGCCGCTTACATCCTCAGACATGGCATTTCTTGAGGGTCTTTAGGACACAAGTGATGAACTACTTAGATAGTCTGGGTGTGATTTCAATTAATAATGTAATTAGAGCAGTTGATCATGTATTGTATAATAGATTACAAGGAACATTGTATGTACGGACATTTCATGATATAAAATATAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGILITAAQAQNGEYIWRVPNPLYFKITRHNQRSFNRDQDVITIQIQFNHNLRSQLGLHKCFLIFKIWSRLHPQTWHFLRVFRTQVMNYLDSLGVISINNVIRAVDHVLYNRLQGTLYVRTFHDIKYKIY |
|
NCBI Accession
|
NP_619556.1
|
|
Location
|
1371-1781 |
|
Gene Name
|
C2 |
|
Protein Name
|
transcriptional transactivator protein |
|
Coding Region
|
ATGCAACCTTCGTCACCCTCTACAGCCCACTCTATTCAGGTTCCCATCAAAGTCCAGCACAGGATAGCCAAATCGAAGAAGAAGAACCGCAGGAGGAGGATTGATCTAAACTGCGGGTGTTCTATCTTCGTGGGACTTGACTGTGCAAACTATGGATTCACGCACAGGGATACTCATCACTGCAGCTCAGGCACAGAATGGAGAGTATATCTGGAGGGTTCCAAATCCCCTCTATTTCAAGATTACGAGGCACAATCAACGATCATTCAACAGGGACCAAGACGTAATAACAATACAGATACAGTTCAACCACAACCTCAGATCCCAGCTGGGTTTGCACAAGTGTTTCCTCATTTTCAAGATCTGGAGCCGCTTACATCCTCAGACATGGCATTTCTTGAGGGTCTTTAG |
|
Protein Sequence
|
MQPSSPSTAHSIQVPIKVQHRIAKSKKKNRRRRIDLNCGCSIFVGLDCANYGFTHRDTHHCSSGTEWRVYLEGSKSPLFQDYEAQSTIIQQGPRRNNNTDTVQPQPQIPAGFAQVFPHFQDLEPLTSSDMAFLEGL |
|
NCBI Accession
|
NP_619557.1
|
|
Location
|
1678-2766 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCTGCCCCAAATCGTTTTAAAATAAATGCAAAGAATTATTTCCTCACATACCCACACTGCTCTCTTACTAAAGGAGAAGCACTCTCACAAATCAAGCAACTCCAAACACCGATATCAAAAAAATTCATAAGAATCTGCCGTGAATTACATGAAGATGGGAGCCCTCATCTCCACATCCTCATCCAATTCGAAGGAAAATACCAATGCAAAAATCAACGATTCTTCGACCTCGTATCCCCAAGTAGGTCAGCACATTTCCATCCGAACATTCAGGCGGCTAAAAGCTCGTCAGATGTCAAGTCCTACATGGAGAAAGACGGAGACATCCTTGATTTTGGAGTTTTCCAAGTCGATGGAAGATCAGCTAGGGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAACTCAGGATCAAAGTCATCGGCACTCAATATATTAAGGGAGAAAGCTCCCAAAGATTTTGTTTTACAATTTCATAATTTAAATTCAAATTTAGATAGGATTTTTGCTCCTCCATTGGAGGTTTTTGTTTGTCCTTTTTCTAGTTCTTCATTTGATCAAGTTCCTGAAGAACTTGAGGAATGGGCTGCAGAAAACGTGAAGTCTTCTGCGCGGCCATGGAGACCGATTAGTATTGTCATAGAGGGTGACAGTAGGACAGGAAAAACGATGTGGGCTAGGTCGTTAGGTCCACATAACTACCTATGCGGTCATCTGGATCTGAGTCCGAAGATCTACAGCAACGACGCATGGTACAACGTCGTTGATGATGTAGACCCCCACTATCTAAAGCATTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACGAAGTACGGGAAGCCAATTCAAATTAAAGGTGGAATCCCAACAATCTTCCTCTGCAATCCAGGTCCAACGTCTTCATATACGGAATTTCTGGACGAAGAAAAGAATTCCGCATTAAAAGCCTGGGCAGTTAAAAATGCAACCTTCGTCACCCTCTACAGCCCACTCTATTCAGGTTCCCATCAAAGTCCAGCACAGGATAGCCAAATCGAAGAAGAAGAACCGCAGGAGGAGGATTGA |
|
Protein Sequence
|
MPAPNRFKINAKNYFLTYPHCSLTKGEALSQIKQLQTPISKKFIRICRELHEDGSPHLHILIQFEGKYQCKNQRFFDLVSPSRSAHFHPNIQAAKSSSDVKSYMEKDGDILDFGVFQVDGRSARGGCQSANDAYAEAINSGSKSSALNILREKAPKDFVLQFHNLNSNLDRIFAPPLEVFVCPFSSSSFDQVPEELEEWAAENVKSSARPWRPISIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKIYSNDAWYNVVDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYTEFLDEEKNSALKAWAVKNATFVTLYSPLYSGSHQSPAQDSQIEEEEPQEED |
|
NCBI Accession
|
NP_619558.1
|
|
Location
|
2316-2615 |
|
Gene Name
|
C4 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGAAGATGGGAGCCCTCATCTCCACATCCTCATCCAATTCGAAGGAAAATACCAATGCAAAAATCAACGATTCTTCGACCTCGTATCCCCAAGTAGGTCAGCACATTTCCATCCGAACATTCAGGCGGCTAAAAGCTCGTCAGATGTCAAGTCCTACATGGAGAAAGACGGAGACATCCTTGATTTTGGAGTTTTCCAAGTCGATGGAAGATCAGCTAGGGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAACTCAGGATCAAAGTCATCGGCACTCAATATATTAA |
|
Protein Sequence
|
MKMGALISTSSSNSKENTNAKINDSSTSYPQVGQHISIRTFRRLKARQMSSPTWRKTETSLILEFSKSMEDQLGEVANLPTTHMPRQSTQDQSHRHSIY |