East African cassava mosaic Zanzibar virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000845125.1 |
| Isolate |
Tanzania: Zanzibar, Uguja Island |
| Release date |
2015/2/12 |
| Submitter |
Maruthi,M.N., Seal,S., Colvin,J., Briddon,R.W., Bull,S.E., Seal,S.E. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
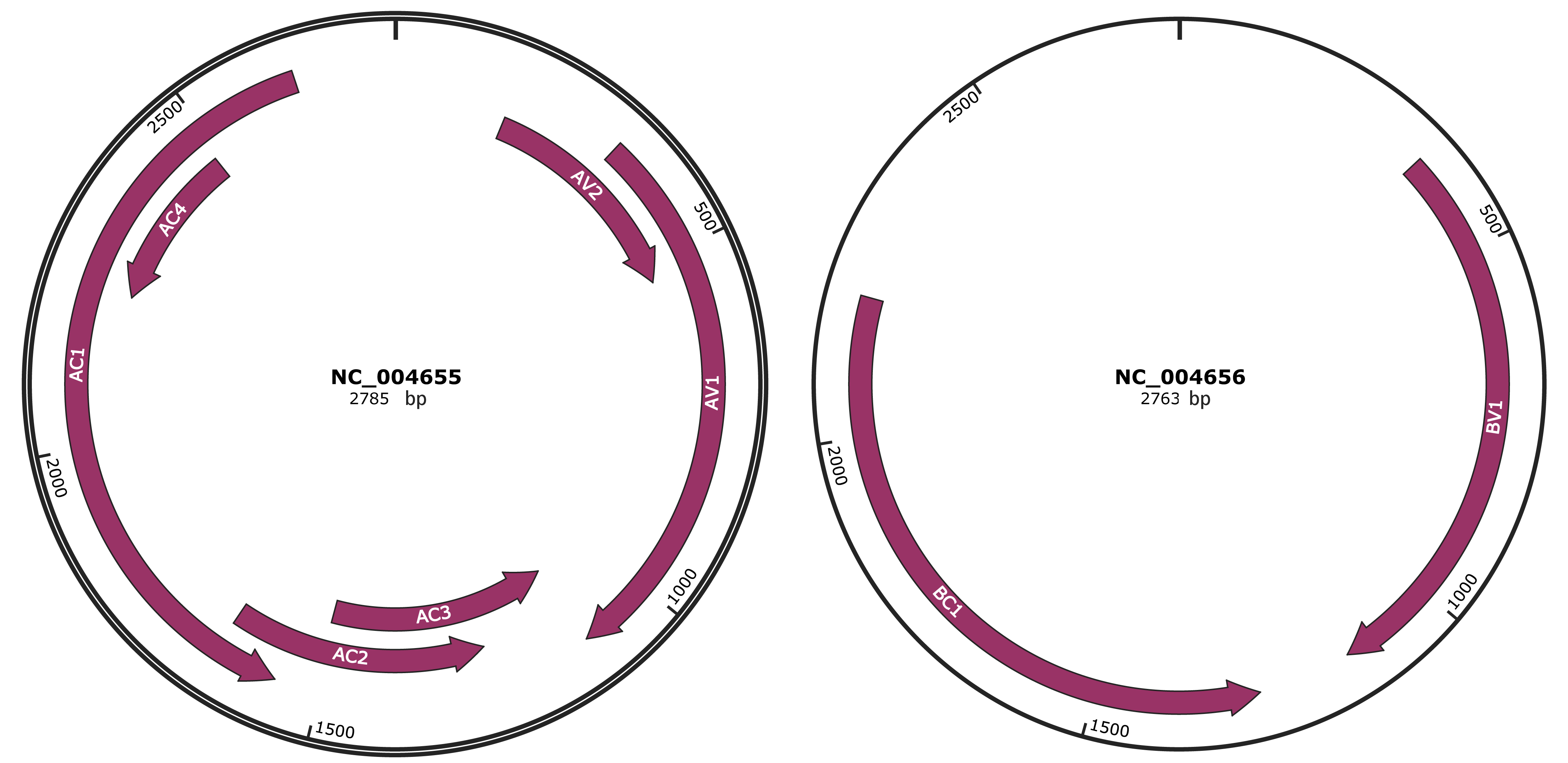
JBrowse
Genome
ACCGGTTGGCCGCGCCCGAAAAAGCAGGTGGACCCCACAGGATGGCCGCGCCCGTGAAAGAAAGTGGTCCCCGCGCACTTGTTTCGGTCAGCCAGTCATATTCACGCGTGGAAGTCTAGATATTTGTTGTTTGTCTTTATAGACTTCGTCGCGAAGTAGTGGAGCGCGTCAACATGTGGGATCCATTGTTAAACGATTTCCCTGAAACCGTTCACGGTTTCCGTTCCATGCTTGCTGTTAAATACCTGTTACATCTTGAACAGGAATACGATCGCGGTACTGTCGGGGCTGAGTATATACGGGATCTAATAGGGGTTCTACGGTGTAAGAGTTATGTCGAAGCGACCAGGAGATATAATAATCTCAACACCCGTATCCAAGGTGCGGAGGAGGCTGAACTTCGACAGCCCATACACGAACCGTGTTGTTGCCCCCACTGTCCGCGTCACCAGAAGCAAAATATGGGCCAACAGGCCCATGTATCGGAAGCCCAAGATGTACAGACTGTATCGAAGCCCAGATGTTCCTAAGGGCTGTGAAGGCCCATGTAAGGTTCAGTCGTATGAACAGAGGGATGATGTTAAGCACACTGGTATGGTTCGATGTGTCAGTGATGTTACGCGTGGGCCAGGCATTACCCATAGAGTCGGGAAGAGGTTCTGTGTGAAGTCCATATATATATTGGGCAAGATCTGGATGGATGAGAATATCAAGAAGCAAAATCATACGAACCATGTTATGTTCTTCCTCGTTCGAGATAGAAGGCCTTATGGGCCGAGTCCTCAAGATTTTGGACAAGTGTTCAACATGTTTGATAATGAACCGACTACGGCAACCGTGAAGAATGATCTTAGGGACCGGTATCAGGTGTTACGTAAATTCTATGCAACTGTTGTTGGTGGACCCTCTGGGATGAAGGAACAAGCGCTGGTTAAGAGGTTTTTTAAGATCAATAATCATGTAGTGTATAATCATCAGGAACAGGCCAAGTATGAGAATCATACTGAGAATGCGTTGTTATTGTATATGGCATGTACACATGCCTCGAATCCTGTGTACGCTACGCTGAAAATACGCATCTATTTCTATGATGCAGTGACAAATTAATAAAGGTTGAATTTTATTGCATGTTGCTCCGTAACTTGGAGTGTGTTTAGTAATACATTGTACAGAACATGAGCAACAGCTTGAAGTACAGTGTTAATGGAAATAACGCCTATCATATCTAAATACTTGAGCACCTGATATTTAAATACTCTTAAGAAAAGACCAGTCTGAGGCCGTAAGGTCGTCCAGACCTTGAAGTTGAGAAAACATTTGTGAATCCCCAGCGCCTTCCTCAGGTTGTGGTTGAACCGTATCTGGAGTGTGATGATGTCGTGGTTCATGTTCCCTGGCCTCCTGTCGTGGTTGGTGATTTCGAAATAGAGGGGATTTGTTATTTCCCAGGTAAAAACGCCATTCTTGGCTTGAGGCGCAGTGATGAGTTCCCCTGTGCGAGAATCCATGGTTGATGCAGTCGATATGGAGATAGAACGAGCAGCCGCATTCGAGGTCTACCCGCCTACGTCTGACGGCCCTGGTCTTCGCTGTGCGGTGTTGGACTTTGATGGGCACTAGAGAACAATGGCTCGTGGAGGGTGATGAAGGTGGCATTCTTTAAAGCCCAGGCTTTAAGGGACTGGTTCTTTTCCTCGTCCAGAAACTCTTTATATGATGATGTTGGTCCTGGATTGCAGAGGAAGATAGTGGGAATGCCACCTTTAATTTGAATTGGCTTCCCGTACTTTGTATTGCTTTGCCAGTCTCTTTGGGCCCCCATGAATTCTTTGAAGTGCTTTAGATAGTGGGGATCGACGTCATCAATGACGTTGTACCAGGCGTCGTTGCTGTAGACCTTTGGACTGAGATCCAGGTGTCCACATAAGTAGTTGTGTGGACCCAGAGAGCGGGCCCACATTGTCTTTCCGGTCCTACTATCGCCCTCGATGACGATACTATTAGGTCTCCATGGCCGCGCAGCGGAACCCATCACGTTCTCGGAAACCCAGACTTCAAGTTCCTCAGGAACGTTAGTAAAAGAAGAAGACAGAAAAGGAGAAACATAAGGAGCTGGTGGCTCTTGAAAAATCCTATCTAAATTACTACTTAAGTTATGATATTGAAAAATAAATTCTTTTGGGAGTTTCTCCTTAATAATTAGAAGTGCTGCTGCCTTGGAACCTGAGTTTAATGCTTCGGCACATGCGTCATTAGCATTGTGGCAGCCGCCTCTAGCCGATCTGGCGTCGATCTGGAATTCGCCCCACTCAGTGGTATCCCCATCTTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCTTGAATGTTCGGATGGAAATGTGTTGATCGTGTTGGGGATACCAGGTCGAAGAATCGCTTATTTGTGCATGAGAATTTGCCTTCGAACTGAATAAGCATGTGGAGATGAGGTTGCCCATCATCGTGAAGTTCTCGGCAAACTTTGATGTATTTCTTGTTTGTGGGAGTTGGGATGTTTAATATTTGGGATAATGCTTCGTGTTTAGATAGAGAACATTTGGGATATGTGAGAAAATAGTTTTTGGCCTGTATTTTAAAACGCTTGGGGGGAGTCATTTATGCGAGAGCAATTGGAGACACCTCGGTTGATGTCTCTACTGAATTGGAGACAATATATAGTGTCTCCAAATGGCATAATGGTAATTAGGTAGATCTATTTTCAAAATTTGAACCAAAAGCGGCCATCCGATTAATATT
ACCGGATGGCCGCGCCCGAAAAAGCAGATGGGCCCCAGAATGGCCCCCACGCACTAAGTAATGTCAGCCAACCATGTGCAAGACTGGGAGACTCGGTAGTTACGAAAGGAGGATGAAGTGGTCCCTACGCACTAAGTTTGACAGGCAATTTTATTGCTATGTGTGTATCATATTTTCATAGGTGTGTTACGGGTCAATCTAAAGGTATGTTATGGGGCCTATTCATAAAAAACCAAAATATAGGTTCCTATTTACATATTGATTATATTTTTATGTGCGGATATATGATCCGCCACGTGTTTATAATGGATATGGATTGTCCTATAAATATGTGGCAATCCTCCCGTTCGTCAATGCAAGATGTATTCTGTATACAGACGTGGGTATAAGACGCCGTATAGGAGTCCGTATGGCTCGCGTGTAACACCATATGTGAATCGTAAGACCGCTGTGAAACAGACGGCGAAATCTCGTGTATCGCGAAAGTTGGCGTATGAATCGCCAAAAGGTCTATATACGCGACGCTCATTGGAGGATATCCATAATGGGGCTTCCTTGAAGTTGCCTCAACAGGGGGATTATACGTCCTACGTGACACTCCCATGTCGAGGCATCGATGGTAATGGGGGTAGGTCTGTTGATCATATAAAATTATTAAGCTTGAGGGTTTCTGGGACCGTCAACATCAGTCAATCCGGTGGTGATGACAATATGGGAGAGAGAACGACCATGAGGGGTATTTTTTTCATGGTTTGTTTTGTTGATAAGAAACCTTTCGTTCCAGAGGGGGTCAGCATATTGCCGACGTTCAATGAGTTGTTTGGGGAATATGAATCCGTGTATGGCATGCCTAGGCTGAAGGAAAACGTCCGTCACCGTTATCGTGTTATTGGGACGTCGAAATTATATATAACGACCGATGAAGATCATATCCAGAAGCCTTTTAGTCTACGTCGAAGACTAAGTGGAGGGAAATATCCTATATGGTCGTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGTAACTATAAAAATATAAATAAGAACGCTATACTCGTTAGTTATGTGTGGGTTTCGCTATGTCGGACCACGTGTGATGTGTATTCGCAGTTTGTACTTAATTACGTCGGCTGATAATAAAACTATATAAGTGTTTTATGGACATTAATGATGTGGGATCGAACTAAACAAGAGATGAACATTAATGGGAAGCATAAAGAGTTTTATTATGTGCTGAAGCAAATATGGTACATATAAATGGTTTATTACAATGGCCTTGGTGCTTCGGATTTGATCTTGATGAGGCACCTGTTAATGGTACTCTCAAGCAGTGTCTCGAGATCCTTTCTGGATACGGAGTCGGATTGGGTCTGTGATACCGAGTCTCCTGGGTCTAACTCTGGTGTGTTTAATCTGTGTAGTCTCTGGTAAGGATATTCGGTGGACTCGTTGTCTAAGTCTGTTGGTGTTGTCGATGGGTCCATTCTCATGGACTGTGAACGAAAGTGTTCCAGCCTTGCTGGGCCGGATGAGCTTGGTAGCCCAATCTGAGACTTTGTGGCCCATGTTTCTCCAGGTAGGATGGTGATGGGCCTGTGGGTTATGGGTCGTTGACTATGAGCAGTTGGAGTTGGATTTAGTAATCTCCGTCTTGTTTCTCCTTTTTCCACGGACCAGAAGTCTATGCAGTCTTTTGTGTATCCCTTGGATAAGATGTTAATTGTTGGGGGTTTGAAACGTATGTCCGTGGAATGTTTGGCCGAGGATAATCTGAGCTTGGCCTTGATGGATGCGAATTTCACGCCTTCTATGACGTTTGAGTCTTCGACTCTGTATAGGATTTTCCAAGGGGAGGGTTCTGAAATCGAGAAATATGTAGAAGAGAAGTAGTGGAGGTCTACGTTGCAAGCTATGGGGAAAGTGAATGCTGCCTGAGCTGCGTCTTCAAGGCTGACGCGATTGTCTCTGATTTCTACGATAACCGACCCAGTTGCGTTAAATGGGACCTGGTTGCGGTATTCAATTATAATGTGGTCGATTTTCATACATCGGCCTTTGAGTCGCATGGTCGCCTGCTCGAATGAGCTCGGAAATTGGAGATTGATTGGTGCAGCACCGTTGGTTAATGCGTACTCTGTGCGTTTGCTGTTGATGTAATTATTGTCTGTGACGGTGAATTGGTGGTCCATTCTAGGAATGAAAAAAACAGGGTTATTAAACGGAGAGAAGTCAGAACAAGGGATATAAAATGTCTTGTAGACATGTAAGCATATATGCATTTGGTATATAGAAGAACACACTAAATCAGAACAAGGATCATATATGTTAAATTGGCCGCGCAGCGGATTGGAATTCAGGAAAATCTACCAACAAAGAAAAAAGCCGAATGGTGTTATGTGATGTAAATCACTTACATAATCACGGATGAAGCAGTCTGGAGTGAATTCCTGGTTCAATTAGGAGAAAAAAGAAGATATAAAAGTTAACGAAATAAAAGTAAAACGTATTGGGATAAAAAGGAAAGTGAGCATATGTTATGCGCCGTGTCGTTAAATGATATGCTATGAGGTGTTTATATAGGCGTTAATAAGCGACAGGTGGTAGAGAGAGAAAGAAGAGAGAAGCGAGAGCAATTGGAGACACCTCGGTGGATGTCTCTACGGAATTGGAGACAATATATAGTGTCTCCAAATGGCATAATGGTAAATAGGCATAACTATTTTCAAAAGTTGAACCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
NP_808883.1
|
|
Location
|
174-530 |
|
Gene Name
|
AV2 |
|
Protein Name
|
precoat protein |
|
Coding Region
|
ATGTGGGATCCATTGTTAAACGATTTCCCTGAAACCGTTCACGGTTTCCGTTCCATGCTTGCTGTTAAATACCTGTTACATCTTGAACAGGAATACGATCGCGGTACTGTCGGGGCTGAGTATATACGGGATCTAATAGGGGTTCTACGGTGTAAGAGTTATGTCGAAGCGACCAGGAGATATAATAATCTCAACACCCGTATCCAAGGTGCGGAGGAGGCTGAACTTCGACAGCCCATACACGAACCGTGTTGTTGCCCCCACTGTCCGCGTCACCAGAAGCAAAATATGGGCCAACAGGCCCATGTATCGGAAGCCCAAGATGTACAGACTGTATCGAAGCCCAGATGTTCCTAA |
|
Protein Sequence
|
MWDPLLNDFPETVHGFRSMLAVKYLLHLEQEYDRGTVGAEYIRDLIGVLRCKSYVEATRRYNNLNTRIQGAEEAELRQPIHEPCCCPHCPRHQKQNMGQQAHVSEAQDVQTVSKPRCS |
|
NCBI Accession
|
NP_808884.1
|
|
Location
|
