East African cassava mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000859785.1 |
| Isolate |
Uganda |
| Release date |
2015/2/13 |
| Submitter |
Pita,J.S., Fondong,V.N., Sangare,A., Otim-Nape,G.W., Ogwal,S., Fauquet,C.M., Beachy,R.N. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
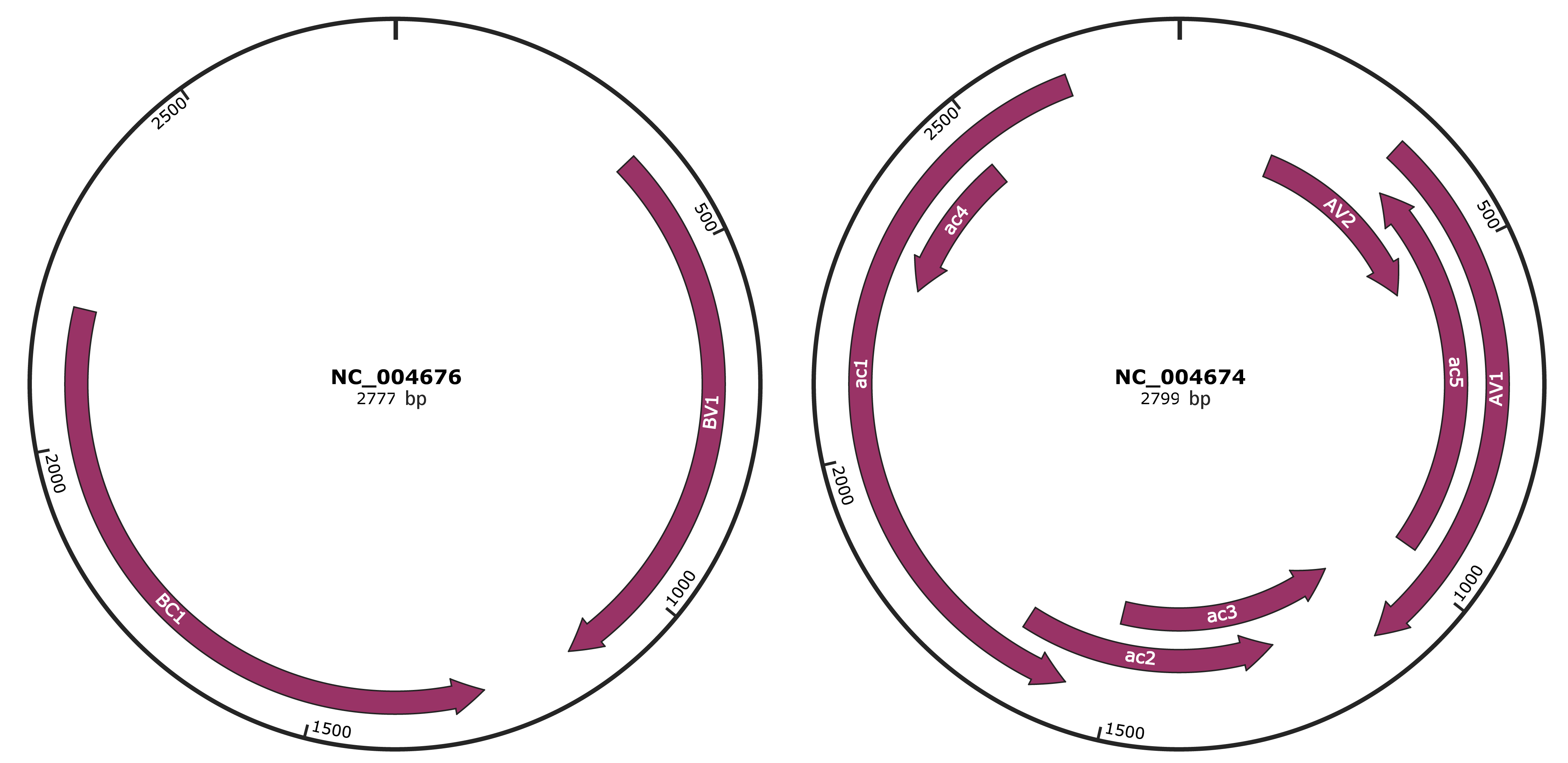
JBrowse
Genome
ACCGGATGGCCGCGCCCGAAAAAGCAGGGTGACCCCACAATGGCCCCCACGCACTAAGTAATGTCAGCCAATCATGTGCAAGACTGGAAGACGCGGTAGTTACGTATTGATGAGTAAGTGGTCCCGACGCACTAATGTTGACAGGCAATTGGATTGCTATGTGTGTATCATATTCATATAGGTGTGTTACTGGTTAATCTAAAGTTAGGTGATGGGGCCTATCATAAAAACGCAATACATAGGTACGTATGTACATATTGATTATATTTTTGTTTGCGGATATATGATCCGCCACGTGTATAATGGATATGGAATGTCCTATAAATATTTGGCATGTCTCCCGTCCGTTAATGCAAGATGTATTCTGTTTACAGGCGTGGGTATAAGACGCCGTATAGGAGTTCGTATGGCGCTCGTGTAACACCATATGTTTATCGTAAGACGGCTGGTAAACAGACGTCTAAATCTCGTGTACCGCGAAAGTTGGCGTATGAATCGCCAAAATGTCTATATACGCGACGCTCATTGGAGGATATCCATAATGGGGCTTCCTTAAAGTTGCCTCAACAGGGGGATTATACGTCCTACGTGACACTCCCATGTCGAGGTATCGATGGTAATGGGGGTAGGTCTGTTGATCATATAAAATTATTAAGCTTGAGGGTGTCTGGGACCGTCAATATCAGTCAATGCGGTGGTGATGATAATATGGGAGAGAGAACGACCATGAGGGGTATTTTTTTCATGGCTTGTCTTGTTGATAAGAAACCTTTCGTTCCAGAGGGGGTTAGTATATTGCCGACGTTTAATGAGTTGTTCGGGGAATATGAATCCGTGTATGGCATGCCTAGGTTGAAGGAAAACGTTCGTCACCGTTATCGCGTGATTGGGACGTCGAAATTATATATAACGACCGATGAAGAGCACATCCAGAAGCCATTTAGTCTACGTCGAAGACTAAGTGGAGGGAAATATCCTATGTGGTCGTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGGAACTATAAAAATATAAATAAGAACGCTATACTAGTTAGTTATGTGTGGGTATCGCTATGTCGGTCCACGTGTGATGTGTATTCCCAGTTTGTACTTAATTACGTCGGTTGATAATAAAACGAGATAAGTGTGTTGACATTAATTATGTTTGAACGAACGAAATATGAGATGAACATCAATGGAACGCACATATAGTGTTATTATGTAAGCGAATCAAATATCGTATATATCAAGTGTTTATTACAATTGCCTGGGTGCTTCGGATTTTATTTTGATGAGACACTTGTTTATGGTACTCTCAAGCAGTGTCTCGAGGTCCTTTCGGGATACTGAGTCGGATGGGGTCTGTGATACCGAGTCCCCTGGGTCCAATTCGGGTGTGTGTAATCTGTGTAGTGTCTGGTAAGGATATTCTGTGGAGTCGTTGTCGAAGTCCGTTGTGGTTGTCGATGGGCCCATTCTCATGGACTGTGAACGAAAGTGGTCCAGCCTTGCTGGGCCGGATGAGCTGGGTAGCCCAATTTGAGACTTCGTGGCCCATGTTTCTCCAGGGAGAATGGTGATGGGCCTGTGGGTTATGGGTCGTTGACTATTAGCATGTGGAGTTGGATTTAGTAATCTCCGTCGTGTTTCTCCTTTTTCCACGGACCAGAAGTCTATGCAATCCTTTGTGTAGCCCTTGGATAATATGTTAATTGTTGGGGGTTTGAAACGTATGTCCGTGGAATGTTTGGCCGATGATAATCGGAGCTTGGCCTTGATGGATGCGAATTTCACGCCTTCTATGACGTTTGAGTCTTCGACTCTGTACATGATTCTCCAAGGGGAGGGTTCTGAAAGCGAAAAATATGTAGACGAGAAGTAGTGGAGGTCTACGTTGCAAGCTATTGGGAAAGTGAATGCTGCTTGAGCAGCGTCTTCAAGGCTGACGCGATTGTCTCTGATTTCTACGATAACCGACCCAATTGCGTTAAATGGGACCTGGTTTCGGTATTCAATTATAATGTGGTCGATTTTCATACATCGGCCTTTGAGTCGCATGGTAGCCTGCTCGAATGAGCTCGGGAATTGGAGATTGATTGGTGCAGCATCGTTGGTTAATGCGTACTCTGTGCGTTTGCTGTTGATGTAATTCTTGTCTGTGACGGTGAATTGGTTGTCCATTCTATGAATGAAAAAAACAAGGGTTAGTAAACGGAGAGAAGAGATGTATAAAAGTCAGAGCAAGTTTATAAAATGTCTTGTATACATGGAAGCATATATGCATTGGGTAGCGATAATAACACACTAAAGCAGAACAAGGATCATATATGTATAATTGGCCGCGCAGCGGATTGGAAGTCAGACAAATCGGCGAACAAATAAAAAAGTCGAATGATGTTATGGGATGGAAACAACGTACGGAAGCACCTAGGAAGCAGTCGGGAGTGAATTCTTGTTAGAAGTGGAGAAAACAAAGAAATAAAAGTTAACGAAATAAAAGTATGACGGATTGGTAGAGAAAGGAAAGTGAGCAGATGATATGCGCCGTGTCGTTAAATGAGATGTTATTGGGTGTTTATATAGGCGTTAATAAGCGAGACGTGGTAGAGAGAGAAAGAAGAGAGAGGCGAGAGCAATCGGGGGACACTCAAAGTCTGTAGCAATCGGGGGAAAGGGGGGCAATTTATATGATGTCCCCTAAATGGCATTTATGTAATATCCTCAATGAATGTGAAAGGCAAACGTGGAAAGGCGGCCATCCGTATAATATT
ACCGGATGGCCGCGCCCGAAAAAGCAGGTGGACCCCACAATGACCGCGCCCGTGAAAGAAAGTGGTCCCTGCGCACTTGTTTTGGTCGGCCAGTCATATTCACGCGTGAAATTCTAGATATTTGTTGTTTGTCTTTATAGACTTCGTCGCGAAGTAGTAGAGCGCGTTAACATGTGGGATCCATTGGTGAACGATTTTCCCGAAACCGTTCACGGTTTCCGTTCTATGCTTGCTGTTAAATACCTGTTACATTTGGAACAGGAATACGATCGCGGTACTGTCGGGGCTGAGTATATACGGGATCTAATAGGGGTTCTACGGTGTAAGAATTATGTCGAAGCGACCAGGAGATATAATAATCTCAACACCCGTATCCAAGGTGCGGAGGAGGCTGAACTTCGACAGCCCATACACGAACCGTGTTGTTGCCCCCACTGTCCGCGTCACCAGAAGCAAAATATGGGCCAACAGGCCCATGTATCGGAAACCCAAGATGTACAGAATGTATCGAAGCCCAGATGTCCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCTTTTGAGCAGAGGGATGATGTGAAGCACCTTGGTATCTGTAAGGTGATTAGTGATGTGACGCGTGGGCCTGGGCTGACACACAGGGTCGGAAAGAGGTTTTGTATCAAGTCCATTTACATTCTTGGTAAGATCTGGATGGATGAAAATATTAAGAAGCAGAATCACACTAATAATGTGATGTTTTACCTGCTTAGGGATAGAAGGCCGTATGGCAATGCGCCCCAAGACTTTGGGCAGATATTTAACATGTTTGATAATGAGCCCAGTACTGCAACAATTAAGAACGATTTGAGGGATAGGTTTCAGGTGTTGAGGAAATTTCATGCCACTGTTGTTGGTGGTCCATCTGGCATGAAGGAGCAGGCGTTGGTGAAAAGGTTTTACAAGCTGAATCATCACGTGACATATAATCATCAGGAGGCAGGGAAGTATGAGAATCACACAGAGAATGCGTTGTTATTGTATATGGCATGTACACATGCCTCGAATCCTGTGTATGCTACGCTGAAAATACGCATCTATTTTTATGATGCAGTGACAAATTAATAAAGGTTGAATTTTATTGCATGTTGCTCCGTAACTTGGAGTGTGTTTAGTAATACATCGTACACAACATGATCAACAGCTTGAAGGACAGTGTTAATGGAAATAACGCCTATCATATCTAAATACTTGAGCACTTGATATCTAAATACTCTTAAGAAACGACCAGTCTGAGGCCGTAAGGTCGTCCAGACCTTGAAGTTGAGAAAACACTTGTGAATCCCCAATGCCTTCCGAAGGTTGTGGTTGAACCGTATCTGGAGTGTGATGATGTCGTGGTTCATGTTCCCTGGCCTCTTGTCGTGGTCGGTGATTTCGAAATAGAGGGGATTTGTTATGTCCCAGGTAAAAACGCCATTCCTTGCTTGAGGCGCAGTGATGAGTTCCCCTGTGCGAGAATCCATGGTTGATGCAGTCGATATGGAGATAGAACGAGCAGCCGCATTCGAGGTCTACCCGCCTACGTCTGACGGCCCTGGTCTTCGCTGTGCGGTGTTGGACTTTGATGGGCACTTGAGAACAATGGCTCGTGGAGGGCGATGAAGGTGGCATTCTTTAAAGCCCAGGCTTTAAGGGATTGGTTCTTTTCCTCGTCCAGAAACTCTTTATATGATGATGTTGGTCCTGGATTGCAGAGGAAGATAGTGGGAATGCCGCCTTTAATTTGAATTGGCTTCCCGTATTTTGTATTGCTTTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTGAAGTGTTTGAGGTAGTGGGGGTCGACGTCATCAATGACGTTGTACCATGCGTCGTTTGAATATACCTTGGGAGACAGATCCAGGTGTCCACAAAGATAATTATGGGGTCCCAGTGAACGAGCCCACATTGTTTTGCCGGTTCGGCTATCACCTTCTAGAACAATACTGATCGGTCTCCATGGCCGCGCAGCGGGACTGCATATATTTTCGGATACCCATACCTCTATGTCTTCTGGGACTTGTGTAAAAGATGATGATAAGAACGGACTAACGTAAGTTTGTGGCGGAGCCTGGAAGATTCTATCTGCGTTAGCAGATATGTTATGGAACTGTAAAAAAAAGGACTTTGGATCTTTTTCTTTAATAATTTGAAGAGCCTCGGATTTAGACGAAGCATTCAACGCGTCTGCATATACCTGAGCTAAATGTTGGCCCTCCCCCCTTGCACTTCTGGCATCGACTTGGAAAAGTCCAGCGTCAAGAAATTCCCCTCCCTTTTCAATGTAAGCTTTGACATCGGACGATGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGATCGGGATGGGGAAATGAGATCGAAGAATCTCGGGTTGGTACATTGGAACTTGCCTTCGAATTGGATGAGAACATGGAGATGAGGCACCCCATCCTGATGTAGTTCTCTGCAAACCCTAATGAATTTGATAATCGTCGGGTACGAAAGGGCTTGTAATTGGGAAAGGGCCTCTTCTTTTGTTAATGAGCATCGGGGATAGGTTATGAAATAATTTTTGGCATTAATTTGAAAACGACCGGCTCTTGGCATATTGGCTGTCGTTTTGGATCGGGGGACACTCAAAACTCCAGGGGAACGGTGGAATGGGGGGCATTATATATGATGTCCCCCAATGGCATATGTGTAAATAGGTAGACTTCCATTCAAAATTTGAATTCCGAATATTGGCGGCCATCCGATTAATATT
Gene Information
|
NCBI Accession
|
NP_817128.1
|
|
Location
|
358-1134 |
|
Gene Name
|
BV1 |
|
Protein Name
|
BV1 protein |
|
Coding Region
|
ATGTATTCTGTTTACAGGCGTGGGTATAAGACGCCGTATAGGAGTTCGTATGGCGCTCGTGTAACACCATATGTTTATCGTAAGACGGCTGGTAAACAGACGTCTAAATCTCGTGTACCGCGAAAGTTGGCGTATGAATCGCCAAAATGTCTATATACGCGACGCTCATTGGAGGATATCCATAATGGGGCTTCCTTAAAGTTGCCTCAACAGGGGGATTATACGTCCTACGTGACACTCCCATGTCGAGGTATCGATGGTAATGGGGGTAGGTCTGTTGATCATATAAAATTATTAAGCTTGAGGGTGTCTGGGACCGTCAATATCAGTCAATGCGGTGGTGATGATAATATGGGAGAGAGAACGACCATGAGGGGTATTTTTTTCATGGCTTGTCTTGTTGATAAGAAACCTTTCGTTCCAGAGGGGGTTAGTATATTGCCGACGTTTAATGAGTTGTTCGGGGAATATGAATCCGTGTATGGCATGCCTAGGTTGAAGGAAAACGTTCGTCACCGTTATCGCGTGATTGGGACGTCGAAATTATATATAACGACCGATGAAGAGCACATCCAGAAGCCATTTAGTCTACGTCGAAGACTAAGTGGAGGGAAATATCCTATGTGGTCGTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGGAACTATAAAAATATAAATAAGAACGCTATACTAGTTAGTTATGTGTGGGTATCGCTATGTCGGTCCACGTGTGATGTGTATTCCCAGTTTGTACTTAATTACGTCGGTTGA |
|
Protein Sequence
|
MYSVYRRGYKTPYRSSYGARVTPYVYRKTAGKQTSKSRVPRKLAYESPKCLYTRRSLEDIHNGASLKLPQQGDYTSYVTLPCRGIDGNGGRSVDHIKLLSLRVSGTVNISQCGGDDNMGERTTMRGIFFMACLVDKKPFVPEGVSILPTFNELFGEYESVYGMPRLKENVRHRYRVIGTSKLYITTDEEHIQKPFSLRRRLSGGKYPMWSSFKDVDNSSTGGNYKNINKNAILVSYVWVSLCRSTCDVYSQFVLNYVG |
|
NCBI Accession
|
NP_817129.1
|
|
Location
|
1264-2187 |
|
Gene Name
|
BC1 |
|
Protein Name
|
BC1 protein |
|
Coding Region
|
