Erectites yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000873285.1 |
| Isolate |
Viet Nam: Hoabinh |
| Release date |
2015/2/13 |
| Submitter |
Ha,C., Coombs,S., Revill,P., Harding,R., Vu,M., Dale,J., Ha,C.V., Revill,P.A., Harding,R.M., Vu,M.T., Dale,J.L. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
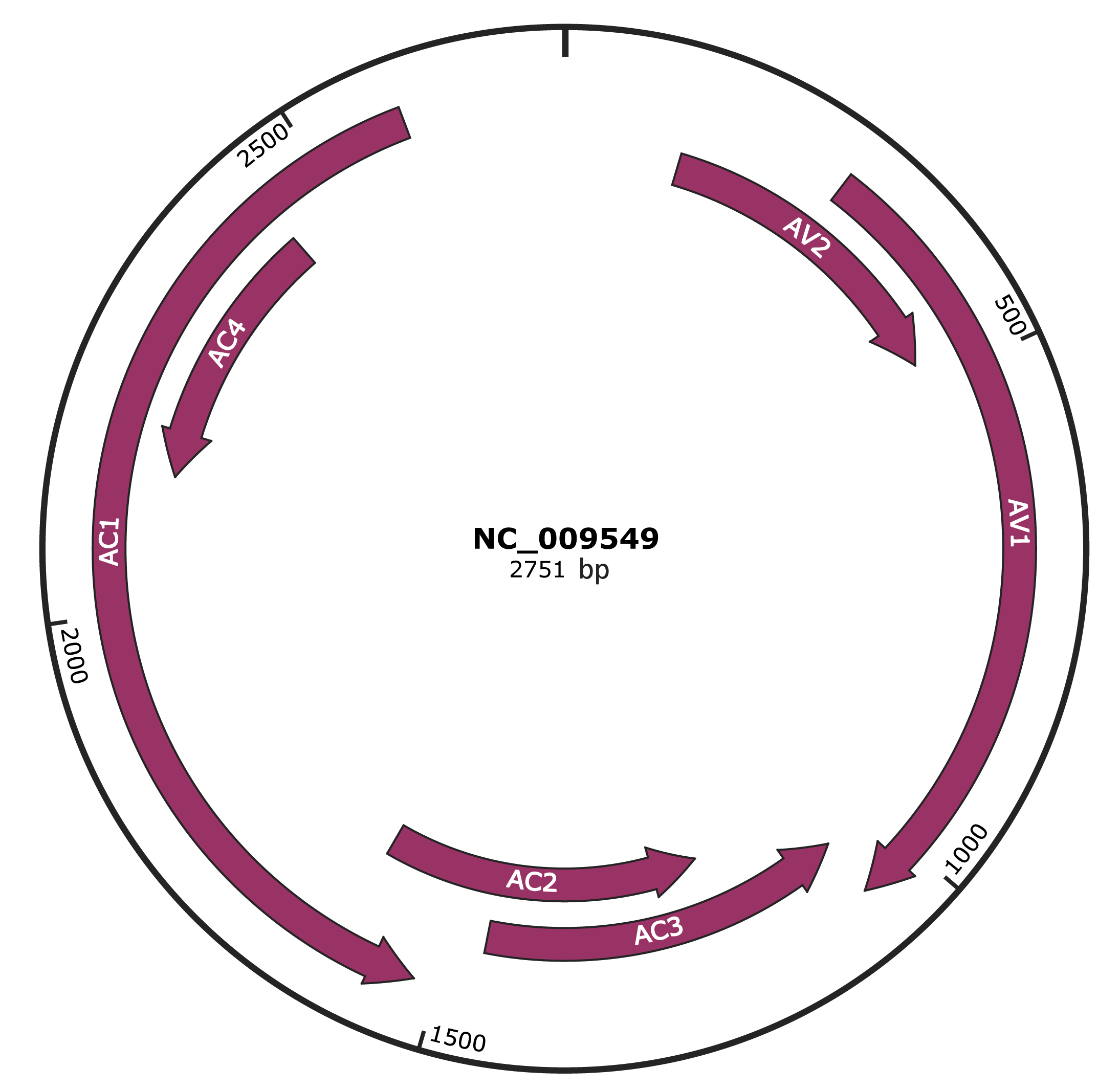
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTTAAGTGGTCCCCACACATGCTGCTGTCCAATCATATCCGCTCCTCAATGCTTAATTATTAAATGGTCCCCTATATATCTTGGTCCCCAAGTACCCACGTTAAACATGTGGGATCCTTTACTAAACGAGTTCCCTGAGACCGTACATGGTTTTAGGTGTATGTTAGCAATTAAATATTTGCAACTAGTAGAAAATACATACTCTCCCGACACATTAGGTTACGACCTAATACGTGATCTCATCTTGGTGATTCGTGCTAGGGATTATGTCGAAGCGTCCCGCAGATATAGTCATTTCCACTCCCGCCTCCAAGGTTCGTCGCCGATTGAACTTCGACAGCCCATATGTCAGCCGTGCTGCTGCCCCTACTGTCCTCGTCACAAACAAAAGGAGGTCATGGGCCAACCGGCCCATGAACAGAAAGCCCAGGATCTACAGGATGTACAAAAGCCCTGATGTTCCTCGGGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTATGAACAACGTCATGATGTAGCCCATGTAGGTAAGGTAATTTGTGTCTCTGATGTCACCCGCGGTAATGGGCTGACACATCGTGTTGGTAAGAGGTTCTGTATTAAGTCTGTGTATGTGTTGGGAAAAATTTGGATGGATGAGAATATTAAGACCAAGAATCATACTAATACTGTCATGTTCTTCTTGGTTCGTGATAGGAGACCATTTGGTACTCCACAGGATTTTGGTCAGGTGTTCAACATGTATGATAATGAGCCCAGTACGGCCACCGTGAAGAACGACAATAGAGATCGATTTCAAGTCATTCGGCGTTTCCAGGCGACCGTGACGGGTGGTCAATATGCAAGCAAGGAACAGGCTATAGTTAGGAAATTCATGAAGGTCAACAACCATGTGACGTATAACCATCAAGAGGCTGCGAAGTATGATAACCACACAGAGAATGCTTTGTTATTGTATATGGCATGTACTCATGCTAGTAATCCAGTGTATGCTACTTTGAAAATCAGGATCTATTTCTATGATTCTGTTCAGAATTAATAAATGTTGAATTTTATTATATTTGAGAGATGTGCATCAATTGTGCCTTCCAATACATTGTACAATACATGATTAATTGCTCTAATTACATTGTTGATGCTAATTACTCCTAACATGTCTAAATATTTCATACATTGATATTTAAATACTCTTAAGAAACGCGAGGTCTGAGGACGTAAACGAGTCCAGATTTGGCAGATTAGAAAACATTTGTGTATCCCCAACGCTTTCCTCAGGTTGTAGTTGAACTGGACCTGCACTGTGATTACGTCGTGTTTCATCATGAATGGCCTCTCGTGGTGTTGTGTTATTTTGAAATACAGGGGATTGTTGACCGTCCAGATATATACGCCATTCTCTCCTTGAGCTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGGTTATGACACTTGAGAGCGACGAAAAATGAACACCCACAAGGGAGATCAACTCGTCTTCTTCTAGTTGTCTTCTTGGCGATTCTGTGTCGCACTTTGATGGGTACCTGAGTAGAGTGGGCCCTCGAGGGTGACGAAGATTGCATTCTTTACAGCCCAATTTTTAAGTGCGCTGTTCTTTTCTTCATCCAAGAACTCTTTATAGCTGGAATGTGGTCCTGGATTGCAGAGGAAGATAGTGGGAATACCCCCTTTAATTTGAACTGGCTTCCCGTATTTGGTGTTGCTTTGCCAGTCTCTTTGGGCCCCCATGAACTCTTTAAAGTGCTTTAGATAGTGGGGATCGACGTCATCAATGACGTTATACCAGGCACTGTTGTTGTACACTTTTGGACTTAAATCTAAATGTCCGCATAAGTAGTTATGTGGTCCCAAAGACCTGGCCCATATCGTCTTCCCTGTCCTACTATCGCCCTCTACCACAATACTTATCGGTCTTAATGGCCGCGCAGCGGCATTGACAACGTTTGCGGAAACCCATTCATTAAGTTCCTCTGGAACTTGGTCGAATGAAGAAGAACAAAAAGGAGAAATGTAAATTTCTATTGGATGAGTAAAAATCCTATCTAAATTATTATTTAAATTATGGAACTGTAAAACAAAATCTTTGGGAGCTTTCTCCCTTAATATATTGAGGGCCGATGCTTTGGCCCCTGAATTGAGTGCCTCGGCATATGCGTCGTTGGCAGATTGGCAACCTCCTCTAGCCGATCGTCCATCGATCTGGAAAATTCCATGATCAAGCACGTCTCCGTCTTTTTCCATGTATGATTTAACATCTGATGAGCTTTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTGGTTGGGGATATGAGATCGAAGAATCTTTGATTTTTACACTGGAATTTCCCTTCGAATTGGATGAGGATATGCAGGTGAGGAGTTCCATCTTCGTGGAGTTCCCTGCAGATTCTGATGAATAATTTAGAAATTGGTGTTTCTAGGGCTTTAATTTGGGAAAGTGCCTCCTCTTTGGTAAGAGAACAGCGTGGATATGTGAGGAAATAGTTTTTGGCATTTATTCTGAATTTATTAGGAGGAGGCATTGACTGGTCAATTGGTGTCTCTCAAACTCTGCTATGCAATCGGTGTCTGGGGTCTTATTTATATGTGGACACCAAATGGCATAATTGTAATTCTGAAAAGGTATGATAAGGCCCATTGGGCTAGGCCCAATTGCAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_001285748.1
|
|
Location
|