334-1107 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCAGGAGATATAATAATCTCAACACCCGTATCCAAGGTGCGGAGGAGGCTGAACTTCGACAGCCCATACACGAACCGTGTTGTTGCCCCCACTGTCCGCGTCACCAGAAGCAAAATATGGGCCAACAGGCCCATGTATCGGAAGCCCAAGATGTACAGACTGTATCGAAGCCCAGATGTTCCTAAGGGCTGTGAAGGCCCATGTAAGGTTCAGTCGTATGAACAGAGGGATGATGTTAAGCACACTGGTATGGTTCGATGTGTCAGTGATGTTACGCGTGGGCCAGGCATTACCCATAGAGTCGGGAAGAGGTTCTGTGTGAAGTCCATATATATATTGGGCAAGATCTGGATGGATGAGAATATCAAGAAGCAAAATCATACGAACCATGTTATGTTCTTCCTCGTTCGAGATAGAAGGCCTTATGGGCCGAGTCCTCAAGATTTTGGACAAGTGTTCAACATGTTTGATAATGAACCGACTACGGCAACCGTGAAGAATGATCTTAGGGACCGGTATCAGGTGTTACGTAAATTCTATGCAACTGTTGTTGGTGGACCCTCTGGGATGAAGGAACAAGCGCTGGTTAAGAGGTTTTTTAAGATCAATAATCATGTAGTGTATAATCATCAGGAACAGGCCAAGTATGAGAATCATACTGAGAATGCGTTGTTATTGTATATGGCATGTACACATGCCTCGAATCCTGTGTACGCTACGCTGAAAATACGCATCTATTTCTATGATGCAGTGACAAATTAA |
|
Protein Sequence
|
MSKRPGDIIISTPVSKVRRRLNFDSPYTNRVVAPTVRVTRSKIWANRPMYRKPKMYRLYRSPDVPKGCEGPCKVQSYEQRDDVKHTGMVRCVSDVTRGPGITHRVGKRFCVKSIYILGKIWMDENIKKQNHTNHVMFFLVRDRRPYGPSPQDFGQVFNMFDNEPTTATVKNDLRDRYQVLRKFYATVVGGPSGMKEQALVKRFFKINNHVVYNHQEQAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
|
NCBI Accession
|
NP_808885.1
|
|
Location
|
1104-1508 |
|
Gene Name
|
AC3 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCCAAGAATGGCGTTTTTACCTGGGAAATAACAAATCCCCTCTATTTCGAAATCACCAACCACGACAGGAGGCCAGGGAACATGAACCACGACATCATCACACTCCAGATACGGTTCAACCACAACCTGAGGAAGGCGCTGGGGATTCACAAATGTTTTCTCAACTTCAAGGTCTGGACGACCTTACGGCCTCAGACTGGTCTTTTCTTAAGAGTATTTAAATATCAGGTGCTCAAGTATTTAGATATGATAGGCGTTATTTCCATTAACACTGTACTTCAAGCTGTTGCTCATGTTCTGTACAATGTATTACTAAACACACTCCAAGTTACGGAGCAACATGCAATAAAATTCAACCTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQAKNGVFTWEITNPLYFEITNHDRRPGNMNHDIITLQIRFNHNLRKALGIHKCFLNFKVWTTLRPQTGLFLRVFKYQVLKYLDMIGVISINTVLQAVAHVLYNVLLNTLQVTEQHAIKFNLY |
|
NCBI Accession
|
NP_808886.1
|
|
Location
|
