East African cassava mosaic Malawi virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000912855.1 |
| Isolate |
Malawi |
| Release date |
2015/2/22 |
| Submitter |
Nawaz-ul-Rehman,M.S., Fauquet,C.M. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
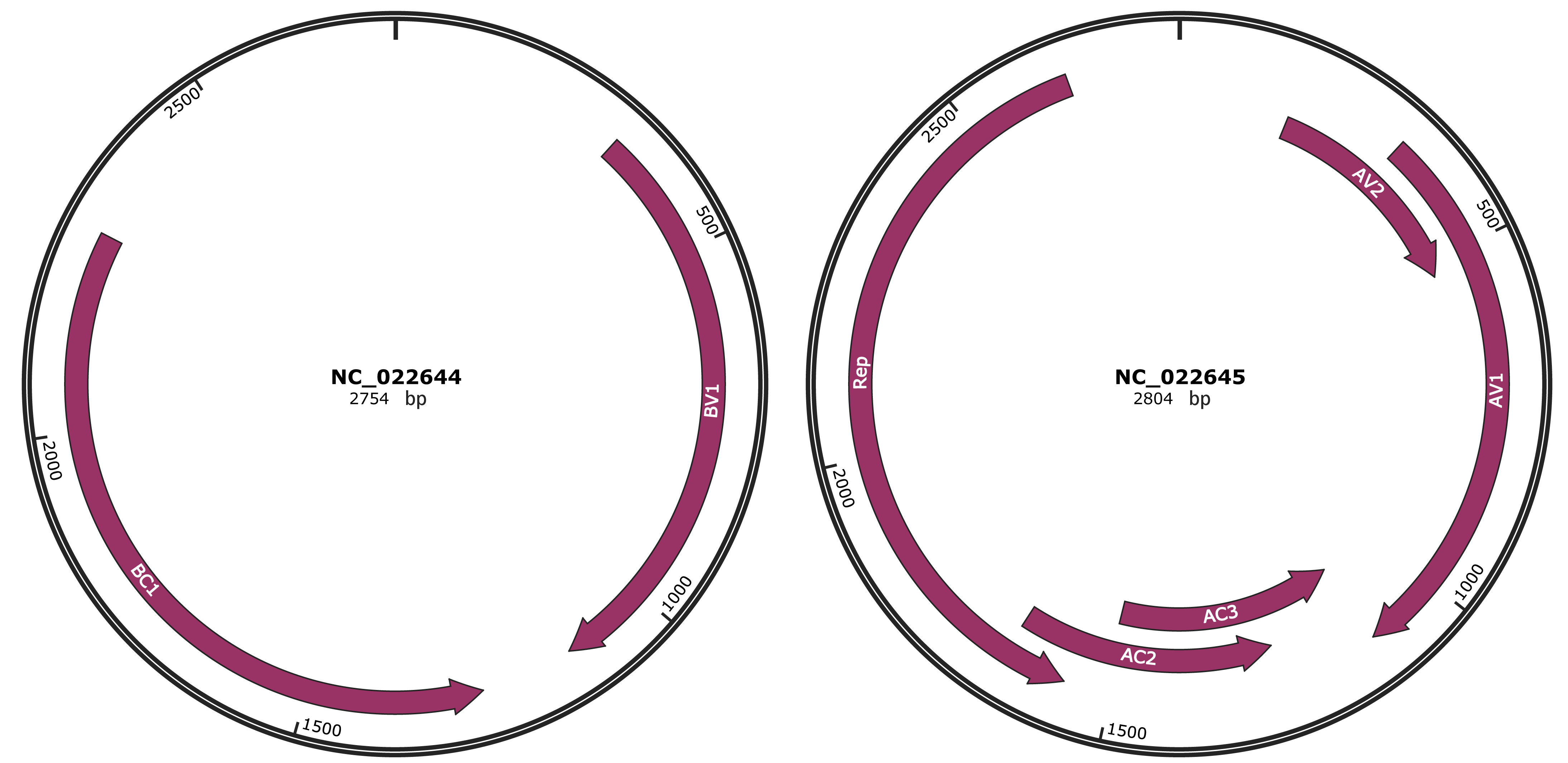
JBrowse
Genome
ACCGGATGGCCGCGCCCGAAAAAAGCAGATGGACCCCACAATAGCCCCCACGCACTACTCGTCAGCCAACCATGTGCAAGACTGGGAGACTCGGTATTTACGCATGGAGGATTAAGTGGGCCCTACGTACTAAGTTTGACAGGCAATTTTATTGCGATGTGTGTATCATATTTTATAAGTCTGTTACGGGCCAATCTAAAGTTATGTTATGGGGTCTATCATAAAAAAGCAAAATATAGGTTCCTATTTACATATGGATTATAGTTTTATGTGCGCATATATGATCCGCCACGTGTTATTAATGTGTCCTATAAATATGGTACATGTCTCCCGTTCGTCAATGCAAGATGTATTCGGTATACAGACGTGGGTATAAGACGCCGTATAGGAGTCCGTATGGCGCTCGTGGAACACCATATGTGAATCGTAAGACCTCTGGTAAACAGACGGCTAAATCTCGTGTATCGCGAAAGTTGGCGTATGAATCGCCAAAAGGTCTATATACGCGACGCTCATTGGAGGATATCCATAATGGGGCTGCCTTGAAGTTGCCGCAACAGGGGGATTATACGTCCTACGTGACACTCCCATGTCGAGGCATCGATGGTAATGGGGGTAGGTCTGTGGATCATATAAAATTATTAAATTTGAGGGTTTCTGGGACCGTCAACGTCAGTCAATCCGGTGGTGATGACAATATGGGAGAGAGAACGACCATGAGGGGTATTTTTTTCATGGCGTGTCTTGTTGATAAGAAACCCTTCGTTCCAGATGGGGTCAGCATATTGCCGACGTTTAATGAGTTGTTCGGGGAATATGAATCCGTTTATGGCATGCCTAGGTTGAAGGAAAACGTCCGTCACCGTTATCGCGTTATTGGGACGTCGAAATTATATATAACGACCGATGAAGATCACATCCAGAAGCCTTTTAGTCTACGTCGAAGACTAAGTGGAGGGAAATATCCTATATGGTCGTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGTAACTATAAAAATATAAATAAGAACGCTATACTCGTTAGTTATGTGTGGGTGTCGCTAAGTCGGACCACGTGTGATGTGTATTCGCAGTTTGTACTTAATTACGTCGGCTGATAATAAAACTATATAAGTGTTTGATGGACATTAATTATGTGGGAACGAACGAAAAAGAGATGAACATGAATGGTAAGCATATAGAGTTTTATTATGTTCCGAAGCAAATATGGTACATATAAATGGTTCATTACAATGGCCTTGGTGCTTCGGATTTGATCTTGATGAGGCACTTGTTGATGGTACTCTCAAGCAGTGTCTCGAGGTCCTTTCTGGATACTGAGTCGGATTGGGCCTGTGATACCGAGTCCCCTGGGTCTAACTCTGGTGTGTGTAATCTGTGTAGTCTCTGGTAAGGATAGTCTGTGGAGTCGTTGTCTAAGTCTGTTGGTATTGTCGATGGGTCCATTCTCATGGACTGTGAACGAAAGTGTTCCAGCCTTGTTGGGCCTGATGAGCTGGGTAGCCCAATCTGAGACTTAGTTGCCCATGTTTCTCCAGGTAGGATGGTGATGGGCCTGTGGGCTATGGGTCGTGGACTATGAGCATGTGGAGTTGGATTTAGTAATCTCCGTCTTGTTTCTCCTTTTTCCACAGACCAAAAGTCTATGCAGTCTTTCGTGTATCCCTTGGATAAGATGTTAATTGTTGGGGGTTTGAAACGTATGTCTGTGGAATGTTTGGCCGATGATAATCGGAGCTTGGCTTTGATGGATGCGAATTTCACGCCTTCTACGACGTTGGAGTCCTCGACTCGGTACATTATTTTCCAAGGGGAGGGGTCCGAAATCGAAAAATATGTAGAAGAGAAGTAGTGGAGGTCGACGTTGCAAGCTATTGGGAAAGTGAATGCTGCTTGAGCTGCGTCTTCAAGGCTGACGCGATTGTCTCGGATTTCTACGATAACCGACCCAGTTGCGTTAAATGGGACCTGGTTGCGGTATTCAATTATAATGTGGTCGATTTTCATACATCGGCCTTTGAGTCGCATGGTCGCCTGCTCGAATGAGCTCGGAAATTGGAGATTGATTGGTGCAGCATCGTTGGTTAAGGCGTACTCGGTGCGTTTGCTGTTTATGTAATTATTGTCTGTGACGGTGAATTGGTTGTCCATTCTAGGAATGAAAAAAACAAGGGTTAGGAAACGGAGAGAAGAGATGTATAAAAGGCAGAACAAGGTTGATAAAATGTCTTGTAGACATGGAAGCATATATGCAGTGAATATATATAAGAACACACGAAAATAGAGCAAGGATCATATATGTGTAACCGGCCGCGCAGCGGATTGGAATTCAGAGAAATCGACGAACAAAGAATAAAGTCAAAAGGGGTTATGTGATTTAAATCACTTACAGAATCGCCGATGAAGCAGTTAGGAGTGAATTCCTGTTCCAATTCGGAGAAAATAAAGAAATAAAAGTGGAACGTAGTGCGATAAAAATGAAAGGGAGCAGATGTCACGCGAGGTGTCGTTAAATGATATGCTAGTATGTGTTTATATAGGCGTTAATAAGCGACACGTGGTAGAGAGAGAAAGAAGAGAGAGGCGAGAGCATTCGGGGGACACTCAAAGTCTATAGCAATCGGGGGAAAGGGGGGCAATTTATATGATGCCCCCCAAATGGCATTTATGTAATATCCTCATTGAATTTGAAATTCAAACGTGGAAAGCGGCCATCCGTATAATATT
ACCGGATGGCCGCGCCCGACAAAGTAAGTGGACCCCATTGGACGGCCGCGTCCGTAAAAGAAAATGGTCCCCGCGCACGTGTTGCTGTTAGCCAGTCATATTCACGCGTGAAAGCCTAGATATTTGATTAATGTCGTTATATACTTCGTCGCGAAGTAGTGGAGCGCGTCAACATGTGGGATCCATTGTTGAATGAGTTCCCCGAGTCTGTGCACGGTTTTCGCTGTATGCTTGCTATTAAATATTTGCAGGCTTTGGAGGAAACCTACGAGCCCAATACTTTGGGCCACGATCTAGTCCGTGATCTCATCTGTGTTATCCGAGCCCGTGATTATGTCGAAGCGACCCGCCGATATAATCATTTCCACTCCCGCCTCGAAGTGCGTCGAAGCTGCACTTCGACAGCCCGTTCAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCATACCAACAAGCGACGATCATGGACGTTCCGGCCCATGTATCGAAAGCCCAGAATGTACAGAATGTACAGAAGTCCTGATGTTCCTCGAGGATGTGAAGGCCCATGTAAGGTACAGTCCTATGAACAGAGAGACGATGTTAAGCACACCGGTGCTGTGCGTTGTGTTAGTGATGTTACTCGTGGTTCGGGTATTACTCATAGGGTAGGGAAGAGATTTTGTGTTAAGTCAATATATGTGTTAGGAAAGATCTGGATGGATGAAAACATCAAGAAGCAAAACCATACTAACCAGGTGATGTTCTTCTTAGTCCGTGACAGAAGGCCTTATGGCACAAGCCCCATGGACTTTGGACAGGTTTTTAATATGTTTGATAATGAGCCCAGTACAGCTACTATTAAGAATGATTTGCGAGATAGGTTCCAAGTGTTGCGGAAATTCCATGCCACTGTGGTAGGTGGTCCCTCAGGCATGAAGGAGCAGGCGTTGATTAAGAGGTTTTTTAAGGTGAATAATCATGTTGTGTATAATCACCAGGAGGCAGCGAAGTATGAGAATCATACAGAAAATGCGTTGTTGTTGTATATGGCATGTACGCATGCCTCTAATCCAGTGTATGCTACGCTTAAAATACGCATCTATTTTTATGATGCAGTAACAAATTAATAAAGGTTGAATTTTATTTCATGTTGCTCCGTAACTTGAGTGTGTGGCCAGTAATACATTGTACAGGACATGATCACAGCTCTAAGTACAGTGTTAATGGAAATAACTCCTATCATATTTAAATATTTGAGCACTTGATATCTAAATACTTTTAAGAAAAGACCAGTCGGAGGCTGTAAGGTCGTCCAGACCTTGAAGTTGAGAAAACACTTGTGAATCCCCAATGCCTTCCTGATGTTGTGGTTGAACCGTATCTGGAGTGTGATGATATCGTGGTGCATGTTCCCTGGTCTCTTGTCGTGGTTGGTGATTGCGAAATAGAGGGGATTTGTTATTTCCCAAGTAAAAACGCCATTCTTTGCTTGAGGCGCAGTGATGAGTTCCCCTGTGCGAGAATCCATGATTGATGCAGTCGATATGGAGATAGAACGAGCAGCCGCATTCGAGGTCTACCCTCCTACGTCTGAGTGCCCTGTTCTTCACGGTGCGGTGTTGGACTTTGATAGGCACTTGAGAACAATGGCTCGTGGAGGGTGATGAAGGTGGCATTCTTTAAAGCCCAGGCTTTAAGGGATTGGTTCTTTTCCTCTTCCAGAAACTCTTTATATGATGATGTTGGTCCTGGATTGCAGAGGAAGATAGTGGGAATGCCGCCTTTAATTTGAATCGGCTTCCCGTACTTTGTATTGCTTTGCCAGTCCCTTTGGGCCCCCATAAATTCTTTGAAGTGCTTGAGGTAGTGTGGGTCGACGTCATCAATGACGTTGTACCAGGCGTCGTTGCTGTAGACCTTTGGACTAAGATCCAAATGTCCACACAAGTAGTTGTGTGGTCCCAGAGATCGGGCCCACATCGTCTTCCCTGTCCTACTATCGCCTTCTAGAACAATACTGATCGGTCTCCATGGCCGCGCAGCGGGACTGCATATATTTTCGGATACCCATATTTCTATTTCGTCTGGGACGTGTGTAAATGAGGATGATAAAAACGGACTTACATAAGTTTGTGGCGGGAGCTGGAAGATTCTATCTGCGTTAGCAGATATGTTATGGAACTGTAAAAAAAAAGACTTCGGATCTTTTTCTTTAATAATTTGAAGAGCTTCTGATTTAGAAGAAGCATTCAACGCTTCTGCATATACCTGAGCTAAATGCTGGCCCTCACCCCTTGCACTTCTGGCATCGACTTGGAAAACTCCATCGTCAAGAAATTCCCCTCCCTTTTCAATGTAAGCTTTGACATCGGACGATGATTTAGCTCCCTCAATGTTCGGATGGAAATGTGTTGATCGGGATGGGGAAATGAGATCGAAAAATCTCGGGTTGGTACATTGGAATTTACCTTCGAATTGAATGAGAACATGGAGATGAGGCACCCCATCCTGATGTAGTTCTCTGCAAACCCTAATGAATTTGATATTCGTCGGGTAAGAAAGGGCTTGTAATTGGGAAAGGGCCTCTTCTTTTGTTAATGAGCATCGGGGATATGTTATGAAATAATTTTTGGCATTGATTTGAAAACGACCTGCTCTTGGCATATTTGCTGTCGTTTTAGATCGGGGGACACTCAAAACTCCAAGTGAATGGTGGAACGGGGGGCATTATATAGGATGTCCCCCGATGGCATATGTGTAAATAGGTAGAGTTACATTCAAAATTTGAATTTCGAATAATGGCGGCCATCCGATTAATATT
