Ageratum enation virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000859025.1 |
| Isolate |
Nepal |
| Release date |
2015/2/13 |
| Submitter |
Briddon,R.W., Bull,S.E., Markham,P.G. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
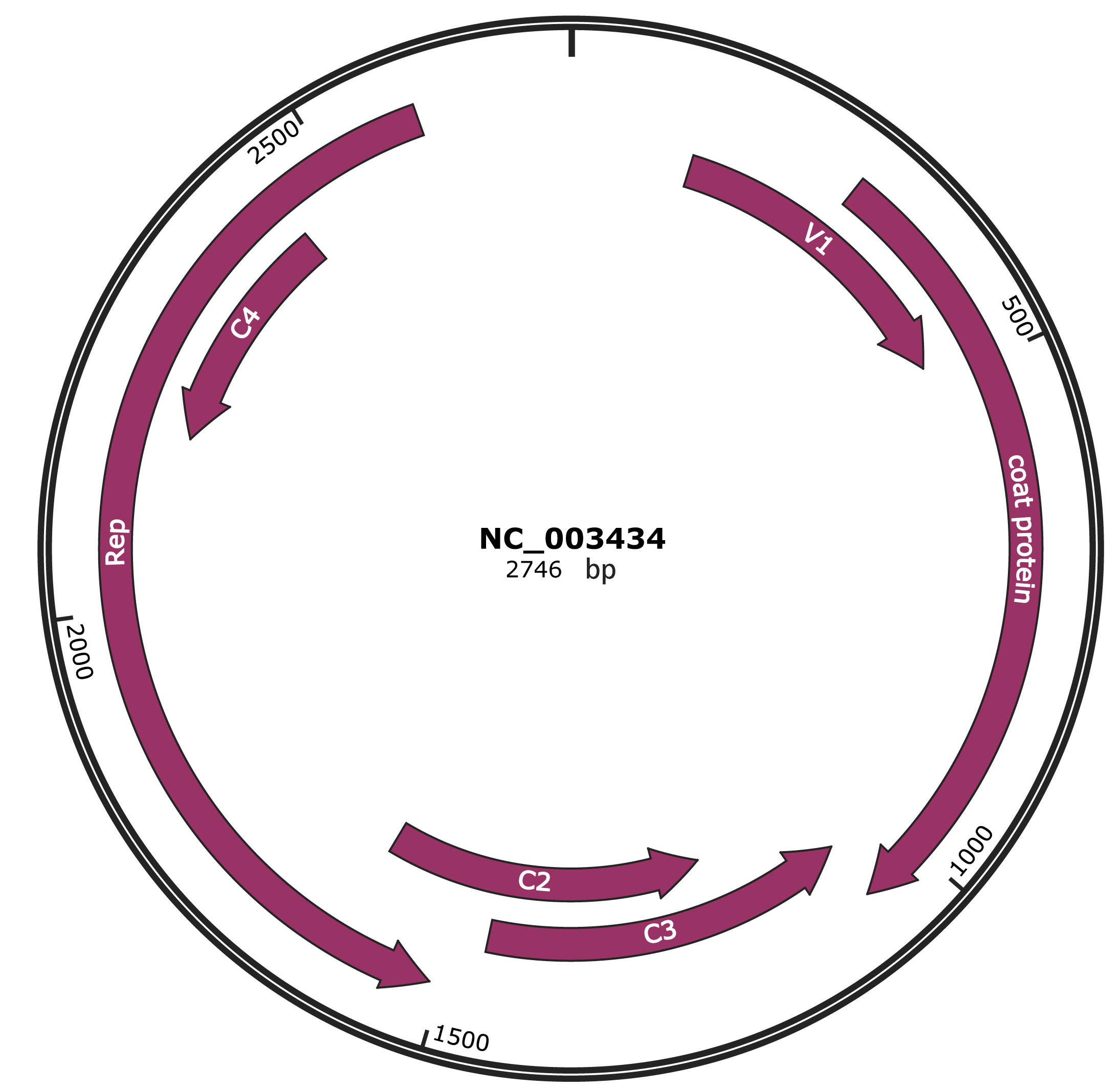
JBrowse
Genome
ACCGGATGGCCGCGAATTTTTTGTGGCCCCCGCAACGCATTTACATGTGGACCAATGAAATTGGCTCCTCGTGGCTTAATTGTTTTGTGGTCCCCTATTTAAACTTGCTCACCAAGTAGTGCGCTCCGCACTATGTGGGATCCATTAGTAAACGAGTTTCCCGAAACCGTTCACGGTTTTAGATGTATGTTAGCAGTTAAATATCTGCAGTTAGTAGAGAAGACTTATTCGCCTGACACATTAGGGCACGATTTAATTAGGGATTTAATTTCAGTTATTAGGGCTAGAAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCTTCGAAGGGACGCCGACGTCTCAACTTCGACAGCCCATATGTGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCAAGAGCATGGGCGAACAGGCCCATGAACAGAAAACCCAGGATGTACAGGATGTACAGAAGTCCTGATGTCCCTAGAGGATGTGAAGGTCCATGTAAGGGCCAGTCTTTTGAGTCTAGACATGACATTCAGCATATAGGTAAAGTTATGTGTGTCAGTGATGTTACGCGTGGAACTGGGCTGACTCATCGAGTGGGTAAAAGGTTTTGTGTTAAATCCGTTTATGTCTTGGGTAAGATCTGGATGGATGAAAATATTAAGACCAAGAACCACACTAACAGTGTTATGTTTTTTTTAGTTAGGGATCGTAGGCCTGTCGATAAACCTCAAGATTTTGGAGAGGTTTTTAACATGTTTGATAATGAGCCCAGTACGGCTACTGTGAAGAATGTTCATCGTGATAGGTATCAAGTGCTTCGGAAATGGCATGCAACTGTTACGGGTGGACAATATGCGTCAAAGGAACAAGCTCTTGTGAAGAAGTTTGTTAGGGTTAATAATTATGTTGTGTATAATCAGCAAGAAGCTGGCAAGTATGAGAATCATTCTGAGAATGCGTTAATGTTGTATATGGCATGTACTCATGCCTCTAACCCAGTGTATGCTACTTTGAAGATACGGATCTATTTCTATGATTCTGTAACAAATTAATAAATATTGAATTTTATTGAATAAGATTGGTCTACATATACAATGTGTTCTAATACATCCCATAATACATGATCAACTGCACGAATTACATTATTAATACTGATAATTCCTAAATTATTTAAATATTTAAGCACTTGGGTCTTAAAGACCCTTAAGAATTGCCCAGTCGGAGGCTGTGAAGTCATCCAGATTCGGTAGGCTAGAAAACACTTGTGTATCTCCAACGCTTTCCTCAGGTTGTAATTGAACTGTATTTGGACGGTGATGATGTCCTCTTTCATAAGAAATGGCCGGTTGTTGTGTTCTGTTATCTTGAAATACAGGGGATTTTGAATCTCCCAGATAAACACGCCATTCTCTGCTTGAGAAGCTTTGATGAGTTCCGCTGTGCGTGAATCCATGGTTGTGGCAGGCTAATGCTATGAAGTATGAACACCCACAAGGGAGATCAACACGTCGACGCCTCGTCCCCTTCTTGGCTAGCCTGTGCTGCACTTTGATTGGAACCTGAGTAGAGTGGGCCTTCGAGGGTGACGAAGATCGCATTCTTTAAAGCCCAATTTTTGAGAGCATTATTCTTCTCTTCATCCAAGAACTCTTTATAACTTGAATTAGGTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCGCCTTTAATTTGAACTGGCTTTCCGTACTTGGTATTTGATTGCCAGTCCCTTTGGGCCCCCATGAATTCCTTAAAGTGCTTTAGGTAGTGAGGATCTACGTCATCGATGATGTTATACCACGCATCATTGCTGTAAACTTTGGGGCTTAGATCTAAATGACCGCATAGGTAATTATGAGGCCCTAATGACCTAGCCCACATCGTTTTACCCGTACGACTGTCTCCCTCAATTACTATACTTTGAGGCCTCAGAGGCCGCGCAGCGGCATTCATGACATTTTCTGAGACCCATTCTTCAAGTTCTTCAGGAACTTGATCAAAAGAAGAAGATAAAAAAGGCGAAACATAAACCTCCAACGGAGGAGTAAAAATCCTATCTAAATTAGAATTTAAATTATGATATTGAAAAATAAATTTTTCTGGGAGTTTCTCCTTTATTATAGCCATTGCAGCTTCTTTAGAACCTGCATTTAGGGCTTCTGCAGCAGCATCATTAGCTGTCTGTTGACCTCCTCGTGCAGATCTCCCATCGATCTGGAACTCTCCCCATTCGAGGGTGTCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGTGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGTTTGGGGAGACCAGGTCGAAGAATCGTTGATTCTTGCACTGATATTTCCCTTCGAACTGGATGAGCACATGGAGATGAGGGCTCCCATCTTCGTGTAGTTCTCTGCAGATCTTGATGTATTTTTTGTTTGTTGGGGGTTGGAGATTTAATAATTGGGAAAGTGCCTCTTCTTTAGTAAGGGAGCACTTGGGATAAGTGAGAAAATAATTTTTGGCATTTATTTTTAACCGATTCGGGGCTGCCATGTTGACTTAGTCAATCGGTGTCTCTCAACCTTCTCTATGTATCGGTGTATCGGAGTCCTATATATATGGAGACTCCAATGGCATAATTGTAATAACAAAACTTTAATTTGAAATCCTTAACGCTCCAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
NP_598186.1
|
|
Location
|
133-480 |
|
Gene Name
|
V1 |
|
Protein Name
|
V1 protein |
|
Coding Region
|
ATGTGGGATCCATTAGTAAACGAGTTTCCCGAAACCGTTCACGGTTTTAGATGTATGTTAGCAGTTAAATATCTGCAGTTAGTAGAGAAGACTTATTCGCCTGACACATTAGGGCACGATTTAATTAGGGATTTAATTTCAGTTATTAGGGCTAGAAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCTTCGAAGGGACGCCGACGTCTCAACTTCGACAGCCCATATGTGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCAAGAGCATGGGCGAACAGGCCCATGAACAGAAAACCCAGGATGTACAGGATGTACAGAAGTCCTGA |
|
Protein Sequence
|
MWDPLVNEFPETVHGFRCMLAVKYLQLVEKTYSPDTLGHDLIRDLISVIRARNYVEATSRYNHFHARFEGTPTSQLRQPICEPCCCPHCPRHQSKSMGEQAHEQKTQDVQDVQKS |
|
NCBI Accession
|
NP_598187.1
|
|
Location
|
293-1063 |
|
Gene Name
|
coat protein |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCTTCGAAGGGACGCCGACGTCTCAACTTCGACAGCCCATATGTGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCAAGAGCATGGGCGAACAGGCCCATGAACAGAAAACCCAGGATGTACAGGATGTACAGAAGTCCTGATGTCCCTAGAGGATGTGAAGGTCCATGTAAGGGCCAGTCTTTTGAGTCTAGACATGACATTCAGCATATAGGTAAAGTTATGTGTGTCAGTGATGTTACGCGTGGAACTGGGCTGACTCATCGAGTGGGTAAAAGGTTTTGTGTTAAATCCGTTTATGTCTTGGGTAAGATCTGGATGGATGAAAATATTAAGACCAAGAACCACACTAACAGTGTTATGTTTTTTTTAGTTAGGGATCGTAGGCCTGTCGATAAACCTCAAGATTTTGGAGAGGTTTTTAACATGTTTGATAATGAGCCCAGTACGGCTACTGTGAAGAATGTTCATCGTGATAGGTATCAAGTGCTTCGGAAATGGCATGCAACTGTTACGGGTGGACAATATGCGTCAAAGGAACAAGCTCTTGTGAAGAAGTTTGTTAGGGTTAATAATTATGTTGTGTATAATCAGCAAGAAGCTGGCAAGTATGAGAATCATTCTGAGAATGCGTTAATGTTGTATATGGCATGTACTCATGCCTCTAACCCAGTGTATGCTACTTTGAAGATACGGATCTATTTCTATGATTCTGTAACAAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKGRRRLNFDSPYVSRAAAPIVRVTKARAWANRPMNRKPRMYRMYRSPDVPRGCEGPCKGQSFESRHDIQHIGKVMCVSDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWHATVTGGQYASKEQALVKKFVRVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
|
NCBI Accession
|
NP_598188.1
|
|
Location
|
1060-1464 |
|
Gene Name
|
C3 |
|
Protein Name
|
C3 protein |
|
Coding Region
|
ATGGATTCACGCACAGCGGAACTCATCAAAGCTTCTCAAGCAGAGAATGGCGTGTTTATCTGGGAGATTCAAAATCCCCTGTATTTCAAGATAACAGAACACAACAACCGGCCATTTCTTATGAAAGAGGACATCATCACCGTCCAAATACAGTTCAATTACAACCTGAGGAAAGCGTTGGAGATACACAAGTGTTTTCTAGCCTACCGAATCTGGATGACTTCACAGCCTCCGACTGGGCAATTCTTAAGGGTCTTTAAGACCCAAGTGCTTAAATATTTAAATAATTTAGGAATTATCAGTATTAATAATGTAATTCGTGCAGTTGATCATGTATTATGGGATGTATTAGAACACATTGTATATGTAGACCAATCTTATTCAATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MDSRTAELIKASQAENGVFIWEIQNPLYFKITEHNNRPFLMKEDIITVQIQFNYNLRKALEIHKCFLAYRIWMTSQPPTGQFLRVFKTQVLKYLNNLGIISINNVIRAVDHVLWDVLEHIVYVDQSYSIKFNIY |
|
NCBI Accession
|
NP_598189.1
|
|
Location
|
1205-1609 |
|
Gene Name
|
C2 |
|
Protein Name
|
C2 protein |
|
Coding Region
|
ATGCGATCTTCGTCACCCTCGAAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAGCACAGGCTAGCCAAGAAGGGGACGAGGCGTCGACGTGTTGATCTCCCTTGTGGGTGTTCATACTTCATAGCATTAGCCTGCCACAACCATGGATTCACGCACAGCGGAACTCATCAAAGCTTCTCAAGCAGAGAATGGCGTGTTTATCTGGGAGATTCAAAATCCCCTGTATTTCAAGATAACAGAACACAACAACCGGCCATTTCTTATGAAAGAGGACATCATCACCGTCCAAATACAGTTCAATTACAACCTGAGGAAAGCGTTGGAGATACACAAGTGTTTTCTAGCCTACCGAATCTGGATGACTTCACAGCCTCCGACTGGGCAATTCTTAAGGGTCTTTAA |
|
Protein Sequence
|
MRSSSPSKAHSTQVPIKVQHRLAKKGTRRRRVDLPCGCSYFIALACHNHGFTHSGTHQSFSSREWRVYLGDSKSPVFQDNRTQQPAISYERGHHHRPNTVQLQPEESVGDTQVFSSLPNLDDFTASDWAILKGL |
|
NCBI Accession