1249-1656 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCCACCTTCATCACCCTCCACGAGCCATTGTTCTCTAGTGCCCATCAAAGTCCAACACCGCACAGCGAAGACCAGGGCCGTCAGACGTAGGCGGGTAGACCTCGAATGCGGCTGCTCGTTCTATCTCCATATCGACTGCATCAACCATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCCAAGAATGGCGTTTTTACCTGGGAAATAACAAATCCCCTCTATTTCGAAATCACCAACCACGACAGGAGGCCAGGGAACATGAACCACGACATCATCACACTCCAGATACGGTTCAACCACAACCTGAGGAAGGCGCTGGGGATTCACAAATGTTTTCTCAACTTCAAGGTCTGGACGACCTTACGGCCTCAGACTGGTCTTTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MPPSSPSTSHCSLVPIKVQHRTAKTRAVRRRRVDLECGCSFYLHIDCINHGFSHRGTHHCASSQEWRFYLGNNKSPLFRNHQPRQEAREHEPRHHHTPDTVQPQPEEGAGDSQMFSQLQGLDDLTASDWSFLKSI |
|
NCBI Accession
|
NP_808887.1
|
|
Location
|
1565-2644 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication protein |
|
Coding Region
|
ATGACTCCCCCCAAGCGTTTTAAAATACAGGCCAAAAACTATTTTCTCACATATCCCAAATGTTCTCTATCTAAACACGAAGCATTATCCCAAATATTAAACATCCCAACTCCCACAAACAAGAAATACATCAAAGTTTGCCGAGAACTTCACGATGATGGGCAACCTCATCTCCACATGCTTATTCAGTTCGAAGGCAAATTCTCATGCACAAATAAGCGATTCTTCGACCTGGTATCCCCAACACGATCAACACATTTCCATCCGAACATTCAAGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAAGATGGGGATACCACTGAGTGGGGCGAATTCCAGATCGACGCCAGATCGGCTAGAGGCGGCTGCCACAATGCTAATGACGCATGTGCCGAAGCATTAAACTCAGGTTCCAAGGCAGCAGCACTTCTAATTATTAAGGAGAAACTCCCAAAAGAATTTATTTTTCAATATCATAACTTAAGTAGTAATTTAGATAGGATTTTTCAAGAGCCACCAGCTCCTTATGTTTCTCCTTTTCTGTCTTCTTCTTTTACTAACGTTCCTGAGGAACTTGAAGTCTGGGTTTCCGAGAACGTGATGGGTTCCGCTGCGCGGCCATGGAGACCTAATAGTATCGTCATCGAGGGCGATAGTAGGACCGGAAAGACAATGTGGGCCCGCTCTCTGGGTCCACACAACTACTTATGTGGACACCTGGATCTCAGTCCAAAGGTCTACAGCAACGACGCCTGGTACAACGTCATTGATGACGTCGATCCCCACTATCTAAAGCACTTCAAAGAATTCATGGGGGCCCAAAGAGACTGGCAAAGCAATACAAAGTACGGGAAGCCAATTCAAATTAAAGGTGGCATTCCCACTATCTTCCTCTGCAATCCAGGACCAACATCATCATATAAAGAGTTTCTGGACGAGGAAAAGAACCAGTCCCTTAAAGCCTGGGCTTTAAAGAATGCCACCTTCATCACCCTCCACGAGCCATTGTTCTCTAGTGCCCATCAAAGTCCAACACCGCACAGCGAAGACCAGGGCCGTCAGACGTAG |