Gene Information
|
NCBI Accession
|
YP_008719942.1
|
|
Location
|
324-1124 |
|
Gene Name
|
BV1 |
|
Protein Name
|
NSP |
|
Coding Region
|
ATGTCTCCCGTTCGTCAATGCAAGATGTATTCGGTATACAGACGTGGGTATAAGACGCCGTATAGGAGTCCGTATGGCGCTCGTGGAACACCATATGTGAATCGTAAGACCTCTGGTAAACAGACGGCTAAATCTCGTGTATCGCGAAAGTTGGCGTATGAATCGCCAAAAGGTCTATATACGCGACGCTCATTGGAGGATATCCATAATGGGGCTGCCTTGAAGTTGCCGCAACAGGGGGATTATACGTCCTACGTGACACTCCCATGTCGAGGCATCGATGGTAATGGGGGTAGGTCTGTGGATCATATAAAATTATTAAATTTGAGGGTTTCTGGGACCGTCAACGTCAGTCAATCCGGTGGTGATGACAATATGGGAGAGAGAACGACCATGAGGGGTATTTTTTTCATGGCGTGTCTTGTTGATAAGAAACCCTTCGTTCCAGATGGGGTCAGCATATTGCCGACGTTTAATGAGTTGTTCGGGGAATATGAATCCGTTTATGGCATGCCTAGGTTGAAGGAAAACGTCCGTCACCGTTATCGCGTTATTGGGACGTCGAAATTATATATAACGACCGATGAAGATCACATCCAGAAGCCTTTTAGTCTACGTCGAAGACTAAGTGGAGGGAAATATCCTATATGGTCGTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGTAACTATAAAAATATAAATAAGAACGCTATACTCGTTAGTTATGTGTGGGTGTCGCTAAGTCGGACCACGTGTGATGTGTATTCGCAGTTTGTACTTAATTACGTCGGCTGA |
|
Protein Sequence
|
MSPVRQCKMYSVYRRGYKTPYRSPYGARGTPYVNRKTSGKQTAKSRVSRKLAYESPKGLYTRRSLEDIHNGAALKLPQQGDYTSYVTLPCRGIDGNGGRSVDHIKLLNLRVSGTVNVSQSGGDDNMGERTTMRGIFFMACLVDKKPFVPDGVSILPTFNELFGEYESVYGMPRLKENVRHRYRVIGTSKLYITTDEDHIQKPFSLRRRLSGGKYPIWSSFKDVDNSSTGGNYKNINKNAILVSYVWVSLSRTTCDVYSQFVLNYVG |
|
NCBI Accession
|
YP_008719943.1
|
|
Location
|
1255-2274 |
|
Gene Name
|
BC1 |
|
Protein Name
|
MP |
|
Coding Region
|
ATGCTTCCATGTCTACAAGACATTTTATCAACCTTGTTCTGCCTTTTATACATCTCTTCTCTCCGTTTCCTAACCCTTGTTTTTTTCATTCCTAGAATGGACAACCAATTCACCGTCACAGACAATAATTACATAAACAGCAAACGCACCGAGTACGCCTTAACCAACGATGCTGCACCAATCAATCTCCAATTTCCGAGCTCATTCGAGCAGGCGACCATGCGACTCAAAGGCCGATGTATGAAAATCGACCACATTATAATTGAATACCGCAACCAGGTCCCATTTAACGCAACTGGGTCGGTTATCGTAGAAATCCGAGACAATCGCGTCAGCCTTGAAGACGCAGCTCAAGCAGCATTCACTTTCCCAATAGCTTGCAACGTCGACCTCCACTACTTCTCTTCTACATATTTTTCGATTTCGGACCCCTCCCCTTGGAAAATAATGTACCGAGTCGAGGACTCCAACGTCGTAGAAGGCGTGAAATTCGCATCCATCAAAGCCAAGCTCCGATTATCATCGGCCAAACATTCCACAGACATACGTTTCAAACCCCCAACAATTAACATCTTATCCAAGGGATACACGAAAGACTGCATAGACTTTTGGTCTGTGGAAAAAGGAGAAACAAGACGGAGATTACTAAATCCAACTCCACATGCTCATAGTCCACGACCCATAGCCCACAGGCCCATCACCATCCTACCTGGAGAAACATGGGCAACTAAGTCTCAGATTGGGCTACCCAGCTCATCAGGCCCAACAAGGCTGGAACACTTTCGTTCACAGTCCATGAGAATGGACCCATCGACAATACCAACAGACTTAGACAACGACTCCACAGACTATCCTTACCAGAGACTACACAGATTACACACACCAGAGTTAGACCCAGGGGACTCGGTATCACAGGCCCAATCCGACTCAGTATCCAGAAAGGACCTCGAGACACTGCTTGAGAGTACCATCAACAAGTGCCTCATCAAGATCAAATCCGAAGCACCAAGGCCATTGTAA |
|
Protein Sequence
|
MLPCLQDILSTLFCLLYISSLRFLTLVFFIPRMDNQFTVTDNNYINSKRTEYALTNDAAPINLQFPSSFEQATMRLKGRCMKIDHIIIEYRNQVPFNATGSVIVEIRDNRVSLEDAAQAAFTFPIACNVDLHYFSSTYFSISDPSPWKIMYRVEDSNVVEGVKFASIKAKLRLSSAKHSTDIRFKPPTINILSKGYTKDCIDFWSVEKGETRRRLLNPTPHAHSPRPIAHRPITILPGETWATKSQIGLPSSSGPTRLEHFRSQSMRMDPSTIPTDLDNDSTDYPYQRLHRLHTPELDPGDSVSQAQSDSVSRKDLETLLESTINKCLIKIKSEAPRPL |
|
NCBI Accession
|
YP_008719944.1
|
|
Location
|
174-524 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGTGGGATCCATTGTTGAATGAGTTCCCCGAGTCTGTGCACGGTTTTCGCTGTATGCTTGCTATTAAATATTTGCAGGCTTTGGAGGAAACCTACGAGCCCAATACTTTGGGCCACGATCTAGTCCGTGATCTCATCTGTGTTATCCGAGCCCGTGATTATGTCGAAGCGACCCGCCGATATAATCATTTCCACTCCCGCCTCGAAGTGCGTCGAAGCTGCACTTCGACAGCCCGTTCAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCATACCAACAAGCGACGATCATGGACGTTCCGGCCCATGTATCGAAAGCCCAGAATGTACAGAATGTACAGAAGTCCTGA |
|
Protein Sequence
|
MWDPLLNEFPESVHGFRCMLAIKYLQALEETYEPNTLGHDLVRDLICVIRARDYVEATRRYNHFHSRLEVRRSCTSTARSAAVLLSPLSKAYQQATIMDVPAHVSKAQNVQNVQKS |
|
NCBI Accession
|
YP_008719945.1
|
|
Location
|
334-1110 |
|
Gene Name
|
AV1 |
|
Protein Name
|
CP |
|
Coding Region
|
