East African cassava mosaic Kenya virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000882315.1 |
| Isolate |
Kenya:Machakos, Mitaboni/Ngiini |
| Release date |
2015/2/22 |
| Submitter |
Bull,S.E., Briddon,R.W., Sserubombwe,W.S., Ngugi,K., Markham,P.G., Stanley,J. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
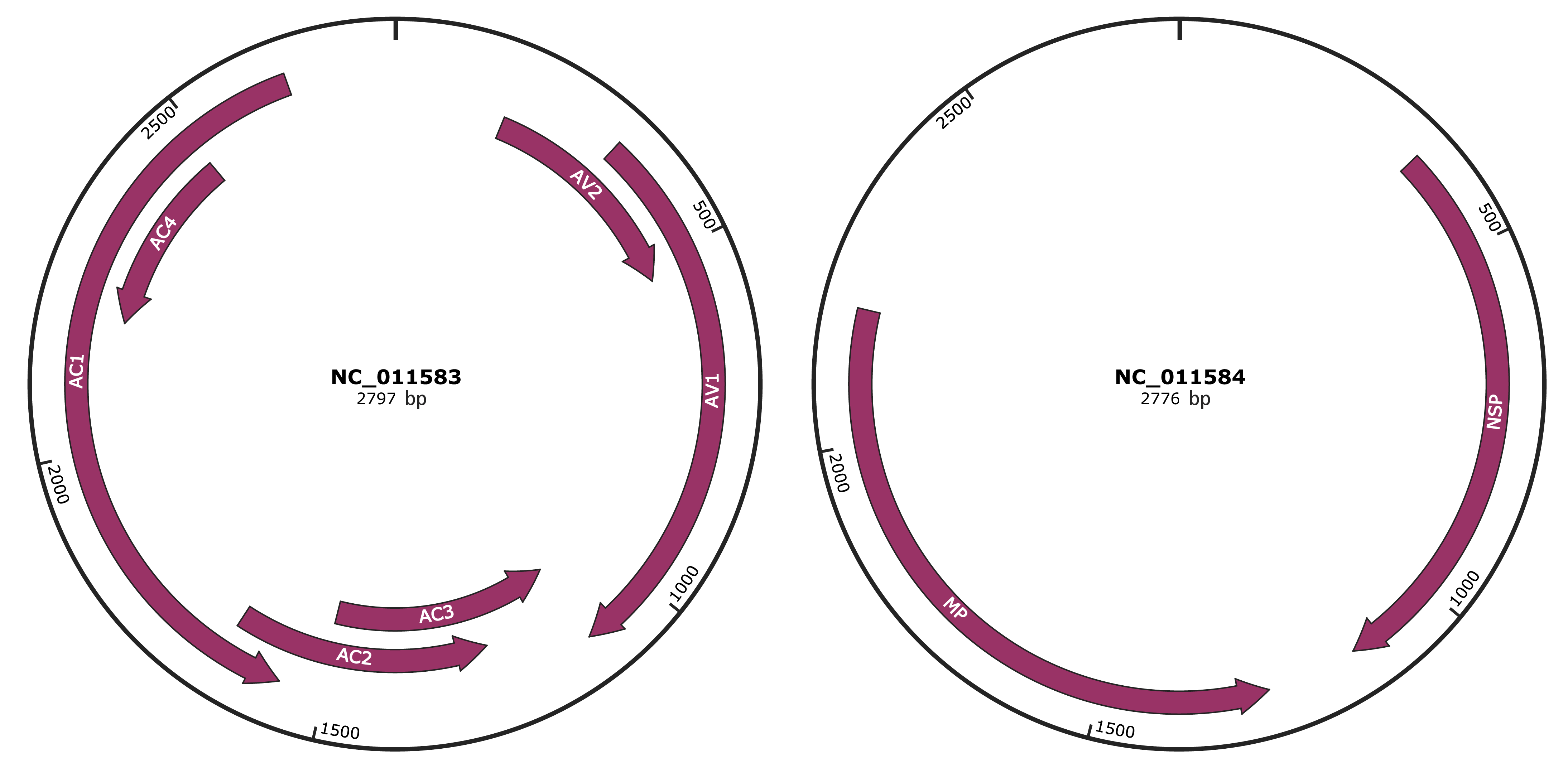
JBrowse
Genome
ACCGGATGGCCGCGCCCGAAAAAGCAGGTGGACCCCACAGGATGGCCGCGCCCGTGAAAGAAAGTGGTCCCTGCGCACTTGTTTTGGTCGGCCAGTCATATTCACGCGTGAAAGGCTAGATATATGTTGTTTGTCTTTATAGACTTCGTCGCGAAGTAGTGGAGCGCGTCAACATGTGGGATCCATTGTTGAACGACTTTCCCGAAACCGTTCACGGTTTCCGTTCTATGCTTGCTGTTAAATACCTGTTACATCTGGAACAGGAATACGACCGCGGTACTGTCGGGGCTGAGTATATACGGGATCTAATAGGGGTTCTACGGTGTAAGAGTTATGTCGAAGCGACCAGGAGATATAATAATCTCAACACCCGTATCCAAGGTGCGGAGGAGGCTGAACTTCGACAGCCCATACACGAACCGTGTTGTTGCCCCCACTGTCCGCGTCACCAGAAGCAAAATATGGGCCAACAGACCCATGTATCGGAAGCCCAAGATGTACAGAATGTATCGAAGCCCAGATGTCCCTAAGGGCTGTGAAGGCCCATGTAAGGTTCAGTCCTATGAACAGAGGGATGATGTTAAGCACACTGGTATGGTCCGATGTGTCAGTGATGTTACTCGTGGGTCAGGCATTACCCATAGAGTCGGGAAGAGGTTTTGTGTTAAGTCCATATATATATTGGGCAAGATCTGGATGGATGAGAATGTCAAGAAGCAAAATCACACGAACCATGTGATGTTCTTCCTCGTTCGAGATAGAAGGCCGTATGGTCCGAGTCCTCAAGATTTTGGGCAAGTGTTCAACATGTTTGATAATGAACCAACTACTGCAACTGTGAAGAATGATCTTAGGGACCGGTATCAGGTGTTACGTAAATTCTATGCGACTGTGGTTGGTGGACCCTCTGGGATGAAGGAACAAGCTCTGGTTAAGAGGTTTTTTAGGATCAATAATCATGTAGTGTATAATCATCAGGAACAGGCCAAGTATGAGAATCATACTGAGAATGCGTTGTTATTGTATATGGCATGTACACATGCCGCTAATCCTGTGTACGCTACGCTGAAAATACGCATCTATTTTTATGATGCAGTGACAAATTAATAAAGGTTGAATTTTATTGCATGTTGCTCCGTAACTTGGAGCGTGTTTAGTAATACATCGTACATAACATGATCAACAGCTTGAAGTACAGTGTTAATGGAAATAACGCCTATCATATCCAAATACTTGAGCATTTGATATCTAAATACTCTTAAGAAAAGACCAGTCTGAGGCCGTAAGGTCGTCCAGACCCTGAAGTTGAGAAAACACTTGTGAATCCCCAATGCCTTCCGGAGGTTGTGGTTGAACCGTATCTGGAGTGTGATGATGTCGTGGTTCATGTTCCCTGGCCTCTTGTCGTGGTTGGTGATTTCGAAATAGAGGGGATTTGTTATGTCCCAGGTAAAAACGCCATTCCTTGCTTGAGGCGCAGTGATGAGTTCCCCTGTGCGAGAATCCATGGTTGATGCAGTCGATATGGAGATAGAACGAGCAGCCGCATTCGAGGTCTACCCGCCTACGTCTGACGGCCCTGGTCTTCGCTGTGCGGTGTTGGACTTTGATGGGCACTAGAGAACAATGGCTCGTGGAGGGTGATGAAGGTGGCATTCTTTAAAGCCCAGGCTTTAAGGGACTGGTTCTTTTCCTCGTCCAGAAACTCTTTATATGATGATGTTGGGCCCGGATTGCAGAGGAAGATAGTGGGAATGCCGCCTTTAATTTGAATCGGCTTCCCGTACTTTGTATTGCTTTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTGAAGTGTTTGAGGTAGTGGGGGTCGACGTCATCAATGACGTTGTACCAGGCGTCGTTGCTGTAGACCTTTGGACTAAGATCCAGGTGTCCACACAAGTAGTTGTGTGGACCCAAAGAGCGGGCCCACATCGTCTTCCCCGTCCTACTATCGCCCTCGATGACGATACTAGTAGGTCTCCATGGCCGCGCAGCGGAACCCATCACGTTCTCGGAAACCCAATCTTCAAGTTCCTCAGGAACGTTAGTGAAAGAAGATGAAAGAAATGGAGAAACATAAGGAGTCAGAGGCTCTTGAAAAATCCTATCTAAATTGCTATGTAAATTATGAAACTGTAAAACAAAATCTTTTGGAGCTAGTTCGCGTATTACATTAAGAGCCTCTGACTTATTTGCTGAGTTAAGAGCCTTGGCGTAAGCGTCATTGGCTGATTGTTGTCCTCCTCGAGCAGATCGTCCGTCGATCTGAAACGTGCCCCATTGGATGGTGTCTCCGTCCTTGTCCATATAGGACTGGACGTCGGAGCTTGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCGGGATGGGGATATGAGGTCGAAGAATCGATGGTTGGTACAATTGTACTTGCCCTCGAACTGAATGAGGGCATGCAGATGAGGTTCCCCATTTTCATGGAGTTCTCTGCAGATCTTGATGAACAATTTATTTGTTGGGGTTTGGAGTTGTCGGATTTGATCCAATGCCTCCTCTTTGGATAGAGAGCATTTGGGATATGTTAGGAAATAGTTTTTGGCTTTGATGCTAAAACGACCAGCCCTTGGCATTTTCGCTGTCGTATAGCAATCGGGGGGCACTCAAAGTCTGTAGCAATCGGGGGAAAGGGGGGCAATTTATATGATGCCCCCTAAATGGCATTTATGTAATATCCTCATTGAATTTGAAATTCAAACGTGGAAAGCGGCCATCCGTATAATATT