ATGGACAACCAATTCACCGTCACAGACAAGAATTACATCAACAGCAAACGCACAGAGTACGCATTAACCAACGATGCTGCACCAATCAATCTCCAATTCCCGAGCTCATTCGAGCAGGCTACCATGCGACTCAAAGGCCGATGTATGAAAATCGACCACATTATAATTGAATACCGAAACCAGGTCCCATTTAACGCAATTGGGTCGGTTATCGTAGAAATCAGAGACAATCGCGTCAGCCTTGAAGACGCTGCTCAAGCAGCATTCACTTTCCCAATAGCTTGCAACGTAGACCTCCACTACTTCTCGTCTACATATTTTTCGCTTTCAGAACCCTCCCCTTGGAGAATCATGTACAGAGTCGAAGACTCAAACGTCATAGAAGGCGTGAAATTCGCATCCATCAAGGCCAAGCTCCGATTATCATCGGCCAAACATTCCACGGACATACGTTTCAAACCCCCAACAATTAACATATTATCCAAGGGCTACACAAAGGATTGCATAGACTTCTGGTCCGTGGAAAAAGGAGAAACACGACGGAGATTACTAAATCCAACTCCACATGCTAATAGTCAACGACCCATAACCCACAGGCCCATCACCATTCTCCCTGGAGAAACATGGGCCACGAAGTCTCAAATTGGGCTACCCAGCTCATCCGGCCCAGCAAGGCTGGACCACTTTCGTTCACAGTCCATGAGAATGGGCCCATCGACAACCACAACGGACTTCGACAACGACTCCACAGAATATCCTTACCAGACACTACACAGATTACACACACCCGAATTGGACCCAGGGGACTCGGTATCACAGACCCCATCCGACTCAGTATCCCGAAAGGACCTCGAGACACTGCTTGAGAGTACCATAAACAAGTGTCTCATCAAAATAAAATCCGAAGCACCCAGGCAATTGTAA |
|
Protein Sequence
|
MDNQFTVTDKNYINSKRTEYALTNDAAPINLQFPSSFEQATMRLKGRCMKIDHIIIEYRNQVPFNAIGSVIVEIRDNRVSLEDAAQAAFTFPIACNVDLHYFSSTYFSLSEPSPWRIMYRVEDSNVIEGVKFASIKAKLRLSSAKHSTDIRFKPPTINILSKGYTKDCIDFWSVEKGETRRRLLNPTPHANSQRPITHRPITILPGETWATKSQIGLPSSSGPARLDHFRSQSMRMGPSTTTTDFDNDSTEYPYQTLHRLHTPELDPGDSVSQTPSDSVSRKDLETLLESTINKCLIKIKSEAPRQL |
|
NCBI Accession
|
NP_817107.1
|
|
Location
|
172-528 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCATTGGTGAACGATTTTCCCGAAACCGTTCACGGTTTCCGTTCTATGCTTGCTGTTAAATACCTGTTACATTTGGAACAGGAATACGATCGCGGTACTGTCGGGGCTGAGTATATACGGGATCTAATAGGGGTTCTACGGTGTAAGAATTATGTCGAAGCGACCAGGAGATATAATAATCTCAACACCCGTATCCAAGGTGCGGAGGAGGCTGAACTTCGACAGCCCATACACGAACCGTGTTGTTGCCCCCACTGTCCGCGTCACCAGAAGCAAAATATGGGCCAACAGGCCCATGTATCGGAAACCCAAGATGTACAGAATGTATCGAAGCCCAGATGTCCCTAA |
|
Protein Sequence
|
MWDPLVNDFPETVHGFRSMLAVKYLLHLEQEYDRGTVGAEYIRDLIGVLRCKNYVEATRRYNNLNTRIQGAEEAELRQPIHEPCCCPHCPRHQKQNMGQQAHVSETQDVQNVSKPRCP |
|
NCBI Accession
|
NP_817108.1
|
|
Location
|
332-1105 |
|