ATGTCGAAGCGACCCGCCGATATAATCATTTCCACTCCCGCCTCGAAGTGCGTCGAAGCTGCACTTCGACAGCCCGTTCAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCATACCAACAAGCGACGATCATGGACGTTCCGGCCCATGTATCGAAAGCCCAGAATGTACAGAATGTACAGAAGTCCTGATGTTCCTCGAGGATGTGAAGGCCCATGTAAGGTACAGTCCTATGAACAGAGAGACGATGTTAAGCACACCGGTGCTGTGCGTTGTGTTAGTGATGTTACTCGTGGTTCGGGTATTACTCATAGGGTAGGGAAGAGATTTTGTGTTAAGTCAATATATGTGTTAGGAAAGATCTGGATGGATGAAAACATCAAGAAGCAAAACCATACTAACCAGGTGATGTTCTTCTTAGTCCGTGACAGAAGGCCTTATGGCACAAGCCCCATGGACTTTGGACAGGTTTTTAATATGTTTGATAATGAGCCCAGTACAGCTACTATTAAGAATGATTTGCGAGATAGGTTCCAAGTGTTGCGGAAATTCCATGCCACTGTGGTAGGTGGTCCCTCAGGCATGAAGGAGCAGGCGTTGATTAAGAGGTTTTTTAAGGTGAATAATCATGTTGTGTATAATCACCAGGAGGCAGCGAAGTATGAGAATCATACAGAAAATGCGTTGTTGTTGTATATGGCATGTACGCATGCCTCTAATCCAGTGTATGCTACGCTTAAAATACGCATCTATTTTTATGATGCAGTAACAAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKCVEAALRQPVQQPCCCPHCPRHTNKRRSWTFRPMYRKPRMYRMYRSPDVPRGCEGPCKVQSYEQRDDVKHTGAVRCVSDVTRGSGITHRVGKRFCVKSIYVLGKIWMDENIKKQNHTNQVMFFLVRDRRPYGTSPMDFGQVFNMFDNEPSTATIKNDLRDRFQVLRKFHATVVGGPSGMKEQALIKRFFKVNNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
|
NCBI Accession
|
YP_008719946.1
|
|
Location
|
1107-1511 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAAGAATGGCGTTTTTACTTGGGAAATAACAAATCCCCTCTATTTCGCAATCACCAACCACGACAAGAGACCAGGGAACATGCACCACGATATCATCACACTCCAGATACGGTTCAACCACAACATCAGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAAGGTCTGGACGACCTTACAGCCTCCGACTGGTCTTTTCTTAAAAGTATTTAGATATCAAGTGCTCAAATATTTAAATATGATAGGAGTTATTTCCATTAACACTGTACTTAGAGCTGTGATCATGTCCTGTACAATGTATTACTGGCCACACACTCAAGTTACGGAGCAACATGAAATAAAATTCAACCTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQAKNGVFTWEITNPLYFAITNHDKRPGNMHHDIITLQIRFNHNIRKALGIHKCFLNFKVWTTLQPPTGLFLKVFRYQVLKYLNMIGVISINTVLRAVIMSCTMYYWPHTQVTEQHEIKFNLY |
|
NCBI Accession
|
YP_008719947.1
|
|
Location
|
1252-1659 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCCACCTTCATCACCCTCCACGAGCCATTGTTCTCAAGTGCCTATCAAAGTCCAACACCGCACCGTGAAGAACAGGGCACTCAGACGTAGGAGGGTAGACCTCGAATGCGGCTGCTCGTTCTATCTCCATATCGACTGCATCAATCATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAAGAATGGCGTTTTTACTTGGGAAATAACAAATCCCCTCTATTTCGCAATCACCAACCACGACAAGAGACCAGGGAACATGCACCACGATATCATCACACTCCAGATACGGTTCAACCACAACATCAGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAAGGTCTGGACGACCTTACAGCCTCCGACTGGTCTTTTCTTAAAAGTATTTAG |