ACCGGATGGCCGCGCCCGAAAAAGCAGGTGGACCCCACAATGGCCCCCACGCACTAAGTAATGTCAGCCAATCATGTTCAAGACTGGAAGACGCGGTAGTTACGCATTGATGAGTAAGTGGTCCCTACGCACTAATGTTGACAGGCAATTTGATTGCTATGTGTGTATCATATTTATATAGGTGTGCTACTGGTTAATCTAAAGTTAGGTGATGGGGCCTATCATAAAAACGCAATACATAGGTACGTATGTACATATTGATTATATTTTATGTTGCGGATATATGAGCCGCCACGTGTATAATGGATATGGAATGTCCTATAAATATTTGGCATGTCCCCGTTCGTTAATGCAAGATGTATTCTGTTTACAGACGTGGGTATAAGACTCCGTATAGGAGTCCGTATGGCGCTCGTGTAACACCATATGTTTATCGTAAGACTGCTGTTAAACAGACGTCTAAATCTCGTGTACCGCGAAAGTTGGCGTATGAATCGCCAAAATGTCTATATACGCGACGCTCATTGGAGGATATCCATAATGGGGCTTCCTTAAAGTTACCTCAACAGGGGGATTATACGTCCTACGTGACACTCCCATGTCGAGGTATCGATGGTAATGGGGGAAGGTCTGTTGATCATATAAAATTATTAAGCTTGAGGGTTTCGGGGACCGTCAACGTCAGTCAATGCGGTGGTGATGATAATATGGGAGAGAGAACGACCATGAGGGGTATTTTTTTCATGGCTTGTCTTGTTGATAAGAAACCTTTCGTTCCAGAGGGGGTGAGTATATTGCCGACGTTTAATGAGTTGTTCGGGGAATATGAATCCGTGTATGGCATGCCTAGGTTGAAGGAAAACGTCCGTCACCGTTATCGCGTGATTGGGACGTCGAAATTATATATAACGACCGATGAAGATCACATCCAGAAGCCATTTAGTCTACGTCGAAGATTAAGTGGAGGGAAATATCCTATGTGGTCGTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGGAACTATAAAAATATAAATAAGAACGCTATACTAGTTAGTTATGTGTGGGTATCGCTATGTCGGACCACGTGTGATGTGTATTCGCAGTTTGTACTTAATTACGTCGGTTGATAATAAAACGAGAGATGTGTGTTGACATTAATTATGTTTGAACTAACGAAACATGAGATGAACATCAATGGAAAGCGCATATAGTTTTATTATGTAGCGAATCAAATATTGTACATATCAATTGTTTATTACAATTGCCTTGGTGCCTCGGATTTTATTTTGATGAGACACTTGTTTATGGTACTCTCAAGCAGTGTCTCGAGGTCCTTTCTTGATACTGAGTCGGATGGGGTCTGTGATACCGAGTCCCCTGGGTCCAATTCGGGTGTGTGTAATCTGTGTAGTGTCTGGTAAGGATATTCTGTGGAGTCGTTGTCTAAGTCCGTCGGTGTTGTCGATGGGTCCATTCTCATGGACTGTGAACGAAAGTGTTCCAGCCTTGCTGGGCCGGATGAGCTTGGTAGCCCAATCTGAGACTTTGTGGCCCATGTTTCGCCAGGAAGAATGGTGATGGGCCTGTGGGTTATGGGTCGTTGACTATGAGCAGTTGGAGTTGGATTTAGTAATCTCCGTCGTGTTTCTCCTTTTTCCACGGACCAGAAGTCTATGCAATCCTTTGTGTATCCCTTGGATAAGATGTTAATTGTTGGGGATTTGAAACGTATGTCCGTGGAATGTTTGGCCGATGATAATCGGAGCTTGGCCTTTATGGATGCGAATTTCACGCCTTCTATGACGTTTGAGTCTTCGACTCTGTACATGATTCTCCAAGGGGAGGGTTCTGAAATCGAAAAATATGTAGAAGAGAAGTAGTGGAGGTCTACGTTGCAAGCTATTGGGAAAGTGAATGCTGCTTGAGCAGCGTCCTCAAGGCTGACGCGATTGTCTCTGATTTCTACGATAACCGACCCAATTGCGTTAAATGGGACCTGGTTTCGGTATTCAATTATAATGTGGTCGATTTTCATACATCGGCCTTTGAGTCGCATGGTCGCCTGCTCGAATGAGCTCGGAAATTGGAGATTGATTGGTGCAGCATCGTTGGTTAATGCGTACTCTGTGCGTTTGCTGTTGATGTAATTATTGTCTGTGACGGTGAATTGGTTGTCCATTCTATGAATGAAAAAAAACAAGGGTTAGTAAATGGAGAGAAGAAATGTATAAAAGTCATAGCAAGGTATATAAAATGTCTTGTAGACATGGAAGCATATATGCATTTGGTATCGATAATAACACATTAAAGCAGAAGAAGGATCATATATGTATAATTGGCCGCGCAGCGGATTGGAAGTCAGACAAATCGGCGAACAAATAAAAAAGTCGAATGAGGTGAAGGGATTGAAACGACTTACGGAAGCACCGATGAAGCAGTCTGGAGTGAATTCCAGATATAATTGGAGAAAACAAAGAAATAAAAGTTAACGAAATAAAAGTATAACTTATGGGTATAGAAAGGAAAGTGAGCAGATGTTATGCGCCGTGTCGTTAAATGAGATGTTATTGGGTGTTTATATAGGCGTTAATAAGCAACACGTGGTAGAGATAGAAAGAAGAAAGAGGCGAGAGCATTCGGGGGGCACTCAAAGTCTGTAGCAATCGGGGGAAAGGGGGGCAATTTATATGATGCCCCCTAAATGGCATTTATGTAATATCCTCAATGAATTTGAAATTCAAACGTGGAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_002317394.1
|
|
Location
|
174-530 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCATTGTTGAACGACTTTCCCGAAACCGTTCACGGTTTCCGTTCTATGCTTGCTGTTAAATACCTGTTACATCTGGAACAGGAATACGACCGCGGTACTGTCGGGGCTGAGTATATACGGGATCTAATAGGGGTTCTACGGTGTAAGAGTTATGTCGAAGCGACCAGGAGATATAATAATCTCAACACCCGTATCCAAGGTGCGGAGGAGGCTGAACTTCGACAGCCCATACACGAACCGTGTTGTTGCCCCCACTGTCCGCGTCACCAGAAGCAAAATATGGGCCAACAGACCCATGTATCGGAAGCCCAAGATGTACAGAATGTATCGAAGCCCAGATGTCCCTAA |
|
Protein Sequence
|
MWDPLLNDFPETVHGFRSMLAVKYLLHLEQEYDRGTVGAEYIRDLIGVLRCKSYVEATRRYNNLNTRIQGAEEAELRQPIHEPCCCPHCPRHQKQNMGQQTHVSEAQDVQNVSKPRCP |
|
NCBI Accession
|
YP_002317395.1
|
|
Location
|
334-1107 |
|
Gene Name
|
AV1 |
|
Protein Name
|
AV1 protein |
|
Coding Region
|