Gene Name
|
AV1 |
|
Protein Name
|
AV1 protein |
|
Coding Region
|
ATGTCGAAGCGACCAGGAGATATAATAATCTCAACACCCGTATCCAAGGTGCGGAGGAGGCTGAACTTCGACAGCCCATACACGAACCGTGTTGTTGCCCCCACTGTCCGCGTCACCAGAAGCAAAATATGGGCCAACAGGCCCATGTATCGGAAACCCAAGATGTACAGAATGTATCGAAGCCCAGATGTCCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCTTTTGAGCAGAGGGATGATGTGAAGCACCTTGGTATCTGTAAGGTGATTAGTGATGTGACGCGTGGGCCTGGGCTGACACACAGGGTCGGAAAGAGGTTTTGTATCAAGTCCATTTACATTCTTGGTAAGATCTGGATGGATGAAAATATTAAGAAGCAGAATCACACTAATAATGTGATGTTTTACCTGCTTAGGGATAGAAGGCCGTATGGCAATGCGCCCCAAGACTTTGGGCAGATATTTAACATGTTTGATAATGAGCCCAGTACTGCAACAATTAAGAACGATTTGAGGGATAGGTTTCAGGTGTTGAGGAAATTTCATGCCACTGTTGTTGGTGGTCCATCTGGCATGAAGGAGCAGGCGTTGGTGAAAAGGTTTTACAAGCTGAATCATCACGTGACATATAATCATCAGGAGGCAGGGAAGTATGAGAATCACACAGAGAATGCGTTGTTATTGTATATGGCATGTACACATGCCTCGAATCCTGTGTATGCTACGCTGAAAATACGCATCTATTTTTATGATGCAGTGACAAATTAA |
|
Protein Sequence
|
MSKRPGDIIISTPVSKVRRRLNFDSPYTNRVVAPTVRVTRSKIWANRPMYRKPKMYRMYRSPDVPKGCEGPCKVQSFEQRDDVKHLGICKVISDVTRGPGLTHRVGKRFCIKSIYILGKIWMDENIKKQNHTNNVMFYLLRDRRPYGNAPQDFGQIFNMFDNEPSTATIKNDLRDRFQVLRKFHATVVGGPSGMKEQALVKRFYKLNHHVTYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
|
NCBI Accession
|
NP_817109.1
|
|
Location
|
362-973 |
|
Gene Name
|
ac5 |
|
Protein Name
|
AC5 protein |
|
Coding Region
|
ATGATTATATGTCACGTGATGATTCAGCTTGTAAAACCTTTTCACCAACGCCTGCTCCTTCATGCCAGATGGACCACCAACAACAGTGGCATGAAATTTCCTCAACACCTGAAACCTATCCCTCAAATCGTTCTTAATTGTTGCAGTACTGGGCTCATTATCAAACATGTTAAATATCTGCCCAAAGTCTTGGGGCGCATTGCCATACGGCCTTCTATCCCTAAGCAGGTAAAACATCACATTATTAGTGTGATTCTGCTTCTTAATATTTTCATCCATCCAGATCTTACCAAGAATGTAAATGGACTTGATACAAAACCTCTTTCCGACCCTGTGTGTCAGCCCAGGCCCACGCGTCACATCACTAATCACCTTACAGATACCAAGGTGCTTCACATCATCCCTCTGCTCAAAAGACTGGACCTTACATGGGCCTTCACAGCCCTTAGGGACATCTGGGCTTCGATACATTCTGTACATCTTGGGTTTCCGATACATGGGCCTGTTGGCCCATATTTTGCTTCTGGTGACGCGGACAGTGGGGGCAACAACACGGTTCGTGTATGGGCTGTCGAAGTTCAGCCTCCTCCGCACCTTGGATACGGGTGTTGA |