|
Protein Sequence
|
MPPSSPSTSHCSQVPIKVQHRTVKNRALRRRRVDLECGCSFYLHIDCINHGFSHRGTHHCASSKEWRFYLGNNKSPLFRNHQPRQETREHAPRYHHTPDTVQPQHQEGIGDSQVFSQLQGLDDLTASDWSFLKSI |
|
NCBI Accession
|
YP_008719948.1
|
|
Location
|
1568-2647 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCAAGAGCAGGTCGTTTTCAAATCAATGCCAAAAATTATTTCATAACATATCCCCGATGCTCATTAACAAAAGAAGAGGCCCTTTCCCAATTACAAGCCCTTTCTTACCCGACGAATATCAAATTCATTAGGGTTTGCAGAGAACTACATCAGGATGGGGTGCCTCATCTCCATGTTCTCATTCAATTCGAAGGTAAATTCCAATGTACCAACCCGAGATTTTTCGATCTCATTTCCCCATCCCGATCAACACATTTCCATCCGAACATTGAGGGAGCTAAATCATCGTCCGATGTCAAAGCTTACATTGAAAAGGGAGGGGAATTTCTTGACGATGGAGTTTTCCAAGTCGATGCCAGAAGTGCAAGGGGTGAGGGCCAGCATTTAGCTCAGGTATATGCAGAAGCGTTGAATGCTTCTTCTAAATCAGAAGCTCTTCAAATTATTAAAGAAAAAGATCCGAAGTCTTTTTTTTTACAGTTCCATAACATATCTGCTAACGCAGATAGAATCTTCCAGCTCCCGCCACAAACTTATGTAAGTCCGTTTTTATCATCCTCATTTACACACGTCCCAGACGAAATAGAAATATGGGTATCCGAAAATATATGCAGTCCCGCTGCGCGGCCATGGAGACCGATCAGTATTGTTCTAGAAGGCGATAGTAGGACAGGGAAGACGATGTGGGCCCGATCTCTGGGACCACACAACTACTTGTGTGGACATTTGGATCTTAGTCCAAAGGTCTACAGCAACGACGCCTGGTACAACGTCATTGATGACGTCGACCCACACTACCTCAAGCACTTCAAAGAATTTATGGGGGCCCAAAGGGACTGGCAAAGCAATACAAAGTACGGGAAGCCGATTCAAATTAAAGGCGGCATTCCCACTATCTTCCTCTGCAATCCAGGACCAACATCATCATATAAAGAGTTTCTGGAAGAGGAAAAGAACCAATCCCTTAAAGCCTGGGCTTTAAAGAATGCCACCTTCATCACCCTCCACGAGCCATTGTTCTCAAGTGCCTATCAAAGTCCAACACCGCACCGTGAAGAACAGGGCACTCAGACGTAG |
|
Protein Sequence
|
MPRAGRFQINAKNYFITYPRCSLTKEEALSQLQALSYPTNIKFIRVCRELHQDGVPHLHVLIQFEGKFQCTNPRFFDLISPSRSTHFHPNIEGAKSSSDVKAYIEKGGEFLDDGVFQVDARSARGEGQHLAQVYAEALNASSKSEALQIIKEKDPKSFFLQFHNISANADRIFQLPPQTYVSPFLSSSFTHVPDEIEIWVSENICSPAARPWRPISIVLEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEFLEEEKNQSLKAWALKNATFITLHEPLFSSAYQSPTPHREEQGTQT |