ATGTCGAAGCGACCAGGAGATATAATAATCTCAACACCCGTATCCAAGGTGCGGAGGAGGCTGAACTTCGACAGCCCATACACGAACCGTGTTGTTGCCCCCACTGTCCGCGTCACCAGAAGCAAAATATGGGCCAACAGACCCATGTATCGGAAGCCCAAGATGTACAGAATGTATCGAAGCCCAGATGTCCCTAAGGGCTGTGAAGGCCCATGTAAGGTTCAGTCCTATGAACAGAGGGATGATGTTAAGCACACTGGTATGGTCCGATGTGTCAGTGATGTTACTCGTGGGTCAGGCATTACCCATAGAGTCGGGAAGAGGTTTTGTGTTAAGTCCATATATATATTGGGCAAGATCTGGATGGATGAGAATGTCAAGAAGCAAAATCACACGAACCATGTGATGTTCTTCCTCGTTCGAGATAGAAGGCCGTATGGTCCGAGTCCTCAAGATTTTGGGCAAGTGTTCAACATGTTTGATAATGAACCAACTACTGCAACTGTGAAGAATGATCTTAGGGACCGGTATCAGGTGTTACGTAAATTCTATGCGACTGTGGTTGGTGGACCCTCTGGGATGAAGGAACAAGCTCTGGTTAAGAGGTTTTTTAGGATCAATAATCATGTAGTGTATAATCATCAGGAACAGGCCAAGTATGAGAATCATACTGAGAATGCGTTGTTATTGTATATGGCATGTACACATGCCGCTAATCCTGTGTACGCTACGCTGAAAATACGCATCTATTTTTATGATGCAGTGACAAATTAA |
|
Protein Sequence
|
MSKRPGDIIISTPVSKVRRRLNFDSPYTNRVVAPTVRVTRSKIWANRPMYRKPKMYRMYRSPDVPKGCEGPCKVQSYEQRDDVKHTGMVRCVSDVTRGSGITHRVGKRFCVKSIYILGKIWMDENVKKQNHTNHVMFFLVRDRRPYGPSPQDFGQVFNMFDNEPTTATVKNDLRDRYQVLRKFYATVVGGPSGMKEQALVKRFFRINNHVVYNHQEQAKYENHTENALLLYMACTHAANPVYATLKIRIYFYDAVTN |
|
NCBI Accession
|
YP_002317396.1
|
|
Location
|
1104-1508 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAGGAATGGCGTTTTTACCTGGGACATAACAAATCCCCTCTATTTCGAAATCACCAACCACGACAAGAGGCCAGGGAACATGAACCACGACATCATCACACTCCAGATACGGTTCAACCACAACCTCCGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAGGGTCTGGACGACCTTACGGCCTCAGACTGGTCTTTTCTTAAGAGTATTTAGATATCAAATGCTCAAGTATTTGGATATGATAGGCGTTATTTCCATTAACACTGTACTTCAAGCTGTTGATCATGTTATGTACGATGTATTACTAAACACGCTCCAAGTTACGGAGCAACATGCAATAAAATTCAACCTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQARNGVFTWDITNPLYFEITNHDKRPGNMNHDIITLQIRFNHNLRKALGIHKCFLNFRVWTTLRPQTGLFLRVFRYQMLKYLDMIGVISINTVLQAVDHVMYDVLLNTLQVTEQHAIKFNLY |
|
NCBI Accession
|
YP_002317397.1
|
|
Location
|
