Eclipta yellow vein virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000895255.1 |
| Isolate |
Pakistan |
| Release date |
2015/2/22 |
| Submitter |
Khatri,S.M., Nawaz-ul-Rehman,M.S., Fauquet,C.M. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
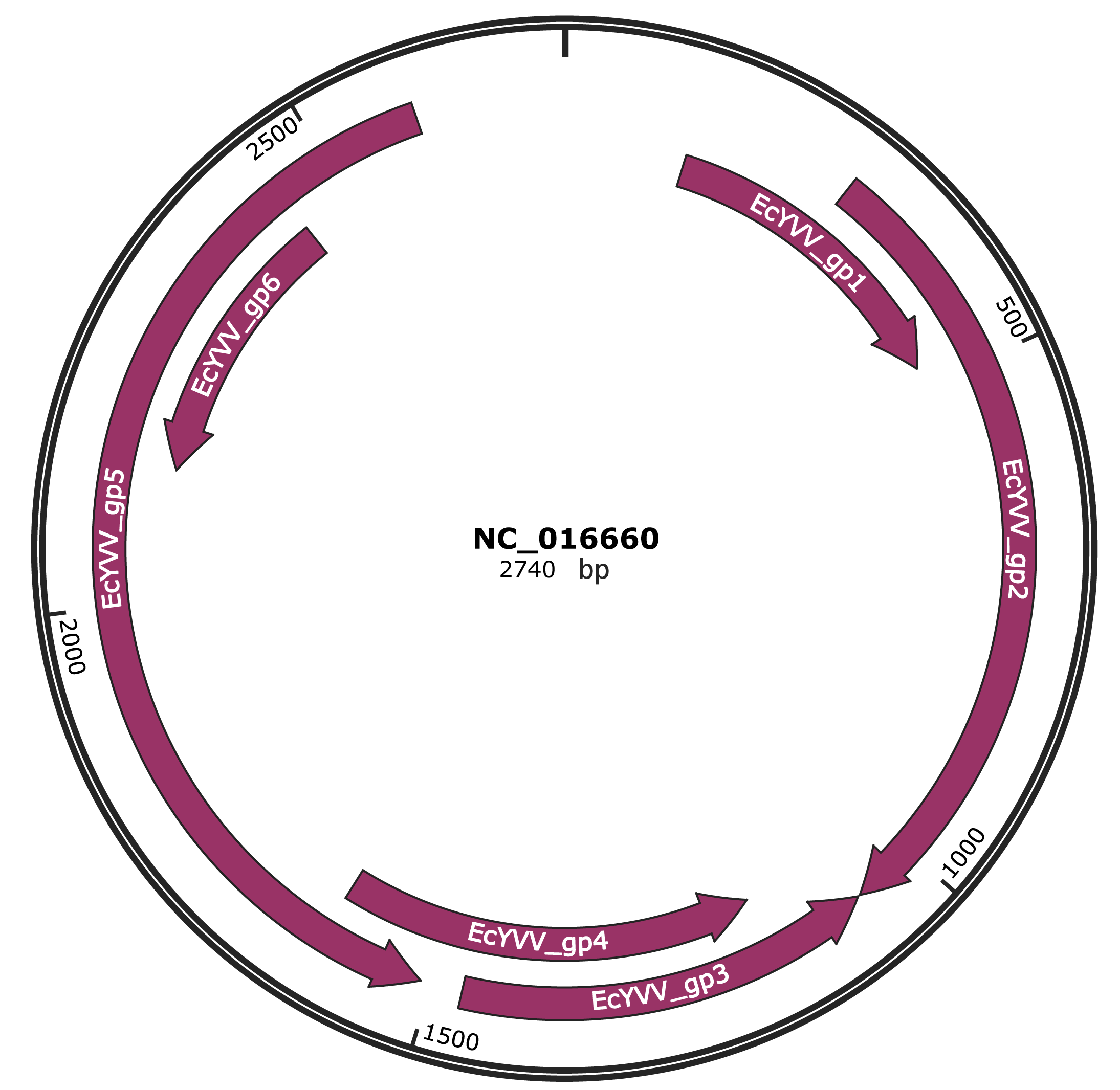
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTTGTGGGTCCCTCCACTAACTCTTGTCTGCCAATCATATGACGCGCTGAAAGCTTAAATAATTATCCCGCCTATTATAAGTACTTCGTCGCTAAGTTATAGTTTGAAAAATGTGGGATCCACTGTTAAACGAGTTCCCTGAGACTGTTCACGGGTTTCGTTGCATGCTTGCGATTAAATATCTTCAACAACTGTCTGAAGAATACTCACCTGATACGGTAGGTTACGATCTAATTCGCGATTTAATTTCTATTTTACGTTCCAGGAATTATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGTCGACTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGTCCCCACTGTCCGCGTCACAAAGTCTCGCATGTGGGCGAACAGGCCCATGAACCGGAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGATGTTCCAAGAGGCTGTGAGGGTCCGTGTAAGGTCCAATCCTTTGAGTCCAGACACGATGTAGTCCATATAGGTAAGGTCATGTGTATTAGTGATGTTACTCGCGGTACTGGGCTGACCCATAGAGTTGGGAAACGTTTCTGTGTTAAATCAGTCTATGTATTGGGTAAGATCTGGATGGATGAAAACATAAAGTCCAAAAACCACACTAACAATGTGATGTTCTTCTTGGTCCGTGATCGACGGCCTGTGGATAAGCCTCAGGATTTTGGAGAGGTCTTCAACATGTTTGACAACGAGCCCAGCACCGCTACTGTCAAGAATGTTCATCGAGATCGCTACCAGGTGTTGAGGAAATGGTATGCAACAGTTACGGGTGGTCAATATGGAGCTAAGGAACAGGCCTTGGTCAAGAAGTTTGTCCGAGTTAACAATTATGTTGTTTACAATCAGCAAGAGGCAGGGAAATATGAGAATCATTCTGAGAATGCCCTGATGTTGTATATGGCATGTACTCATGCCTCTAATCCAGTTTACGCCACTCTTAAGATTAGGATCTACTTCTACGATTCTGTAACCAATTGATATTAATAAAGATCGAATTTTATTTCTGAATTCATGTCTACGTACATAGTTTGTTCTATTTTATTGTACAATACATGATCTACTGCTCTAATAATCGAATTAATTGAGATTACACCCAGATTGTTGAGATACTTGAGGACTTGGGTCTTGAATACCTTTAAGAAAAGACCAGTCGGAGGGTGTAAGGTCGTCCAGATTTGGAAGGTCAGAAAACATTTGTGCACTCCCAGAGCTCTCCGAAGGTTGTAGTTGAATTGGATTCTGATCTTTATTAAGTCCATATTGGTCGTGAATGGCCGGTTGTCGTGGCTGAGGATCTTGAAATATAGGGGATTTGGAACGTCCCAGATATAGGCGCCATTCCATGCTTGAGCTGCAGTGATGGGTTCCCCTGTGCGTAAATCCATGGTTGAAGCAGTTAATAGATAAATAATAAGAACACCCGCATTCAAGATCTACTCTCCTCCTCCTGTTGCGCCTCTTCGCTTCCCTGTGCTGTACTTTGATTGGAACCTGAGTACAGTGGTCCCTCAAGGGTGACGAAGATCGCATTCTTCACTGCCCAGTTCTTTAGTGCGGTGTTCTTTTCCTCATCTAGGAATTCTTTATAACTGCTGTTGGGACCAGGATTGCAGAGGAAGATTGTTGGTATTCCGCCTTTAATTTGAACTGGCTTCCCGTACTTTGTGTTGGATTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTAAAGTGCTTGAGGAAGTGCGGATCTACGTCATCAATGACGTTATACCAAGCGTCGTTACTGTACACCTTTGGGCTTAGATCTAAATGCCCACATAAATAGTTATGTGGGCCTAAAGACCTAGCCCACATTGTCTTCCCAGTACGACTGTCACCCTCAATCACTATACTTTGAGGTCTCAAGGGCCGCGCAGCGGCACTGACGATGTTCTCGGCAGCCCACTCTTCAAGTTCTTCTGGAACTTGATCAAAGGAAGAGGAAGAAAAAGGAGAGACATAAACCTCCATTGGAGGTGTAAAAATCCTATCTAAATTAGCATTTAAATTATGAAATTGTAGTACATAATCTTTTGGTGCTAATTCTTTAATGATTCTAATAGCCTCTGACTTACTGCCTGCGTTAAGTGCTGCGGCGTAAGCGTCATTGGCTGACTGTTGTCCCCCTCTTGCAGATCTTCCATCGATCTGAAACTCTCCCCAGTCGAGGGTGTCTCCGTCCTTCTCGACGTATGACTTGACGTCCGAGCTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGAGACCAAGTCGAAGAATCGGTGATTCGTGCACTGGTACTTTCCCTCGAACTGGATGAGCATGTGTAGATGAGGTTTCCCATTTTGATGAAGCTCTCTGCAGATCTTGATATATTTTATTGAAGTTGGGGTATTTAGGTTTTTGATTTGGGAAAGTGCTTCCTCTTTTGTTAGAGAGCAGTCGGGATAAGTGAGGAAGTAGTTTTTGGCGTTTAATTTAAAGGCACGTGGCATTTTGGCAATCGGTGTACACTCTAATTCTCTGGTAATCGGTGTAATGGGGTACAATATATAGGTGTACACCAAATGGCATTATTGTAATTTGGGAAAGTAATTCAAAATCCTCACGCTCCAAAAAGCGGCCATCCGTCTAATATT
Gene Information
|
NCBI Accession
|
YP_005087576.1
|
|
Location
|
132-479 |
|
Protein Name
|
V2 |
|
Coding Region
|
ATGTGGGATCCACTGTTAAACGAGTTCCCTGAGACTGTTCACGGGTTTCGTTGCATGCTTGCGATTAAATATCTTCAACAACTGTCTGAAGAATACTCACCTGATACGGTAGGTTACGATCTAATTCGCGATTTAATTTCTATTTTACGTTCCAGGAATTATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGTCGACTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGTCCCCACTGTCCGCGTCACAAAGTCTCGCATGTGGGCGAACAGGCCCATGAACCGGAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPETVHGFRCMLAIKYLQQLSEEYSPDTVGYDLIRDLISILRSRNYVEASCRYRHFYPRVEGASSTELRQPLCNPCSCPHCPRHKVSHVGEQAHEPEAQNVQDVQKP |
|
NCBI Accession
|
YP_005087577.1
|
|
Location
|
292-1062 |
|
Protein Name
|
V1 |
|
Coding Region
|
ATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGTCGACTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGTCCCCACTGTCCGCGTCACAAAGTCTCGCATGTGGGCGAACAGGCCCATGAACCGGAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGATGTTCCAAGAGGCTGTGAGGGTCCGTGTAAGGTCCAATCCTTTGAGTCCAGACACGATGTAGTCCATATAGGTAAGGTCATGTGTATTAGTGATGTTACTCGCGGTACTGGGCTGACCCATAGAGTTGGGAAACGTTTCTGTGTTAAATCAGTCTATGTATTGGGTAAGATCTGGATGGATGAAAACATAAAGTCCAAAAACCACACTAACAATGTGATGTTCTTCTTGGTCCGTGATCGACGGCCTGTGGATAAGCCTCAGGATTTTGGAGAGGTCTTCAACATGTTTGACAACGAGCCCAGCACCGCTACTGTCAAGAATGTTCATCGAGATCGCTACCAGGTGTTGAGGAAATGGTATGCAACAGTTACGGGTGGTCAATATGGAGCTAAGGAACAGGCCTTGGTCAAGAAGTTTGTCCGAGTTAACAATTATGTTGTTTACAATCAGCAAGAGGCAGGGAAATATGAGAATCATTCTGAGAATGCCCTGATGTTGTATATGGCATGTACTCATGCCTCTAATCCAGTTTACGCCACTCTTAAGATTAGGATCTACTTCTACGATTCTGTAACCAATTGA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPYATRAVVPTVRVTKSRMWANRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKSKNHTNNVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWYATVTGGQYGAKEQALVKKFVRVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
|
NCBI Accession
|
YP_005087578.1
|
|
Location
|
1065-1469 |
|
Protein Name
|
C3 |
|
Coding Region
|
ATGGATTTACGCACAGGGGAACCCATCACTGCAGCTCAAGCATGGAATGGCGCCTATATCTGGGACGTTCCAAATCCCCTATATTTCAAGATCCTCAGCCACGACAACCGGCCATTCACGACCAATATGGACTTAATAAAGATCAGAATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTGCACAAATGTTTTCTGACCTTCCAAATCTGGACGACCTTACACCCTCCGACTGGTCTTTTCTTAAAGGTATTCAAGACCCAAGTCCTCAAGTATCTCAACAATCTGGGTGTAATCTCAATTAATTCGATTATTAGAGCAGTAGATCATGTATTGTACAATAAAATAGAACAAACTATGTACGTAGACATGAATTCAGAAATAAAATTCGATCTTTATTAA |
|
Protein Sequence
|
MDLRTGEPITAAQAWNGAYIWDVPNPLYFKILSHDNRPFTTNMDLIKIRIQFNYNLRRALGVHKCFLTFQIWTTLHPPTGLFLKVFKTQVLKYLNNLGVISINSIIRAVDHVLYNKIEQTMYVDMNSEIKFDLY |
|
NCBI Accession
|
YP_005087579.1
|
|
Location
|
1162-1614 |
|
Protein Name
|
C2 |
|
Coding Region
|
ATGCGATCTTCGTCACCCTTGAGGGACCACTGTACTCAGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAGGCGCAACAGGAGGAGGAGAGTAGATCTTGAATGCGGGTGTTCTTATTATTTATCTATTAACTGCTTCAACCATGGATTTACGCACAGGGGAACCCATCACTGCAGCTCAAGCATGGAATGGCGCCTATATCTGGGACGTTCCAAATCCCCTATATTTCAAGATCCTCAGCCACGACAACCGGCCATTCACGACCAATATGGACTTAATAAAGATCAGAATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTGCACAAATGTTTTCTGACCTTCCAAATCTGGACGACCTTACACCCTCCGACTGGTCTTTTCTTAAAGGTATTCAAGACCCAAGTCCTCAAGTATCTCAACAATCTGGGTGTAATCTCAATTAA |
|
Protein Sequence
|
MRSSSPLRDHCTQVPIKVQHREAKRRNRRRRVDLECGCSYYLSINCFNHGFTHRGTHHCSSSMEWRLYLGRSKSPIFQDPQPRQPAIHDQYGLNKDQNPIQLQPSESSGSAQMFSDLPNLDDLTPSDWSFLKGIQDPSPQVSQQSGCNLN |