127-477 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCTTTACTAAACGAGTTCCCTGAGACCGTACATGGTTTTAGGTGTATGTTAGCAATTAAATATTTGCAACTAGTAGAAAATACATACTCTCCCGACACATTAGGTTACGACCTAATACGTGATCTCATCTTGGTGATTCGTGCTAGGGATTATGTCGAAGCGTCCCGCAGATATAGTCATTTCCACTCCCGCCTCCAAGGTTCGTCGCCGATTGAACTTCGACAGCCCATATGTCAGCCGTGCTGCTGCCCCTACTGTCCTCGTCACAAACAAAAGGAGGTCATGGGCCAACCGGCCCATGAACAGAAAGCCCAGGATCTACAGGATGTACAAAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPETVHGFRCMLAIKYLQLVENTYSPDTLGYDLIRDLILVIRARDYVEASRRYSHFHSRLQGSSPIELRQPICQPCCCPYCPRHKQKEVMGQPAHEQKAQDLQDVQKP |
|
NCBI Accession
|
YP_001285749.1
|
|
Location
|
287-1060 |
|
Gene Name
|
AV1 |
|
Protein Name
|
CP protein |
|
Coding Region
|
ATGTCGAAGCGTCCCGCAGATATAGTCATTTCCACTCCCGCCTCCAAGGTTCGTCGCCGATTGAACTTCGACAGCCCATATGTCAGCCGTGCTGCTGCCCCTACTGTCCTCGTCACAAACAAAAGGAGGTCATGGGCCAACCGGCCCATGAACAGAAAGCCCAGGATCTACAGGATGTACAAAAGCCCTGATGTTCCTCGGGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTATGAACAACGTCATGATGTAGCCCATGTAGGTAAGGTAATTTGTGTCTCTGATGTCACCCGCGGTAATGGGCTGACACATCGTGTTGGTAAGAGGTTCTGTATTAAGTCTGTGTATGTGTTGGGAAAAATTTGGATGGATGAGAATATTAAGACCAAGAATCATACTAATACTGTCATGTTCTTCTTGGTTCGTGATAGGAGACCATTTGGTACTCCACAGGATTTTGGTCAGGTGTTCAACATGTATGATAATGAGCCCAGTACGGCCACCGTGAAGAACGACAATAGAGATCGATTTCAAGTCATTCGGCGTTTCCAGGCGACCGTGACGGGTGGTCAATATGCAAGCAAGGAACAGGCTATAGTTAGGAAATTCATGAAGGTCAACAACCATGTGACGTATAACCATCAAGAGGCTGCGAAGTATGATAACCACACAGAGAATGCTTTGTTATTGTATATGGCATGTACTCATGCTAGTAATCCAGTGTATGCTACTTTGAAAATCAGGATCTATTTCTATGATTCTGTTCAGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPYVSRAAAPTVLVTNKRRSWANRPMNRKPRIYRMYKSPDVPRGCEGPCKVQSYEQRHDVAHVGKVICVSDVTRGNGLTHRVGKRFCIKSVYVLGKIWMDENIKTKNHTNTVMFFLVRDRRPFGTPQDFGQVFNMYDNEPSTATVKNDNRDRFQVIRRFQATVTGGQYASKEQAIVRKFMKVNNHVTYNHQEAAKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSVQN |
|
NCBI Accession
|
YP_001285750.1
|
|
Location
|