1249-1656 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCCACCTTCATCACCCTCCACGAGCCATTGTTCTCTAGTGCCCATCAAAGTCCAACACCGCACAGCGAAGACCAGGGCCGTCAGACGTAGGCGGGTAGACCTCGAATGCGGCTGCTCGTTCTATCTCCATATCGACTGCATCAACCATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAGGAATGGCGTTTTTACCTGGGACATAACAAATCCCCTCTATTTCGAAATCACCAACCACGACAAGAGGCCAGGGAACATGAACCACGACATCATCACACTCCAGATACGGTTCAACCACAACCTCCGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAGGGTCTGGACGACCTTACGGCCTCAGACTGGTCTTTTCTTAAGAGTATTTAG |
|
Protein Sequence
|
MPPSSPSTSHCSLVPIKVQHRTAKTRAVRRRRVDLECGCSFYLHIDCINHGFSHRGTHHCASSKEWRFYLGHNKSPLFRNHQPRQEAREHEPRHHHTPDTVQPQPPEGIGDSQVFSQLQGLDDLTASDWSFLKSI |
|
NCBI Accession
|
YP_002317398.1
|
|
Location
|
1565-2644 |
|
Gene Name
|
AC1 |
|
Protein Name
|
AC1 protein |
|
Coding Region
|
ATGCCAAGGGCTGGTCGTTTTAGCATCAAAGCCAAAAACTATTTCCTAACATATCCCAAATGCTCTCTATCCAAAGAGGAGGCATTGGATCAAATCCGACAACTCCAAACCCCAACAAATAAATTGTTCATCAAGATCTGCAGAGAACTCCATGAAAATGGGGAACCTCATCTGCATGCCCTCATTCAGTTCGAGGGCAAGTACAATTGTACCAACCATCGATTCTTCGACCTCATATCCCCATCCCGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCAAGCTCCGACGTCCAGTCCTATATGGACAAGGACGGAGACACCATCCAATGGGGCACGTTTCAGATCGACGGACGATCTGCTCGAGGAGGACAACAATCAGCCAATGACGCTTACGCCAAGGCTCTTAACTCAGCAAATAAGTCAGAGGCTCTTAATGTAATACGCGAACTAGCTCCAAAAGATTTTGTTTTACAGTTTCATAATTTACATAGCAATTTAGATAGGATTTTTCAAGAGCCTCTGACTCCTTATGTTTCTCCATTTCTTTCATCTTCTTTCACTAACGTTCCTGAGGAACTTGAAGATTGGGTTTCCGAGAACGTGATGGGTTCCGCTGCGCGGCCATGGAGACCTACTAGTATCGTCATCGAGGGCGATAGTAGGACGGGGAAGACGATGTGGGCCCGCTCTTTGGGTCCACACAACTACTTGTGTGGACACCTGGATCTTAGTCCAAAGGTCTACAGCAACGACGCCTGGTACAACGTCATTGATGACGTCGACCCCCACTACCTCAAACACTTCAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAATACAAAGTACGGGAAGCCGATTCAAATTAAAGGCGGCATTCCCACTATCTTCCTCTGCAATCCGGGCCCAACATCATCATATAAAGAGTTTCTGGACGAGGAAAAGAACCAGTCCCTTAAAGCCTGGGCTTTAAAGAATGCCACCTTCATCACCCTCCACGAGCCATTGTTCTCTAGTGCCCATCAAAGTCCAACACCGCACAGCGAAGACCAGGGCCGTCAGACGTAG |