|
Protein Sequence
|
MTPPKRFKIQAKNYFLTYPKCSLSKHEALSQILNIPTPTNKKYIKVCRELHDDGQPHLHMLIQFEGKFSCTNKRFFDLVSPTRSTHFHPNIQGAKSSSDVKSYIDKDGDTTEWGEFQIDARSARGGCHNANDACAEALNSGSKAAALLIIKEKLPKEFIFQYHNLSSNLDRIFQEPPAPYVSPFLSSSFTNVPEELEVWVSENVMGSAARPWRPNSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEFLDEEKNQSLKAWALKNATFITLHEPLFSSAHQSPTPHSEDQGRQT |
|
NCBI Accession
|
NP_808888.1
|
|
Location
|
2230-2487 |
|
Gene Name
|
AC4 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGGGCAACCTCATCTCCACATGCTTATTCAGTTCGAAGGCAAATTCTCATGCACAAATAAGCGATTCTTCGACCTGGTATCCCCAACACGATCAACACATTTCCATCCGAACATTCAAGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAAGATGGGGATACCACTGAGTGGGGCGAATTCCAGATCGACGCCAGATCGGCTAGAGGCGGCTGCCACAATGCTAATGACGCATGTGCCGAAGCATTAA |
|
Protein Sequence
|
MGNLISTCLFSSKANSHAQISDSSTWYPQHDQHISIRTFKELNPAPTSSPTSTKMGIPLSGANSRSTPDRLEAAATMLMTHVPKH |
|
NCBI Accession
|
NP_808889.1
|
|
Location
|
361-1137 |
|
Gene Name
|
BV1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGTATTCTGTATACAGACGTGGGTATAAGACGCCGTATAGGAGTCCGTATGGCTCGCGTGTAACACCATATGTGAATCGTAAGACCGCTGTGAAACAGACGGCGAAATCTCGTGTATCGCGAAAGTTGGCGTATGAATCGCCAAAAGGTCTATATACGCGACGCTCATTGGAGGATATCCATAATGGGGCTTCCTTGAAGTTGCCTCAACAGGGGGATTATACGTCCTACGTGACACTCCCATGTCGAGGCATCGATGGTAATGGGGGTAGGTCTGTTGATCATATAAAATTATTAAGCTTGAGGGTTTCTGGGACCGTCAACATCAGTCAATCCGGTGGTGATGACAATATGGGAGAGAGAACGACCATGAGGGGTATTTTTTTCATGGTTTGTTTTGTTGATAAGAAACCTTTCGTTCCAGAGGGGGTCAGCATATTGCCGACGTTCAATGAGTTGTTTGGGGAATATGAATCCGTGTATGGCATGCCTAGGCTGAAGGAAAACGTCCGTCACCGTTATCGTGTTATTGGGACGTCGAAATTATATATAACGACCGATGAAGATCATATCCAGAAGCCTTTTAGTCTACGTCGAAGACTAAGTGGAGGGAAATATCCTATATGGTCGTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGTAACTATAAAAATATAAATAAGAACGCTATACTCGTTAGTTATGTGTGGGTTTCGCTATGTCGGACCACGTGTGATGTGTATTCGCAGTTTGTACTTAATTACGTCGGCTGA |