1057-1461 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGGAGAGAATGGCGTATATATCTGGACGGTCAACAATCCCCTGTATTTCAAAATAACACAACACCACGAGAGGCCATTCATGATGAAACACGACGTAATCACAGTGCAGGTCCAGTTCAACTACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTAATCTGCCAAATCTGGACTCGTTTACGTCCTCAGACCTCGCGTTTCTTAAGAGTATTTAAATATCAATGTATGAAATATTTAGACATGTTAGGAGTAATTAGCATCAACAATGTAATTAGAGCAATTAATCATGTATTGTACAATGTATTGGAAGGCACAATTGATGCACATCTCTCAAATATAATAAAATTCAACATTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAAQGENGVYIWTVNNPLYFKITQHHERPFMMKHDVITVQVQFNYNLRKALGIHKCFLICQIWTRLRPQTSRFLRVFKYQCMKYLDMLGVISINNVIRAINHVLYNVLEGTIDAHLSNIIKFNIY |
|
NCBI Accession
|
YP_001285751.1
|
|
Location
|
1202-1606 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP protein |
|
Coding Region
|
ATGCAATCTTCGTCACCCTCGAGGGCCCACTCTACTCAGGTACCCATCAAAGTGCGACACAGAATCGCCAAGAAGACAACTAGAAGAAGACGAGTTGATCTCCCTTGTGGGTGTTCATTTTTCGTCGCTCTCAAGTGTCATAACCATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGGAGAGAATGGCGTATATATCTGGACGGTCAACAATCCCCTGTATTTCAAAATAACACAACACCACGAGAGGCCATTCATGATGAAACACGACGTAATCACAGTGCAGGTCCAGTTCAACTACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTAATCTGCCAAATCTGGACTCGTTTACGTCCTCAGACCTCGCGTTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MQSSSPSRAHSTQVPIKVRHRIAKKTTRRRRVDLPCGCSFFVALKCHNHGFTHRGTHHCSSRREWRIYLDGQQSPVFQNNTTPREAIHDETRRNHSAGPVQLQPEESVGDTQMFSNLPNLDSFTSSDLAFLKSI |
|
NCBI Accession
|
YP_001285752.1
|
|
Location
|
1524-2594 |
|
Gene Name
|
AC1 |
|
Protein Name
|
rep protein |
|
Coding Region
|
ATGCCTCCTCCTAATAAATTCAGAATAAATGCCAAAAACTATTTCCTCACATATCCACGCTGTTCTCTTACCAAAGAGGAGGCACTTTCCCAAATTAAAGCCCTAGAAACACCAATTTCTAAATTATTCATCAGAATCTGCAGGGAACTCCACGAAGATGGAACTCCTCACCTGCATATCCTCATCCAATTCGAAGGGAAATTCCAGTGTAAAAATCAAAGATTCTTCGATCTCATATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAAAGCTCATCAGATGTTAAATCATACATGGAAAAAGACGGAGACGTGCTTGATCATGGAATTTTCCAGATCGATGGACGATCGGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCACTCAATTCAGGGGCCAAAGCATCGGCCCTCAATATATTAAGGGAGAAAGCTCCCAAAGATTTTGTTTTACAGTTCCATAATTTAAATAATAATTTAGATAGGATTTTTACTCATCCAATAGAAATTTACATTTCTCCTTTTTGTTCTTCTTCATTCGACCAAGTTCCAGAGGAACTTAATGAATGGGTTTCCGCAAACGTTGTCAATGCCGCTGCGCGGCCATTAAGACCGATAAGTATTGTGGTAGAGGGCGATAGTAGGACAGGGAAGACGATATGGGCCAGGTCTTTGGGACCACATAACTACTTATGCGGACATTTAGATTTAAGTCCAAAAGTGTACAACAACAGTGCCTGGTATAACGTCATTGATGACGTCGATCCCCACTATCTAAAGCACTTTAAAGAGTTCATGGGGGCCCAAAGAGACTGGCAAAGCAACACCAAATACGGGAAGCCAGTTCAAATTAAAGGGGGTATTCCCACTATCTTCCTCTGCAATCCAGGACCACATTCCAGCTATAAAGAGTTCTTGGATGAAGAAAAGAACAGCGCACTTAAAAATTGGGCTGTAAAGAATGCAATCTTCGTCACCCTCGAGGGCCCACTCTACTCAGGTACCCATCAAAGTGCGACACAGAATCGCCAAGAAGACAACTAG |
|
Protein Sequence
|
MPPPNKFRINAKNYFLTYPRCSLTKEEALSQIKALETPISKLFIRICRELHEDGTPHLHILIQFEGKFQCKNQRFFDLISPTRSAHFHPNIQGAKSSSDVKSYMEKDGDVLDHGIFQIDGRSARGGCQSANDAYAEALNSGAKASALNILREKAPKDFVLQFHNLNNNLDRIFTHPIEIYISPFCSSSFDQVPEELNEWVSANVVNAAARPLRPISIVVEGDSRTGKTIWARSLGPHNYLCGHLDLSPKVYNNSAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPHSSYKEFLDEEKNSALKNWAVKNAIFVTLEGPLYSGTHQSATQNRQEDN |
|
NCBI Accession
|
YP_001285753.1
|
|
Location
|
2144-2437 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGAACTCCTCACCTGCATATCCTCATCCAATTCGAAGGGAAATTCCAGTGTAAAAATCAAAGATTCTTCGATCTCATATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAAAGCTCATCAGATGTTAAATCATACATGGAAAAAGACGGAGACGTGCTTGATCATGGAATTTTCCAGATCGATGGACGATCGGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCACTCAATTCAGGGGCCAAAGCATCGGCCCTCAATATATTAA |
|
Protein Sequence
|
MELLTCISSSNSKGNSSVKIKDSSISYPQPGQHISIQTFRELKAHQMLNHTWKKTETCLIMEFSRSMDDRLEEVANLPTTHMPRHSIQGPKHRPSIY |