|
Protein Sequence
|
MPRAGRFSIKAKNYFLTYPKCSLSKEEALDQIRQLQTPTNKLFIKICRELHENGEPHLHALIQFEGKYNCTNHRFFDLISPSRSAHFHPNIQGAKSSSDVQSYMDKDGDTIQWGTFQIDGRSARGGQQSANDAYAKALNSANKSEALNVIRELAPKDFVLQFHNLHSNLDRIFQEPLTPYVSPFLSSSFTNVPEELEDWVSENVMGSAARPWRPTSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEFLDEEKNQSLKAWALKNATFITLHEPLFSSAHQSPTPHSEDQGRQT |
|
NCBI Accession
|
YP_002317399.1
|
|
Location
|
2197-2487 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAACCTCATCTGCATGCCCTCATTCAGTTCGAGGGCAAGTACAATTGTACCAACCATCGATTCTTCGACCTCATATCCCCATCCCGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCAAGCTCCGACGTCCAGTCCTATATGGACAAGGACGGAGACACCATCCAATGGGGCACGTTTCAGATCGACGGACGATCTGCTCGAGGAGGACAACAATCAGCCAATGACGCTTACGCCAAGGCTCTTAACTCAGCAAATAAGTCAGAGGCTCTTAATGTAA |
|
Protein Sequence
|
MGNLICMPSFSSRASTIVPTIDSSTSYPHPGQHISIQTFRELNQAPTSSPIWTRTETPSNGARFRSTDDLLEEDNNQPMTLTPRLLTQQISQRLLM |
|
NCBI Accession
|
YP_002317400.1
|
|
Location
|
357-1133 |
|
Gene Name
|
NSP |
|
Protein Name
|
BV1 |
|
Coding Region
|
ATGTATTCTGTTTACAGACGTGGGTATAAGACTCCGTATAGGAGTCCGTATGGCGCTCGTGTAACACCATATGTTTATCGTAAGACTGCTGTTAAACAGACGTCTAAATCTCGTGTACCGCGAAAGTTGGCGTATGAATCGCCAAAATGTCTATATACGCGACGCTCATTGGAGGATATCCATAATGGGGCTTCCTTAAAGTTACCTCAACAGGGGGATTATACGTCCTACGTGACACTCCCATGTCGAGGTATCGATGGTAATGGGGGAAGGTCTGTTGATCATATAAAATTATTAAGCTTGAGGGTTTCGGGGACCGTCAACGTCAGTCAATGCGGTGGTGATGATAATATGGGAGAGAGAACGACCATGAGGGGTATTTTTTTCATGGCTTGTCTTGTTGATAAGAAACCTTTCGTTCCAGAGGGGGTGAGTATATTGCCGACGTTTAATGAGTTGTTCGGGGAATATGAATCCGTGTATGGCATGCCTAGGTTGAAGGAAAACGTCCGTCACCGTTATCGCGTGATTGGGACGTCGAAATTATATATAACGACCGATGAAGATCACATCCAGAAGCCATTTAGTCTACGTCGAAGATTAAGTGGAGGGAAATATCCTATGTGGTCGTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGGAACTATAAAAATATAAATAAGAACGCTATACTAGTTAGTTATGTGTGGGTATCGCTATGTCGGACCACGTGTGATGTGTATTCGCAGTTTGTACTTAATTACGTCGGTTGA |