|
Protein Sequence
|
MIICHVMIQLVKPFHQRLLLHARWTTNNSGMKFPQHLKPIPQIVLNCCSTGLIIKHVKYLPKVLGRIAIRPSIPKQVKHHIISVILLLNIFIHPDLTKNVNGLDTKPLSDPVCQPRPTRHITNHLTDTKVLHIIPLLKRLDLTWAFTALRDIWASIHSVHLGFPIHGPVGPYFASGDADSGGNNTVRVWAVEVQPPPHLGYGC |
|
NCBI Accession
|
NP_817110.1
|
|
Location
|
1102-1506 |
|
Gene Name
|
ac3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAGGAATGGCGTTTTTACCTGGGACATAACAAATCCCCTCTATTTCGAAATCACCGACCACGACAAGAGGCCAGGGAACATGAACCACGACATCATCACACTCCAGATACGGTTCAACCACAACCTTCGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAAGGTCTGGACGACCTTACGGCCTCAGACTGGTCGTTTCTTAAGAGTATTTAGATATCAAGTGCTCAAGTATTTAGATATGATAGGCGTTATTTCCATTAACACTGTCCTTCAAGCTGTTGATCATGTTGTGTACGATGTATTACTAAACACACTCCAAGTTACGGAGCAACATGCAATAAAATTCAACCTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQARNGVFTWDITNPLYFEITDHDKRPGNMNHDIITLQIRFNHNLRKALGIHKCFLNFKVWTTLRPQTGRFLRVFRYQVLKYLDMIGVISINTVLQAVDHVVYDVLLNTLQVTEQHAIKFNLY |
|
NCBI Accession
|
NP_817111.1
|
|
Location
|
1247-1654 |
|
Gene Name
|
ac2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCCACCTTCATCGCCCTCCACGAGCCATTGTTCTCAAGTGCCCATCAAAGTCCAACACCGCACAGCGAAGACCAGGGCCGTCAGACGTAGGCGGGTAGACCTCGAATGCGGCTGCTCGTTCTATCTCCATATCGACTGCATCAACCATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAGGAATGGCGTTTTTACCTGGGACATAACAAATCCCCTCTATTTCGAAATCACCGACCACGACAAGAGGCCAGGGAACATGAACCACGACATCATCACACTCCAGATACGGTTCAACCACAACCTTCGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAAGGTCTGGACGACCTTACGGCCTCAGACTGGTCGTTTCTTAAGAGTATTTAG |
|
Protein Sequence
|
MPPSSPSTSHCSQVPIKVQHRTAKTRAVRRRRVDLECGCSFYLHIDCINHGFSHRGTHHCASSKEWRFYLGHNKSPLFRNHRPRQEAREHEPRHHHTPDTVQPQPSEGIGDSQVFSQLQGLDDLTASDWSFLKSI |
|
NCBI Accession
|
NP_817112.1
|
|
Location
|
1563-2642 |
|
Gene Name
|
ac1 |
|
Protein Name
|
AC1 protein |
|
Coding Region
|