|
Protein Sequence
|
MYSVYRRGYKTPYRSPYGSRVTPYVNRKTAVKQTAKSRVSRKLAYESPKGLYTRRSLEDIHNGASLKLPQQGDYTSYVTLPCRGIDGNGGRSVDHIKLLSLRVSGTVNISQSGGDDNMGERTTMRGIFFMVCFVDKKPFVPEGVSILPTFNELFGEYESVYGMPRLKENVRHRYRVIGTSKLYITTDEDHIQKPFSLRRRLSGGKYPIWSSFKDVDNSSTGGNYKNINKNAILVSYVWVSLCRTTCDVYSQFVLNYVG |
|
NCBI Accession
|
NP_808890.1
|
|
Location
|
1269-2192 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGACCACCAATTCACCGTCACAGACAATAATTACATCAACAGCAAACGCACAGAGTACGCATTAACCAACGGTGCTGCACCAATCAATCTCCAATTTCCGAGCTCATTCGAGCAGGCGACCATGCGACTCAAAGGCCGATGTATGAAAATCGACCACATTATAATTGAATACCGCAACCAGGTCCCATTTAACGCAACTGGGTCGGTTATCGTAGAAATCAGAGACAATCGCGTCAGCCTTGAAGACGCAGCTCAGGCAGCATTCACTTTCCCCATAGCTTGCAACGTAGACCTCCACTACTTCTCTTCTACATATTTCTCGATTTCAGAACCCTCCCCTTGGAAAATCCTATACAGAGTCGAAGACTCAAACGTCATAGAAGGCGTGAAATTCGCATCCATCAAGGCCAAGCTCAGATTATCCTCGGCCAAACATTCCACGGACATACGTTTCAAACCCCCAACAATTAACATCTTATCCAAGGGATACACAAAAGACTGCATAGACTTCTGGTCCGTGGAAAAAGGAGAAACAAGACGGAGATTACTAAATCCAACTCCAACTGCTCATAGTCAACGACCCATAACCCACAGGCCCATCACCATCCTACCTGGAGAAACATGGGCCACAAAGTCTCAGATTGGGCTACCAAGCTCATCCGGCCCAGCAAGGCTGGAACACTTTCGTTCACAGTCCATGAGAATGGACCCATCGACAACACCAACAGACTTAGACAACGAGTCCACCGAATATCCTTACCAGAGACTACACAGATTAAACACACCAGAGTTAGACCCAGGAGACTCGGTATCACAGACCCAATCCGACTCCGTATCCAGAAAGGATCTCGAGACACTGCTTGAGAGTACCATTAACAGGTGCCTCATCAAGATCAAATCCGAAGCACCAAGGCCATTGTAA |
|
Protein Sequence
|
MDHQFTVTDNNYINSKRTEYALTNGAAPINLQFPSSFEQATMRLKGRCMKIDHIIIEYRNQVPFNATGSVIVEIRDNRVSLEDAAQAAFTFPIACNVDLHYFSSTYFSISEPSPWKILYRVEDSNVIEGVKFASIKAKLRLSSAKHSTDIRFKPPTINILSKGYTKDCIDFWSVEKGETRRRLLNPTPTAHSQRPITHRPITILPGETWATKSQIGLPSSSGPARLEHFRSQSMRMDPSTTPTDLDNESTEYPYQRLHRLNTPELDPGDSVSQTQSDSVSRKDLETLLESTINRCLIKIKSEAPRPL |