|
NCBI Accession
|
YP_005087580.1
|
|
Location
|
1511-2596 |
|
Protein Name
|
C1 |
|
Coding Region
|
ATGCCACGTGCCTTTAAATTAAACGCCAAAAACTACTTCCTCACTTATCCCGACTGCTCTCTAACAAAAGAGGAAGCACTTTCCCAAATCAAAAACCTAAATACCCCAACTTCAATAAAATATATCAAGATCTGCAGAGAGCTTCATCAAAATGGGAAACCTCATCTACACATGCTCATCCAGTTCGAGGGAAAGTACCAGTGCACGAATCACCGATTCTTCGACTTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCGGACGTCAAGTCATACGTCGAGAAGGACGGAGACACCCTCGACTGGGGAGAGTTTCAGATCGATGGAAGATCTGCAAGAGGGGGACAACAGTCAGCCAATGACGCTTACGCCGCAGCACTTAACGCAGGCAGTAAGTCAGAGGCTATTAGAATCATTAAAGAATTAGCACCAAAAGATTATGTACTACAATTTCATAATTTAAATGCTAATTTAGATAGGATTTTTACACCTCCAATGGAGGTTTATGTCTCTCCTTTTTCTTCCTCTTCCTTTGATCAAGTTCCAGAAGAACTTGAAGAGTGGGCTGCCGAGAACATCGTCAGTGCCGCTGCGCGGCCCTTGAGACCTCAAAGTATAGTGATTGAGGGTGACAGTCGTACTGGGAAGACAATGTGGGCTAGGTCTTTAGGCCCACATAACTATTTATGTGGGCATTTAGATCTAAGCCCAAAGGTGTACAGTAACGACGCTTGGTATAACGTCATTGATGACGTAGATCCGCACTTCCTCAAGCACTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAATCCAACACAAAGTACGGGAAGCCAGTTCAAATTAAAGGCGGAATACCAACAATCTTCCTCTGCAATCCTGGTCCCAACAGCAGTTATAAAGAATTCCTAGATGAGGAAAAGAACACCGCACTAAAGAACTGGGCAGTGAAGAATGCGATCTTCGTCACCCTTGAGGGACCACTGTACTCAGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAGGCGCAACAGGAGGAGGAGAGTAGATCTTGA |
|
Protein Sequence
|
MPRAFKLNAKNYFLTYPDCSLTKEEALSQIKNLNTPTSIKYIKICRELHQNGKPHLHMLIQFEGKYQCTNHRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYVEKDGDTLDWGEFQIDGRSARGGQQSANDAYAAALNAGSKSEAIRIIKELAPKDYVLQFHNLNANLDRIFTPPMEVYVSPFSSSSFDQVPEELEEWAAENIVSAAARPLRPQSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNTALKNWAVKNAIFVTLEGPLYSGSNQSTAQGSEEAQQEEESRS |
|
NCBI Accession
|
YP_005087581.1
|
|
Location
|
2143-2445 |
|
Protein Name
|
C4 |
|
Coding Region
|
ATGGGAAACCTCATCTACACATGCTCATCCAGTTCGAGGGAAAGTACCAGTGCACGAATCACCGATTCTTCGACTTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCGGACGTCAAGTCATACGTCGAGAAGGACGGAGACACCCTCGACTGGGGAGAGTTTCAGATCGATGGAAGATCTGCAAGAGGGGGACAACAGTCAGCCAATGACGCTTACGCCGCAGCACTTAACGCAGGCAGTAAGTCAGAGGCTATTAGAATCATTAAAGAATTAG |
|
Protein Sequence
|
MGNLIYTCSSSSRESTSARITDSSTWSPQPGQHISIRTFRELNQARTSSHTSRRTETPSTGESFRSMEDLQEGDNSQPMTLTPQHLTQAVSQRLLESLKN |