ATGCCAAGAGCCGGTCGTTTTCAAATTAATGCCAAAAATTATTTCATAACCTATCCCCGATGCTCATTAACAAAAGAAGAGGCCCTTTCCCAATTACAAGCCCTTTCGTACCCGACGATTATCAAATTCATTAGGGTTTGCAGAGAACTACATCAGGATGGGGTGCCTCATCTCCATGTTCTCATCCAATTCGAAGGCAAGTTCCAATGTACCAACCCGAGATTCTTCGATCTCATTTCCCCATCCCGATCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGATGTCAAAGCTTACATTGAAAAGGGAGGGGAATTTCTTGACGCTGGACTTTTCCAAGTCGATGCCAGAAGTGCAAGGGGGGAGGGCCAACATTTAGCTCAGGTATATGCAGACGCGTTGAATGCTTCGTCTAAATCCGAGGCTCTTCAAATTATTAAAGAAAAAGATCCAAAGTCCTTTTTTTTACAGTTCCATAACATATCTGCTAACGCAGATAGAATCTTCCAGGCTCCGCCACAAACTTACGTTAGTCCGTTCTTATCATCATCTTTTACACAAGTCCCAGAAGACATAGAGGTATGGGTATCCGAAAATATATGCAGTCCCGCTGCGCGGCCATGGAGACCGATCAGTATTGTTCTAGAAGGTGATAGCCGAACCGGCAAAACAATGTGGGCTCGTTCACTGGGACCCCATAATTATCTTTGTGGACACCTGGATCTGTCTCCCAAGGTATATTCAAACGACGCATGGTACAACGTCATTGATGACGTCGACCCCCACTACCTCAAACACTTCAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAATACAAAATACGGGAAGCCAATTCAAATTAAAGGCGGCATTCCCACTATCTTCCTCTGCAATCCAGGACCAACATCATCATATAAAGAGTTTCTGGACGAGGAAAAGAACCAATCCCTTAAAGCCTGGGCTTTAAAGAATGCCACCTTCATCGCCCTCCACGAGCCATTGTTCTCAAGTGCCCATCAAAGTCCAACACCGCACAGCGAAGACCAGGGCCGTCAGACGTAG |
|
Protein Sequence
|
MPRAGRFQINAKNYFITYPRCSLTKEEALSQLQALSYPTIIKFIRVCRELHQDGVPHLHVLIQFEGKFQCTNPRFFDLISPSRSTHFHPNIQGAKSSSDVKAYIEKGGEFLDAGLFQVDARSARGEGQHLAQVYADALNASSKSEALQIIKEKDPKSFFLQFHNISANADRIFQAPPQTYVSPFLSSSFTQVPEDIEVWVSENICSPAARPWRPISIVLEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEFLDEEKNQSLKAWALKNATFIALHEPLFSSAHQSPTPHSEDQGRQT |
|
NCBI Accession
|
NP_817113.1
|
|
Location
|
2252-2485 |
|
Gene Name
|
ac4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGTGCCTCATCTCCATGTTCTCATCCAATTCGAAGGCAAGTTCCAATGTACCAACCCGAGATTCTTCGATCTCATTTCCCCATCCCGATCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGATGTCAAAGCTTACATTGAAAAGGGAGGGGAATTTCTTGACGCTGGACTTTTCCAAGTCGATGCCAGAAGTGCAAGGGGGGAGGGCCAACATTTAG |
|
Protein Sequence
|
MGCLISMFSSNSKASSNVPTRDSSISFPHPDQHISIRTFRELNHRPMSKLTLKREGNFLTLDFSKSMPEVQGGRANI |