|
Protein Sequence
|
MYSVYRRGYKTPYRSPYGARVTPYVYRKTAVKQTSKSRVPRKLAYESPKCLYTRRSLEDIHNGASLKLPQQGDYTSYVTLPCRGIDGNGGRSVDHIKLLSLRVSGTVNVSQCGGDDNMGERTTMRGIFFMACLVDKKPFVPEGVSILPTFNELFGEYESVYGMPRLKENVRHRYRVIGTSKLYITTDEDHIQKPFSLRRRLSGGKYPMWSSFKDVDNSSTGGNYKNINKNAILVSYVWVSLCRTTCDVYSQFVLNYVG |
|
NCBI Accession
|
YP_002317401.1
|
|
Location
|
1262-2185 |
|
Gene Name
|
MP |
|
Protein Name
|
BC1 |
|
Coding Region
|
ATGGACAACCAATTCACCGTCACAGACAATAATTACATCAACAGCAAACGCACAGAGTACGCATTAACCAACGATGCTGCACCAATCAATCTCCAATTTCCGAGCTCATTCGAGCAGGCGACCATGCGACTCAAAGGCCGATGTATGAAAATCGACCACATTATAATTGAATACCGAAACCAGGTCCCATTTAACGCAATTGGGTCGGTTATCGTAGAAATCAGAGACAATCGCGTCAGCCTTGAGGACGCTGCTCAAGCAGCATTCACTTTCCCAATAGCTTGCAACGTAGACCTCCACTACTTCTCTTCTACATATTTTTCGATTTCAGAACCCTCCCCTTGGAGAATCATGTACAGAGTCGAAGACTCAAACGTCATAGAAGGCGTGAAATTCGCATCCATAAAGGCCAAGCTCCGATTATCATCGGCCAAACATTCCACGGACATACGTTTCAAATCCCCAACAATTAACATCTTATCCAAGGGATACACAAAGGATTGCATAGACTTCTGGTCCGTGGAAAAAGGAGAAACACGACGGAGATTACTAAATCCAACTCCAACTGCTCATAGTCAACGACCCATAACCCACAGGCCCATCACCATTCTTCCTGGCGAAACATGGGCCACAAAGTCTCAGATTGGGCTACCAAGCTCATCCGGCCCAGCAAGGCTGGAACACTTTCGTTCACAGTCCATGAGAATGGACCCATCGACAACACCGACGGACTTAGACAACGACTCCACAGAATATCCTTACCAGACACTACACAGATTACACACACCCGAATTGGACCCAGGGGACTCGGTATCACAGACCCCATCCGACTCAGTATCAAGAAAGGACCTCGAGACACTGCTTGAGAGTACCATAAACAAGTGTCTCATCAAAATAAAATCCGAGGCACCAAGGCAATTGTAA |
|
Protein Sequence
|
MDNQFTVTDNNYINSKRTEYALTNDAAPINLQFPSSFEQATMRLKGRCMKIDHIIIEYRNQVPFNAIGSVIVEIRDNRVSLEDAAQAAFTFPIACNVDLHYFSSTYFSISEPSPWRIMYRVEDSNVIEGVKFASIKAKLRLSSAKHSTDIRFKSPTINILSKGYTKDCIDFWSVEKGETRRRLLNPTPTAHSQRPITHRPITILPGETWATKSQIGLPSSSGPARLEHFRSQSMRMDPSTTPTDLDNDSTEYPYQTLHRLHTPELDPGDSVSQTPSDSVSRKDLETLLESTINKCLIKIKSEAPRQL |