|
NP_598190.1
|
|
Location
|
1512-2597 |
|
Gene Name
|
Rep |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGGCAGCCCCGAATCGGTTAAAAATAAATGCCAAAAATTATTTTCTCACTTATCCCAAGTGCTCCCTTACTAAAGAAGAGGCACTTTCCCAATTATTAAATCTCCAACCCCCAACAAACAAAAAATACATCAAGATCTGCAGAGAACTACACGAAGATGGGAGCCCTCATCTCCATGTGCTCATCCAGTTCGAAGGGAAATATCAGTGCAAGAATCAACGATTCTTCGACCTGGTCTCCCCAAACAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCACCGACGTCAAGTCCTACATCGACAAGGACGGAGACACCCTCGAATGGGGAGAGTTCCAGATCGATGGGAGATCTGCACGAGGAGGTCAACAGACAGCTAATGATGCTGCTGCAGAAGCCCTAAATGCAGGTTCTAAAGAAGCTGCAATGGCTATAATAAAGGAGAAACTCCCAGAAAAATTTATTTTTCAATATCATAATTTAAATTCTAATTTAGATAGGATTTTTACTCCTCCGTTGGAGGTTTATGTTTCGCCTTTTTTATCTTCTTCTTTTGATCAAGTTCCTGAAGAACTTGAAGAATGGGTCTCAGAAAATGTCATGAATGCCGCTGCGCGGCCTCTGAGGCCTCAAAGTATAGTAATTGAGGGAGACAGTCGTACGGGTAAAACGATGTGGGCTAGGTCATTAGGGCCTCATAATTACCTATGCGGTCATTTAGATCTAAGCCCCAAAGTTTACAGCAATGATGCGTGGTATAACATCATCGATGACGTAGATCCTCACTACCTAAAGCACTTTAAGGAATTCATGGGGGCCCAAAGGGACTGGCAATCAAATACCAAGTACGGAAAGCCAGTTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCTAATTCAAGTTATAAAGAGTTCTTGGATGAAGAGAAGAATAATGCTCTCAAAAATTGGGCTTTAAAGAATGCGATCTTCGTCACCCTCGAAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAGCACAGGCTAGCCAAGAAGGGGACGAGGCGTCGACGTGTTGA |
|
Protein Sequence
|
MAAPNRLKINAKNYFLTYPKCSLTKEEALSQLLNLQPPTNKKYIKICRELHEDGSPHLHVLIQFEGKYQCKNQRFFDLVSPNRSAHFHPNIQGAKSSTDVKSYIDKDGDTLEWGEFQIDGRSARGGQQTANDAAAEALNAGSKEAAMAIIKEKLPEKFIFQYHNLNSNLDRIFTPPLEVYVSPFLSSSFDQVPEELEEWVSENVMNAAARPLRPQSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNIIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNNALKNWALKNAIFVTLEGPLYSGSNQSAAQASQEGDEASTC |
|
NCBI Accession
|
NP_598191.1
|
|
Location
|
2183-2440 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGAGCCCTCATCTCCATGTGCTCATCCAGTTCGAAGGGAAATATCAGTGCAAGAATCAACGATTCTTCGACCTGGTCTCCCCAAACAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCACCGACGTCAAGTCCTACATCGACAAGGACGGAGACACCCTCGAATGGGGAGAGTTCCAGATCGATGGGAGATCTGCACGAGGAGGTCAACAGACAGCTAATGATGCTGCTGCAGAAGCCCTAA |
|
Protein Sequence
|
MGALISMCSSSSKGNISARINDSSTWSPQTGQHISIRTFRELNPAPTSSPTSTRTETPSNGESSRSMGDLHEEVNRQLMMLLQKP |